Об организации
2024-01-06
Об организации кода. Code layout.
Попадается тебе проект, которому лет 10.
Открываешь его.
И что ты видишь?
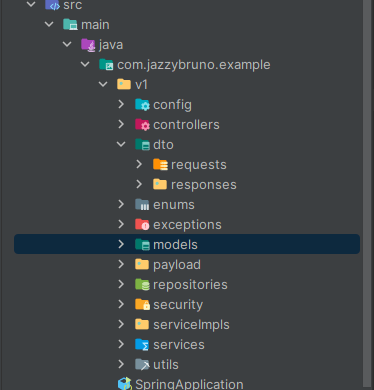
config, dto, integration, model, rest, вездесущий util.
Какие-то части веб приложения?
Ну так мы и до этого знали, что это веб приложение.
Что оно делает-то?
Если копнуть глубже, появляется какое-то понимание:
dtoauditcampaignfeeinvoice- ...
modelauditcampaigninvoice- ...
restauditcampaigninvoice- ...
И тут, допустим, прилетает задача. Отчёты по аудиту стали слишком тяжёлыми. А нужны они только аудиторам. Надо бы вынести их на другой сервер, чтобы не мешали остальным пользователям пользоваться приложением.
Но ведь у нас монолит. Как это, вынести на другой сервер?
Наверное, стоит выделить наши dto.audit, model.audit, rest.audit
и, наверняка, еще с десяток разных *.audit
в отдельное приложение.
Наверняка окажется, что оно всё зависит от пары-тройки различных util.
И ещё от чего-нибудь.
Если вы хорошо писали код, стараясь минимизировать зависимости и вообще старались следовать SOLID, то, скорее всего, у вас получится. Но было бы значительно проще, если бы весь код, относящийся к аудиту, не был бы размазан ровным слоем по всему проекту. А был бы в своём пакете, в своей отдельной папочке.
А если у вас монолит действительно сильно монолитный,
то, возможно,
вам придётся просто взять ваш монолит как есть,
и просто запустить ещё одну копию на другом сервере.
Пусть там используется только audit часть.
Грязно? А то!
Откуда берётся эта мода группировать файлы исходного кода по выполняемым им техническим функциям, а не по бизнес функциям?
Полагаю, потому что слишком многие туториалы для начинающих либо вообще не подымают тему организации исходного кода, либо предлагают группировку по архитектурным слоям как единственный возможный вариант. Сходу нагуглил: 1, 2. И слишком часто это называют Best Practices.
Популярные веб фреймворки на других языках, например, Django или Laravel, или даже руководства по MVC для Go, тоже напирают на различия в архитектурной роли различных компонентов. И предлагают в обязательном порядке группировать их по этому признаку. И либо игнорируют бизнес роль компонентов. Либо предлагают группировать по смыслу лишь как второй вариант размещения файлов исходного кода.
Я призываю группировать по фичам, бизнес функциям. Всё равно делить (на микросервисы, ага) придётся поперёк слоёв, чтобы в каждом (микро)сервисе остались все слои. Так давайте же сразу складывать всё так, чтобы потом удобнее было бы пилить. А пилить потом всё равно придётся. Рано или поздно, так или иначе.
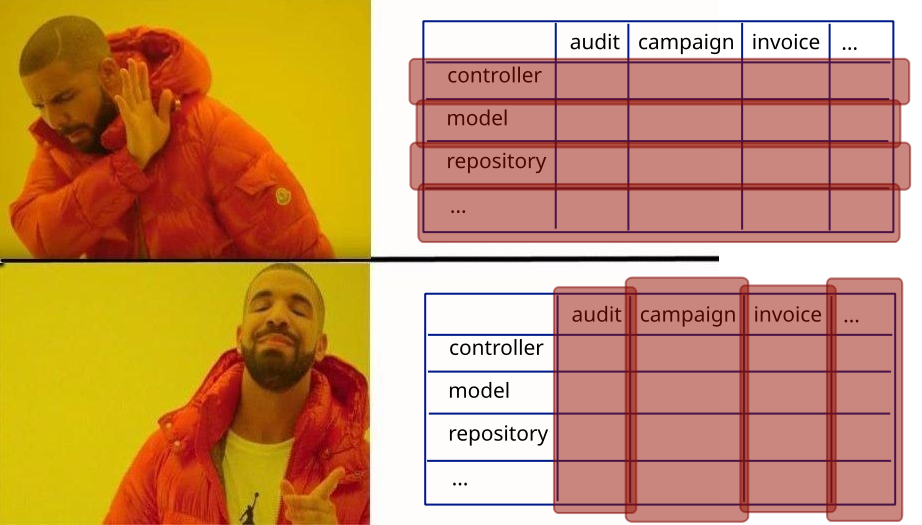
Делайте вот так:
auditdtomodelrest
campaigndtomodelrest
feedto
invoicedtomodelrest
util- ...
Тогда и разделить будет проще. В том числе и потому, что вы, возможно, инстинктивно постараетесь уменьшить зависимости между разными частями приложения.
В идеале зависимостей между разными фичами вообще быть не должно.
Могут быть зависимости от util.
Ну что ж, на то он и утиль, чтобы предоставлять какие-то мелкие сервисы всем.
Для начала пусть будет отдельным пакетом.
А потом подумайте выделить его в отдельную библиотеку или модуль.
Один приватный модуль с дурацким названием shared всё же лучше,
чем дублирование кода.
В чём-то это противопоставление похоже на размещение софта в файловой системе.
Есть Filesystem Hierarchy Standard (FHS)
для Unix систем.
Где исполняемые файлы кладутся в /bin, настройки в /etc, а изменяемые файлы в /var
(логи в /var/log).
Соображение тут в том,
что разные типы файлов требуют разного места на диске, разной скорости доступа, разной надёжности хранения.
И удобнее примонтировать разные виды файловых систем поближе к корню,
и совместно использовать их разными приложениями.
Но, ручной контроль того, какая программа куда что положила,
становится почти невозможным.
Контролируют это с помощью различных пакетных менеджеров.
Которые следят, что куда складывается,
и подчищают нужные файлы при удалении софта.
С другой стороны, в Windows принято, чтобы каждая программа всё тащила с собой. А в Mac каждая программа — это вообще маленький образ диска. В этих ОС программы свои настройки хранят централизованно (реестр Windows), и логи тоже пишут централизованно. Не через файлы, а через сервисы операционной системы.
P.S. Не я один так считаю. Что исходный код надо организовывать по фичам (by feature), а не по слоям (by layer).