О JSON в PostgreSQL
2013-11-24
Как известно, в последних версиях PostgreSQL появилась поддержка JSON. Соответствующий тип данных появился в версии 9.2. Набор функций для работы с JSON был существенно расширен в версии 9.3.

В связи с этим, а также потому что у нас JSON используется для передачи данных по сети, возник соблазн воспользоваться новым типом данных для того, чтобы сэкономить на сериализации реляционных данных. Еще раз, данные — преимущественно реляционные, мы их сериализуем в JSON каждый раз для передачи по сети. Вопрос: целесообразно ли хранить уже сериализованные данные в JSON поле (конечно же в ущерб удобству модификации этих данных)?
Еще в списке функций для работы с JSON соблазнительной выглядит
row_to_json(),
которая может представлять строку обычной таблицы (или выборки)
в виде "плоского" JSON документа,
содержащего поля одного уровня вложенности
согласно колонкам результата.
Примерно такого документа:
{ "column1" : value1, "column2" : value2 }
Чтобы проверить возможности PostgreSQL я написал простенький тест. Вот такие получились результаты для PostgreSQL 9.3 на моем локалхосте:
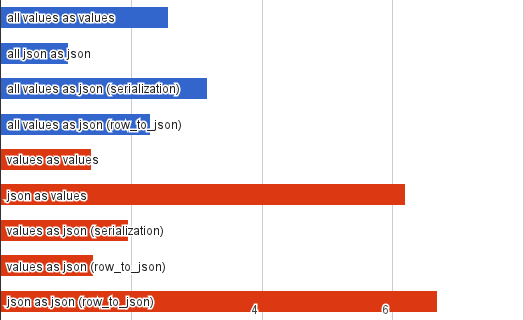
Я просто сгенерировал 100 тысяч строк
с десятью текстовыми колонками
по 100 байт случайных символов,
а также 100 тысяч аналогичных JSON документов
(в отдельной таблице)
и пытался выбирать эти строки и документы различными способами.
Я делал просто SELECT *,
я просто выбирал JSON документ целиком,
я делал ручную сериализацию,
я преобразовывал реляционные строки в JSON
с помощью row_to_json().
Я повторил это для половины всех колонок и полей JSON документа
(красные полоски).
Быстрее всего оказалось просто извлечь JSON документ.
Однако извлечь половину полей получалось значительно медленнее,
позже объясню почему.
Удивительно,
что получение реляционной строки через row_to_json()
практически идентично по времени
с получением этих данных напрямую.
Это значит,
что если вас устраивает примитивный "плоский" JSON,
то использование row_to_json()
(т.е. сериализация на стороне PostgreSQL)
может быть хорошим решением.
Ну и сериализация в JSON на клиентской стороне
— не так уж и медленна
(я использовал Python, не самый быстрый вариант).
Я, конечно, не удержался и повторил эксперимент в MongoDB.
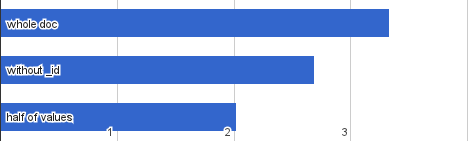
Монга слегка подпортила мне набор данных тем,
что добавила _id ко всем документам.
Еще (как минимум в Python) оказалось,
что документ,
возвращаемый драйвером Монги
— вовсе не JSON,
и его нужно явно сериализовать.
Зато Монге не требуется титанических усилий,
чтобы извлечь часть полей из документа.
Так почему же PostgreSQL такой медленный,
когда приходится делать "срезы" JSON?
Посмотрите еще раз на
список
функций и операций над JSON.
Здесь есть извлечение значений отдельных полей
(причем можно сразу в виде текста).
Есть преобразование в другие типы.
Есть возможность извлечь поле вложенного документа.
Но нет ничего, чтобы сделать "срез".
В результате приходится извлекать по отдельности n полей
и затем склеивать их в новый JSON.
И, судя по этому графику,
извлечение поля — весьма затратная операция.
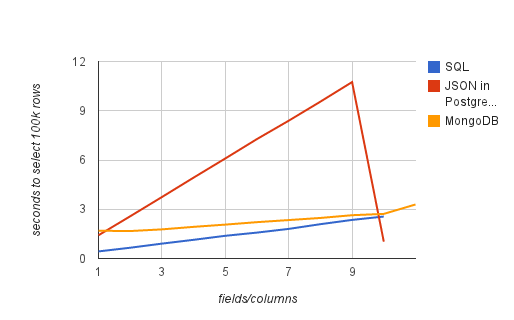
Я замерил время выборки 100 тысяц строк с различным числом колонок/полей: из обычной SQL таблицы, из JSON документа, хранящегося в PostgreSQL, из MongoDB.
В общем, PostgreSQL — это вам не MongoDB. JSON здесь — лишь CLOB с проверкой синтаксиса. И использовать его нужно целиком, "как есть". Есть, конечно, операции доступа к внутренностям этого CLOB, но они довольно дороги. И (в отличие от Монги) совсем нет операций для модификации JSON документа "на месте". Ну вы поняли.
Для себя мы остановились на обычных SQL таблицах
и, по возможности, использовании row_to_json().