О Redshift
2021-11-05
О ClickHouse я уже рассказывал. А о Redshift как-то позабыл. Вспомнил, когда пришлось рассказывать о них на конференции. Здесь — краткий пересказ.
Redshift — это аналитическая база данных, живущая в облаке AWS. Это проприетарная БД. Вы не можете её запустить где-то локально в Докере. Только в Амазоне.
Redshift — не оригинальная разработка Амазона. Это продукт компании ParAccel. Они лет шесть пилили свою уникальную аналитическую БД на основе PostgreSQL 8. И в 2011 году выпустили ParAccel Analytic Database. В 2012 этот продукт адаптировал Амазон под своё облако. В публичную эксплуатацию Redshift вышел в начале 2013. А мы на проекте начали его использовать в начале 2020. Redshift к этому моменту явно был зрелым продуктом.
Я думал, ClickHouse значительно моложе. Но нет, он моложе лишь на годик. ClickHouse использовался в Яндекс.Метрике уже в 2012.
Redshift, как и ClickHouse, — колоночная СУБД. То есть она хранит данные не по строкам, как тот же Postgres, а по колонкам. В результате, так как в одной колонке присутствуют однородные данные, данные получается эффективно сжимать при хранении на диске. Очень эффективно. В частности, этим колоночные БД хороши.
Redshift — распределённая БД. Кластер Redshift состоит из нескольких узлов, расположенных в одном регионе AWS. На каждом узле запущено несколько слайсов (slices) — процессов БД. Как правило, по числу ядер CPU.
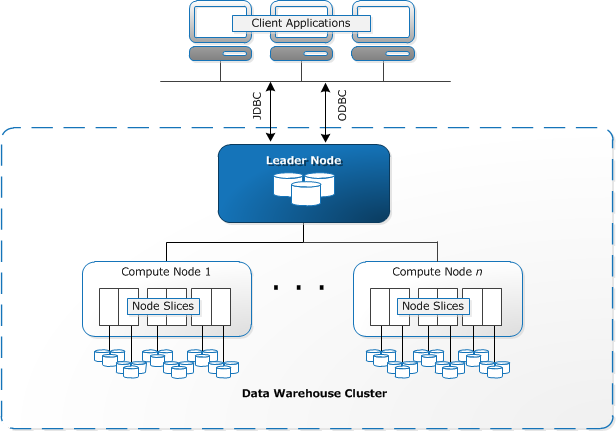
Redshift, как и ClickHouse, — поддерживает SQL. Слава богу, никакой поддержки конкретных стандартов SQL не декларируется. И правильно, SQL в этих колоночных БД весьма специфичный.
Redshift позиционируется как БД для операционной аналитики в реальном времени. Того, что называется OLAP (Online analytical processing) и BI (Business intelligence). Куча данных забивается в большую БД с поддержкой SQL. Аналитик эти данные как-то вертит. А потом всё грохается. Очень похоже на типичный юзкейс для Redshift.
Redshift поддерживает SQL. И этот SQL на 70% совпадает с SQL PostgreSQL 8. Что неудивительно.
В Redshift есть транзакции.
С единственным
уровнем изоляции serializable.
Сделано это через
read-write lock
на уровне таблиц.
Что,
с одной стороны,
— хорошо.
Потому что это действительно честные транзакции.
А с другой стороны — плохо.
Ибо порождает серьёзные проблемы с производительностью
конкурентных запросов.
Даже сам уровень конкурентности в кластере
Redshift (размер очереди транзакций)
не может превышать пятидесяти.
В ClickHouse, напомню,
вообще нет транзакций.
Все асинхронно и eventually.
Также в ClickHouse нет честных
(с немедленным эффектом)
UPDATE и DELETE.
Впрочем, существующего
ALTER DELETE
вполне достаточно,
чтобы удовлетворить
GDPR.
На вход в Redshift у нас на проекте поступают данные из бид-реквестов OpenRTB. Метка времени, айдишники, цены, множители... Порядка 19 колонок сейчас. Плюс ещё разнообразные уведомления, которые вставляются в ещё 11 таблиц. Порядка 300 тысяч запросов в минуту.
В ClickHouse, на другом проекте, мы складываем DNS запросы. Их на порядок меньше — порядка 30 тысяч в минуту.
Из Redshiftа мы извлекаем в основном отчёты. Сколько всего, в штуках и в деньгах, было потрачено. С группировкой по разным параметрам и временным интервалам. Тут встречаются джойны с несколькими другими таблицами. Чтобы прилепить сюда и курсы валют, и наличие разных уведомлений. И ещё извлекаем немного статистики по входящим запросам, например, общий размер аудитории. Ну и делаем совершенно произвольные запросы в Redshift для проверки соответствия данных в разных системах. RTB — это есть взаимодействие множества разных систем. И часто нужно сверять данные.
В итоге мы в Redshift имеем,
в той самой большой таблице с бид-реквестами,
больше 7 миллиардов записей.
И то, мы храним данные лишь где-то за последний месяц.
Это порядка 370 гигабайт на диске.
Всё это умещается в кластер
из 4 не самых больших узлов типа dc2.large,
с 2 vCPU и 15 гигабайтами памяти на борту каждого.
И стоит это удовольствие порядка $850 в месяц.
Недёшево.
ClickHouse другого проекта на обычных виртуалках умещается на 6 узлах о 8 гигабайтах памяти на каждом. За $240 в месяц. И это за 195 гигабайт живых данных. За полгода. В два раза меньше данных за в три раза меньше денег. Тоже недёшево.
Типы данных.
В Redshift они обычные SQLные,
унаследованные от PostgreSQL.
Даже какой-то GEOMETRY завезли.
А вот ARRAY почему-то нет.
Из-за отсутствия ARRAY нам приходится хранить чуть больше строк,
чем можно было бы.
ClickHouse на типы данных побогаче.
Тут совершенно не следуют SQL традиции,
в том числе и в их наименовании.
Есть enumы.
Есть сложные типы, вроде тех же массивов,
кортежей и даже что-то типа объектов (вложенные типы вроде мапы).
Из целочисленных мне нравится UInt256.
Буду мутить с блокчейнами,
буду его использовать.
Ибо в Ethereum везде сплошной uint256.
Redshift и ClickHouse умеют здорово сжимать данные. Это одно из важных преимуществ колоночных БД. Из универсальных поддерживаются весьма эффективные и модерновые алгоритмы сжатия: LZO и ZSTD. В ClickHouse можно задать уровень сжатия.
Гораздо более интересны специализированные алгоритмы.
BYTEDICT превращает строки в enumы,
которых в Redshift нет.
Если у вас не более 256 уникальных значений,
на каждую запись будет отведён лишь один байт.
Плюс словарь значений, конечно же.
MOSTLY8, MOSTLY16, MOSTLY32 хранит целочисленные значения
более короткими числами,
чем предусмотрено в обычном SQL от Postgres.
Плохо то,
что по умолчанию Redshift предлагает вовсе не самые оптимальные алгоритмы сжатия.
Вероятно, потому,
что новые алгоритмы добавлялись позднее,
и они не хотели ломать обратную совместимость.
И даже ANALYZE COMPRESSION
недостаточно вникает в структуру данных,
и тоже предлагает не самый лучший вариант.
На практике лучше всего сжимает ZSTD,
и строки, и вещественные числа.
Для целых чисел, в зависимости от диапазона значений,
стоит выбрать какой-нибудь MOSTLY*.
Для строк, которые на самом деле enum,
обязательно выбирайте BYTEDICT.
И да, sort key сжимать нельзя.
В Redshift тщательно выбирайте алгоритм сжатия сразу при создании таблицы. Поменять его потом может оказаться не так уж и просто. В худшем случае придётся создавать, копировать и переименовывать колонки.
Собственно, о sort key.
Во всех колоночных БД нет привычных индексов,
которые можно почти в любой момент создать по любым колонкам.
Есть лишь два ключа.
DISTSTYLE/DISTKEY в Redshift,
и аналогичный по смыслу PARTITION BY в ClickHouse
— отвечают за физическое распределение записей.
И SORTKEY и ORDER BY — ключ сортировки.
DISTSTYLE
в Redshift отвечает за то,
как строки будут распределяться между узлами кластера (точнее, слайсами).
AUTO — БД сама решит (не надо так делать).
EVEN — строки будут размазаны псевдослучайно-равномерно.
ALL — данная таблица будет присутствовать на каждом узле кластера,
что может быть полезно для небольших таблиц-справочников.
KEY — распределение по DISTKEY,
явно выбранной колонке.
Строки с одинаковыми значениями в этой колонке
будут располагаться в одном слайсе.
Это полезно для эффективного джойна по этой колонке.
К сожалению,
DISTKEY может указывать лишь на одну колонку.
Если такой удобной колонки,
по которой можно всё джойнить,
у вас нет,
придётся довольствоваться DISTSTYLE EVEN.
PARTITION BY
в ClickHouse хоть и похож по сути,
имеет совершенно другой смысл.
Это выражение,
по которому записи в таблице будут объединяться в партиции.
На каждом узле кластера.
Произвольное выражение,
но в первых версиях ClickHouse
ключ партицирования всегда неявно соответствовал toYYYYMM(eventDate),
то есть год и месяц колонки типа Date.
Партиции в ClickHouse
можно
очень быстро отцепить, удалить,
перенести на другой узел и прицепить там.
Ключ сортировки
в обеих БД
это именно что
ключ сортировки.
Данные на диске будут отсортированы именно по этому ключу.
Этот ключ может быть составным,
из нескольких колонок.
Соответственно,
поиск по любому префиксу этого ключа будет значительно быстрее.
Поэтому ключ сортировки крайне желательно
включать в условие WHERE любого запроса.
Иначе БД будет вынуждена просканировать всю таблицу,
что, очевидно, медленнее.
Впрочем,
помните,
что это колоночная БД.
Чем меньше колонок участвует в запросе,
тем быстрее.
Просканировать одну колонку,
в общем-то,
не так уж и долго.
В ClickHouse, кроме того, индекс по ключу сортировки — разреженный. Это значит, что в индексе хранится адрес не каждой строки, а, допустим, каждой восьмитысячной строки. Это значительно уменьшает размер самого индекса. Но снижает эффективность запросов, которым нужно извлечь лишь несколько строк.
О, внешние БД. К Redshift и ClickHouse можно подключать внешние таблицы или даже целые базы данных. Из PostgreSQL или MySQL. Или даже из произвольных БД, доступных через JDBC или ODBC, в случае ClickHouse. И к этим внешним таблицам можно будет делать джойны. Может быть очень удобно хранить там длинные справочники, например.
Redshift, кроме того, может делать запросы напрямую к файлам, которые хранятся в S3. Это называется Redshift Spectrum. Это могут быть как «простые текстовые» файлы, типа CSV, так и более сложные форматы вроде JSON, или даже специальные форматы, хранящие данные в колонках, такие как Parquet. То есть вы просто складываете правильные файлы правильным образом в S3, а потом делаете SQL запросы по ним из Redshift.
А ещё Redshift может загружать и выгружать данные
в/из кучи разных источников.
Это делается командами
COPY
(загрузка) и
UNLOAD (выгрузка).
Можно загружать/выгружать из того же S3,
из DynamoDB,
из EMR
(Elastic Map Reduce, то есть из разных хадупов),
и даже с удалённого сервера по SSH.
А в ClickHouse есть словари. Это наборы ключей и связанных значений, которые хранятся (как правило) в памяти узлов и могут загружаться и обновляться из внешних источников. Опять-таки, идеальное решение для справочников (не сильно больших).
И Redshift, и ClickHouse — распределённые системы. А значит, они могут масштабироваться.
В Redshift всё сводится к изменению размеров и характеристик кластера. А сам кластер всегда живёт в одном регионе AWS. Можно менять количество и размеры узлов, а также управлять размером хранилища.
В простейшем случае кластер Redshift может состоять из одного узла. Впрочем, даже самый маленький узелочек будем вам стоить $160 в месяц. В single-node кластере действительно лишь один инстанс. Тут нет лидера. Несколько другая архитектура получается. Поэтому добавить ещё узлов без простоя не получится.
А в multi-node кластере, помимо узлов, которые хранят и обрабатывают данные, появляется ещё leader node. Через него проходят все запросы, и он ещё высчитывает некоторые финальные агрегаты.
Узлы можно выбирать разных размеров. И есть ещё два разных типа. DC2 узлы хранят данные исключительно на локальных SSD дисках. Больше узлов — больше места для данных в кластере. А RA3 узлы могут прозрачно вытеснять данные во внешнее хранилище. Снова S3. В этом случае объём хранилища почти не ограничен. А вы платите столько, сколько храните.
В ClickHouse всё ближе к NoSQL. Здесь кластер — это шарды реплик. Данные разбиваются на шарды. Причём Кликхаусу почти пофигу, как вы разбиваете данные. Можно просто прямо вставлять в тот шард, куда удобнее, например, ближе географически. Когда будут делаться запросы, всё равно будут опрошены все шарды. А сами шарды могут быть разных размеров и производительности. Только вот время выполнения запроса будет определяться скоростью самого медленного шарда.
А сами шарды могут состоять из нескольких реплик. Причём наличие реплик ускоряет и чтение, и запись. Поскольку репликация асинхронная, а писать можно в любую реплику. Другие реплики просто рано или поздно подсосут себе отсутствующие данные.
Redshift для общения по сети использует протокол PostgreSQL 8. Поэтому все инструменты работы с Postgres могут к нему подключиться (но не все они будут одинаково полезны в отношении Redshift).
У ClickHouse есть аж два сетевых протокола.
Свой бинарный протокол,
который используется для общения узлов кластера между собой,
а также в родном CLI клиенте
clickhouse-client.
И HTTP протокол.
Запросы можно засылать прямо curlом.
JDBC драйвер. К Redshift можно подключиться и Postgres драйвером. Только последние версии этого драйвера ругаются ворнингами, что PostgreSQL 8 — это слишком старая версия сервера, которая скоро перестанет поддерживаться.
А ещё у Redshift есть свои JDBC драйвера. Аж двух версий. Версии 1.x крайне не рекомендую к использованию. Они глючат. А версии 2.x — открыты, и проблем с ними не замечено.
У ClickHouse свой JDBC драйвер. Он, почему-то, подключается через HTTP. Он работает.
Материализованные представления.
Они есть и там и там.
Нам они очень понравилось в ClickHouse.
Потому что там их можно использовать вместе со
-State
агрегатными функциями и движком
AggregatingMergeTree.
В результате у вас получаются
автоматически обновляемые агрегаты,
сворачивающие исходные данные в несколько раз.
При этом сами исходные данные можно потом и удалить
(когда партиция заполнится).
В Redshift materialized views самые обычные.
И их нужно руками обновлять
командой
REFRESH MATERIALIZED VIEW.
Самое интересное. Как вставлять 300k строк в минуту. В Redshift пришлось знатно помучиться.
Мама же учила вас всегда использовать
prepared statement?
Ну хотя бы для того,
чтобы избежать
SQL инъекций.
Так вот,
у разработчиков Redshift,
ну или как минимум у разработчиков её JDBC драйвера,
были другие мамы.
Использовать PreparedStatement для быстрой вставки в Redshift
у вас не получится.
Не знаю почему,
но каждый INSERT через PreparedStatement
занимает не менее двух секунд.
И батчи не помогают.
Так что забываем про правильную вставку.
Рекомендуемый способ быстрой вставки в Redshift
— это multi-row insert.
Это когда в одном выражении INSERT вы указываете сразу много строк для вставки.
Как-то так: INSERT INTO... VALUES (...), (...), ....
Такую строку придётся собрать самостоятельно.
И она может быть длиной до 16 мегабайт.
Да, пришлось сделать это руками.
Хорошо, что во входных данных нет произвольного пользовательского ввода,
только цифры да айдишники,
можно надеяться,
что примитивного экранирования будет достаточно.
Но даже этого недостаточно
для 300k вставок в минуту.
Ещё более рекомендуемый способ — делать
COPY из S3.
То есть вы буквально пишете в S3 файлы.
Например, |-separated,
с разделителем в виде символа «|».
Такой формат предполагает Redshift по умолчанию.
Файлов должно быть больше,
чем слайсов в кластере Redshift.
А потом делаете COPY.
И эта единственная команда COPY за те же самые две секунды
всасывает все эти данные.
Магия.
Они называют это массивно-параллельной обработкой.
Каждый слайс обрабатывает часть всех файлов.
Именно поэтому файлов должно быть много.
Да, это очень странно. Но да, через S3 уже можно вставить 300k записей в минуту.
Хотя мы уже думаем, что, раз уж эти данные уже есть в S3, и, на самом деле, эти данные нужны не сильно часто, они не входят в те постоянные отчёты, что делают пользователи, может, пусть они и лежат в S3. А запросы, если понадобится, можно делать и через Redshift Spectrum.
В ClickHouse проблем со вставкой нет.
Батчи JDBC, и PreparedStatement работают прекрасно.
Рекомендуются батчи не менее 1000 строк
и вставка не чаще раза в секунду.
Конечно, остаётся проблема того, как этот самый батч создать. Его же надо где-то накопить. В памяти, в очереди. Где-то надо. И, как всегда, есть риск либо потерять какой-нибудь кусок данных, либо вставить более одного раза.
SQL в Redshift скучен.
Самый обычный SQL.
Хотя вполне нормально поддерживаются common table expression
(CTE).
Те самые запросы с WITH.
Это радует.
А в ClickHouse есть несколько уникальных плюшек.
Можно считать агрегаты не по всем строкам,
а по некоторому подмножеству строк,
приближённые агрегаты,
с помощью SAMPLE.
Можно оптимизировать выполнение запроса,
сначала анализируя только колонки с условиями выборки,
а лишь затем извлекая данные из остальных колонок,
с помощью PREWHERE.
Можно сразу формировать строку «итого» при группировке,
с помощью WITH TOTALS.
В ClickHouse встроено громадное количество всяких разных интересных функций агрегации. Разнообразные квантили, стандартные отклонения и прочие прелести на радость статистикам.
Redshift из коробки не выходит за рамки обычных для SQL агрегатов. Но тут можно писать UDF (user defined functions). На SQL или Python. Или даже запускаемые на Lambda. Также можно писать хранимые процедуры на PL/pgSQL. Интересно, существуют ли библиотеки статистических функций, чтобы хоть чуть-чуть приблизиться к ClickHouse?
Ну и, наконец, проблемы.
Не используйте JDBC драйвер для Redshift версии 1.x. У нас он приводил к зависаниям на пару минут при каждом открытии подключения к Redshift. Только при запуске внутри AWS. Только если в classpath при этом присутствовал и драйвер PostgreSQL. Этот же драйвер периодически вызывал странные ошибки в DataGrip. То колонки с таймстампами не отображаются. То вообще не получается стянуть схему БД. С драйвером версии 2.x проблем не замечено.
С конкурентностью у Redshift всё плохо. Транзакции сделаны через блокировку на уровне таблиц. А это значит, что те самые вставки кучи строк и тяжёлые выборки по одним и тем же таблицам нужно делать в один поток. Серьёзно, мы пытались вставлять и делать выборки в несколько потоков. В лучшем случае это нисколько не ускоряет их выполнение. В худшем случае можно словить дедлоки. Которые в худшем случае лечатся ребутом кластера. Вроде как можно поиграть с очередями запросов. Но что-то я сомневаюсь, что это как-то существенно изменит ситуацию.
У ClickHouse, кстати, всё в точности наоборот. Все операции асинхронны. Параллельная вставка лишь увеличивает (до определённого момента) общую производительность. Конкуренция идёт, как обычно, за CPU, память и дисковый ввод-вывод. Пока всего этого хватает, параллельные запросы друг другу не мешают. Но нет транзакций.
Redshift может внезапно сожрать весь диск. Как я понимаю, каждый подзапрос на самом деле создаёт временную таблицу, куда записываются результаты подзапроса. На диск. Если вы будете неаккуратны, попытаетесь извлечь слишком много строк, или слишком много колонок, в слишком большом количестве подзапросов... То вы легко случайно за несколько минут сможете занять места в два раза больше, чем у вас уже хранится в кластере. И всё. Пока операции не отменятся из-за нехватки места на диске, и это самое место не освободится, весь кластер будет стоять колом.
Redshift хоть и поддерживает SQL,
но не все комбинации, которые можно выразить в SQL,
в нём допустимы.
Например, он очень не любит
подзапросы в сочетании с внешними соединениями.
Или просто слишком большое количество подзапросов.
Вы просто пишете запрос,
слегка его усложняете,
и получаете красивую ошибку,
которая объясняет ничего:
[0A000] ERROR: This type of correlated subquery pattern is not supported yet.
Ситуация усугубляется ещё тем, что вы не можете поднять Redshift где-нибудь локально в Докере. Для локальных экспериментов предлагают использовать PostgreSQL. Ну так хитрый запрос без проблем выполняется в Postgres. А вот в Redshift, внезапно, отказывается работать.
Между тем, ClickHouse без проблем можно запустить локально. Open source и всё такое. Запускаете один узел в Docker, и вперёд.
Ну и последняя мелочь.
В Redshift нет и намёка на разнообразные collation.
Есть лишь два:
CASE_SENSITIVE и CASE_INSENSITIVE.
Что бы это ни значило.
Опять вопиющее расхождение с PostgreSQL.
С ClickHouse проблем было меньше. Больше всего доставлял ZooKeeper. Он нужен для работы реплик. В нём узлы кластера хранят информацию о том, какой узел какие куски данных содержит. И какие, соответственно, нужно скопировать. ZooKeeper — это часть Hadoop, написан на Java. И, если его неправильно приготовить, он будет падать, глючить и жрать диск своими снапшотами и логами.
А ещё ClickHouse не поддерживается популярными инструментами управления миграциями БД. Видимо, потому, что в ClickHouse нет транзакций, и эти инструменты не могут надёжно сохранить метаданные о миграциях в самом ClickHouse. Впрочем, на практике схемы в ClickHouse меняются очень редко. Не сильно сложно руками держать несколько идемпотентных SQL скриптов для воссоздания схемы БД с нуля.
Ну и ClickHouse, к сожалению, ещё не поддерживается как managed сервис в популярных среди западных заказчиков облаках. Он есть только в Yandex.Cloud. Только из-за этого мы не смогли воткнуть ClickHouse в тот самый проект, куда воткнули Redshift. Заказчик настаивал на максимальном использовании managed сервисов в AWS.
На самом деле, Redshift и ClickHouse действительно очень похожи. Оба могут хранить очень много данных. Оба очень эффективно сжимают эти данные на диске. Оба позволяют быстро вставлять много строк.
Разница есть в транзакциях. В Redshift они строго serializable. В ClickHouse их нет. В конкурентности. Redshift, из-за блокировок на уровне таблиц, очень не любит конкурентные запросы на одни и те же таблицы. И в скорости ответа. От Redshift очень сложно добиться ответа быстрее, чем через пару секунд. А ClickHouse вполне может отвечать за сотню-другую миллисекунд.
Ну и подход к масштабируемости у них разный. Redshift хоть и может вырасти до большого кластера из десятков узлов, всё равно будет жить лишь в одном регионе. Его типичный вариант использования — загрузить много данных, чтобы их повертеть аналитиком в одиночестве.
А с ClickHouse можно построить географически распределённый кластер. Можно добиться локальности данных — иметь узел кластера в том регионе, где данные генерируются, для быстрой вставки.
P.S. Презентация
P.P.S. Извините, что почти нет картинок. Но и в официальных документациях их тоже почти нет :(