Об nxQL
2014-12-22
Вышел PostgreSQL 9.4, где фичей №1 заявлен товый тип данных jsonb, по которыму можно строить индексы и делать эффективные запросы внутренностей JSON документа. Теперь вопрос: «Зачем нужна Монга, если JSON можно хранить в Постгресе?» — будут задавать не только шепотом на кухне. Попробую на этот вопрос неответить.
Появление jsonb перечеркивает мои предыдущие тыкания в JSON в PostgreSQL. Если json — это просто строка, которая требует парсинга для каждого обращения к её внутренностям, то jsonb — это некие бинарные данные (как я понимаю, родственные типу hstore), поддерживающие прямой доступ и индексацию. В общем, jsonb — это сильно быстрее, и это гораздо ближе к BSON в Монге. Цель одинаковая — бинарный формат вместо человекочитаемого текста для повышения эффективности доступа.
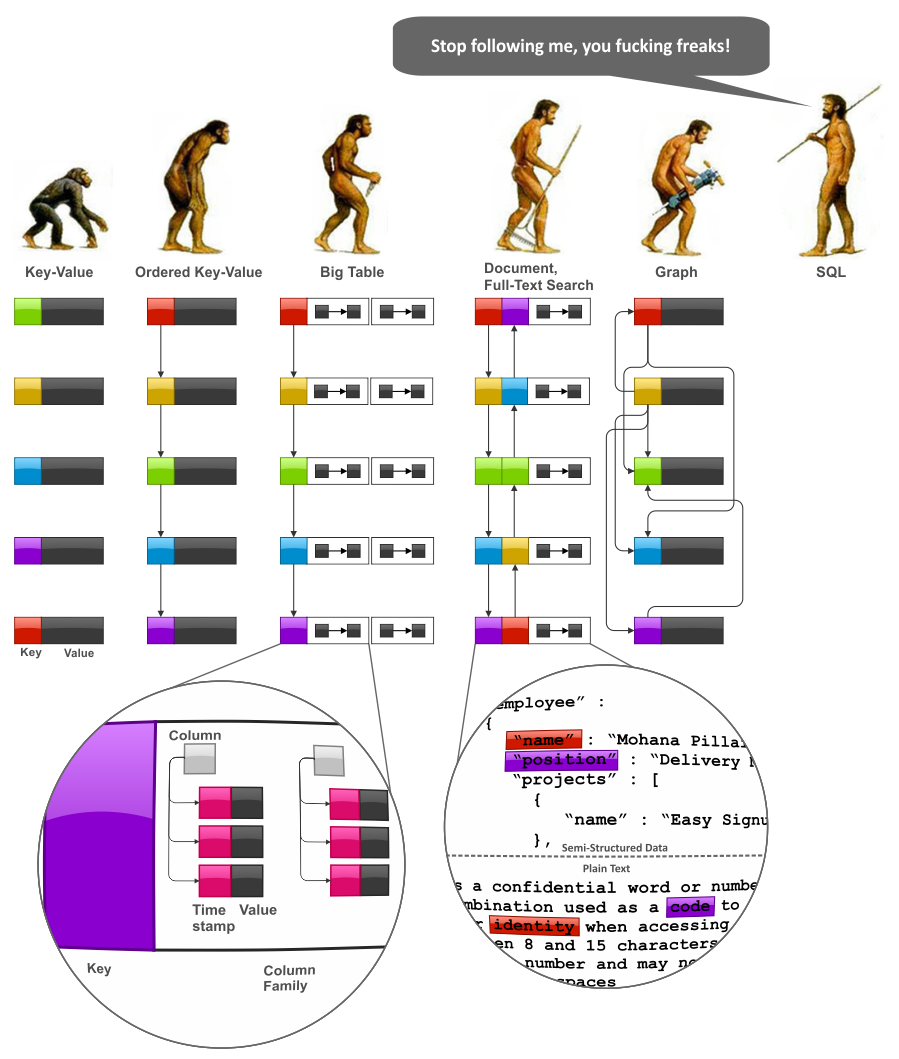
Зачем вообще нужно хранить JSON в реляционной базе? Ведь реляционная модель вполне прекрасно может отображать иерархические данные, как в JSON документе. У меня только один ответ — schemaless. Да, та самая бессхемность, которой гордятся NoSQL, внезапно пригодилась в SQL.
На самом деле не так уж и внезапно. Блобы были почти всегда. XMLи закидывать в БД научились давным давно. Теперь же очередь дошла до модного молодежного JSON. Если мы храним его в нереляционной БД, то говорим о документо-ориентированных NoSQL. Если мы храним его в реляционной БД, то говорим о специальном типе данных, который можно вставить в колонку таблицы.
Сложность, жесткость, вредность схемы данных, пожалуй, сильно преувеличена. Всякие Хибернейты или Активрекорды прекрасно прячут эту самую схему от разработчика. Разработчик работает с объектами. Как они сохраняются в базу, уже проблема фреймворка. (Где вы, объектные БД?) Даже проблему миграции, за что не любят схемы, фреймворк может решить.
Другой пример — Кассандра. Не думайте, что NoSQL — это обязательно schemaless. С самого начала в Кассандре была схема, нужно было указать имена и типы данных в колонках. Но это ничуть не мешало вам вставить в строку еще полтора миллиарда колонок с другими именами и произвольными данными. Просто вам самим пришлось бы определяться с типами значений при извлечении. Но в Кассандре 2.0, с появлением CQL 3 все изменилось. Теперь вы обязаны объявлять таблицы заранее. И только после этого делать к ним запросы. В синтаксисе, пугающе похожем на SQL. А динамические данные можно выразить как списки, множества или мапы в качестве значения ячейки таблицы. Как в SQL. Жду, кто сделает еще полшага и позволит сохранять и JSON документы, которые, вообще-то, почти как мапы.

Так чем лучше Монга? Масштабируемостью. Совсем чуть-чуть поплясав с бубном, можно собрать большуший, да еще и географически распределенный кластер, в котором можно хранить все ваши любимые BigData. Ну конечно, еще нужно правильно организовать данные и выбрать ключ шардинга. Такой возможности искаропки у Постгреса нет.
Но какие-то возможности для масштабирования у Постгреса есть. Во-первых, штатная репликация весьма хороша. К тому же, в Постгресе 9.4 её еще улучшили и теперь возможно делать мультимастера. Так, чтобы несколько серверов выступали мастером для разных таблиц (например, по признаку географического местонахождения пользователя), а слейвы имели бы копию таблиц с мастеров. Уже неплохо.
А еще есть Postgres-XC, который умер и родил более свежий Postgres-XL. Это полноценный кластер, построенный поверх модифицированного PostgreSQL. Это не решение искаропки. Это надстройка. Но она делает то, что делает. Решает те же проблемы, что решают многочисленные NewSQL. Пытаются сохранить реляционную модель и SQL как язык запросов, но при этом хорошо отмасштабироваться. И натыкаются на те же самые решения вроде выпиливания единой точки отказа, координации распределенных транзакций, эффективного объединения данных, раскиданных под разным узлам кластера. Последнее, как всегда, нормально работает только если мы правильно выберем ключ шардинга, и в запросе будем его указывать.

А еще Postgres-XL выглядит чертовски сложным в развертывании и настройке. Уж больно много в него входит разных компонент, которые должны работать вместе. Танцев с бубнами предвидится сильно больше, чем в случае Монги. Это напоминает HBase, который сам по себе является надстройкой над Hadoop. А Hadoop, в свою очередь, тоже не так прост. Поэтому теперь уже никто в здравом уме не скачивает HBase с серверов Апача, а берут сборку от Cloudera.
Базы данных становятся настолько сложны, что уже состоят не из одного, а из нескольких продуктов. К нашему счастью, в основном открытых. И координировать эти продукты становится все сложнее. Всякие облака да Докеры тут как нельзя кстати. Вангую, что вскоре все эти наши БД будут поставляться только в виде готовых настроенных образов, а не отдельных пакетов для ОС. Управление конфигурацией становится затратнее собственно разработки.

А вот вам еще одна тенденция. В старой Кассандре обращение к БД происходило через строгое API посредством Thrift. На каждую операцию, будь то получение всей строки по ключу или получение набора колонок по ключу и т.п., рисовался свой RPC вызов, на сервере и на клиенте. А в новой Кассандре есть CQL. Язык запросов. По внешнему виду и по назначению аналогичный SQL. И остается только один вызов в API — выполнение этого CQL. И если будет добавлена какая-то новая фича, будет расширен язык запросов, но не API или протокол, или клиентский код.
Еще более занятен пример графовых БД. Появились они вроде совсем недавно, но успели обзавестись и общим API: Blueprints, и своим специальным языком запросов: Gremlin. Полагаю, что для сохранения конкурентного преимущества, Монге нужно срочно изобрести стандартный язык запросов для документо-ориентированных данных :)
Забавно, что переводить SQL в запросы к Монге уже научились. С другой стороны, тот же LINQ давно имеет API для конструирования правильных SQL запросов. Становится почти без разницы, работать через API или через язык запросов.
Итак. Сочетание заранее определенной схемы и динамических данных — да. Горизонтальное масштабирование и кластеризация — да. Возникновение стандартных языков запросов в дополнение к API — да. Поставка готовых образов для развертывания в облаках — да. Это то, что происходило, происходит и будет происходить в ближайшем будущем среди систем хранения структурированных данных, будь то NoSQL, SQL или NewSQL. И я нарекаю это nxQL.