О логах
2021-02-14
Когда я в прошлый раз писал о логах и логировании, я жаловался на отсутствие в Java удобных средств для создания структурированных логов. Я ошибался, такие средства есть.
Пришла эта магия, конечно же, из Logstash. Той самой вселенной Elastic Stack, где всё засовывается в Elasticsearch, а потом хитрыми запросами можно извлекать данные для графиков и прочего.
Добавляем зависимость:
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>5.2</version>
</dependency>
И теперь, используя SLF4J, можем писать вот такое:
import static net.logstash.logback.argument.StructuredArguments.kv;
import static net.logstash.logback.argument.StructuredArguments.v;
//...
log.info("Processing {} {}", kv("type", TYPE), kv("messagesCount", messages.size()));
log.warn("Skipping unprocessable message {}: {}", kv("type", TYPE), v("message", message));
//...
} catch (Exception e) {
log.error("Rollback changes in {} on error: {}", kv("table", table), v("error", e.getMessage()), e);
//...
Если ничего больше не добавлять, то сообщения в логах приобретут такой вид:
Processing type=TYPE messagesCount=42
Skipping unprocessable message type=TYPE: Message(type=TYPE)
Rollback changes in table=TABLE on error: SQLException...
<stacktrace>
Функция kv(String key, Object value) выводит в место соответсвующего параметра {} строку "key=value",
где "value" примерно соответствует тому, что выдаёт String.valueOf(value).
Функция v(String key, Object value) выводит лишь строку "value".
Казалось бы, так себе улучшение,
лишь чуток приукрасили форматирование.
А у v() вообще зачем-то неиспользуемый аргумент key.
Но эти функции не работают одни.
Они работают совместно с
Logstash Logback Encoder,
который мы, собственно, и подключили как зависимость.
Напоминаю, SLF4J — это API, где определён интерфейс Logger
с этими самыми методами info(), warn(), error().
А всю грязную работу делает бэкенд под названием
Logback.
А мы теперь меняем конфигурацию Logback,
чтобы он использовал специальный енкодер для сообщений логов.
В простейшем случае достаточно добавить файл logback.xml
в корень ресурсов вашего проекта.
<configuration>
<appender name="jsonConsoleAppender" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="net.logstash.logback.encoder.LogstashEncoder"/>
</appender>
<root level="INFO">
<appender-ref ref="jsonConsoleAppender"/>
</root>
</configuration>
И тогда в stdout вместо привычных текстовых логов будет писаться вот такой JSON:
{"@timestamp":"2021-02-13T08:23:32.651+00:00","@version":"1",
"message":"Processing type=TYPE messagesCount=3","logger_name":"...Service",
"thread_name":"ForkJoinPool-1-worker-1","level":"INFO","level_value":20000,
"type":"TYPE","messagesCount":3}
{"@timestamp":"2021-02-13T08:25:33.123+00:00","@version":"1",
"message":"Skipping unprocessable message type=TYPE: Message(type=TYPE)","logger_name":"...Service",
"thread_name":"ForkJoinPool-1-worker-1","level":"WARN","level_value":30000,
"type":"TYPE","message":{"type":"TYPE"}}
{"@timestamp":"2021-02-13T08:27:44.567+00:00","@version":"1",
"message":"Rollback changes in table=TABLE on error: SQLException...","logger_name":"...Service",
"thread_name":"ForkJoinPool-1-worker-1","level":"ERROR","level_value":40000,
"stack_trace":"SQLException...\n<more lines>",
"table":"TABLE","error":"SQLException..."}
На самом деле это не один JSON, а много JSON объектов, разделённых новой строкой. Строго по объекту на строке. Тут я добавил переводы строки в середине объекта исключительно для удобства чтения. Не знаю, как правильно называется такой формат, но он часто встречается при экспорте данных в JSON, например, при выгрузке из той же DynamoDB в S3. Если что, стандартные JSON парсеры можно настроить на чтение этого в коллекцию обычных объектов.
Первое преимущество JSON формата для логов вполне очевидно. Стектрейс теперь не размазан по куче последующих строк :) Теперь каждое сообщение логов занимает ровно одну физическую строку (в файле).
Стандартные поля логов теперь стали свойствами JSON объектов.
@timestamp — это время.
message — это классическое неструктурированное текстовое сообщение.
logger_name — это имя логгера, полное имя класса, как это принято в Java.
thread_name — это имя потока (которое в обычных логах обычно пишется в квадратных скобках).
level — это уровень важности сообщения.
stack_trace — это стектрейс, если в SLF4J было передано исключение.
В данном случае это громадное текстовое поле с переводами строки (\n),
возможно, где-то это может быть и JSON массив.
@version — это, вероятно, версия этого JSON формата в понятиях Logstash.
level_value — это, полагаю, численный эквивалент level.
Ну и самое интересное,
ради чего мы это всё затевали.
Те ключи и значения,
что мы передавали в методы логера через функции kv() и v(),
появились в этих JSON объектах в виде отдельных полей.
А если значение само является сложным объектом,
оно ещё и сериализуется в JSON.
Если у вас Spring (Boot),
можно использовать (или не использовать) LogstashEncoder только для определённых профилей.
Чтобы в тестах логи были привычнее, например.
Для этого вместо logback.xml нужно создать файл logback-spring.xml:
<configuration>
<springProfile name="default">
<appender name="jsonConsoleAppender" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="net.logstash.logback.encoder.LogstashEncoder"/>
</appender>
<root level="INFO">
<appender-ref ref="jsonConsoleAppender"/>
</root>
</springProfile>
<springProfile name="local">
<include resource="org/springframework/boot/logging/logback/base.xml"/>
</springProfile>
</configuration>
Не знаю, что может делать со структурированными логами в JSON Elastic Stack, ещё не пробовал. Но знаю, что интересного получается, если писать такие логи в AWS CloudWatch Logs.
CloudWatch понимает, что логи в JSON. Как минимум он красиво форматирует этот JSON при просмотре логов.
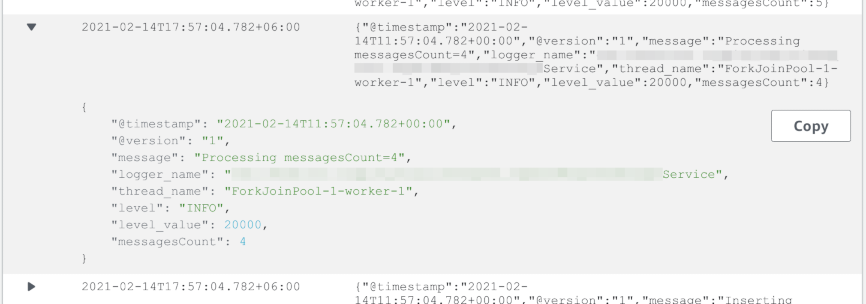
Значения полей JSON можно использовать при поиске по логам. Для этого есть специальный синтаксис.
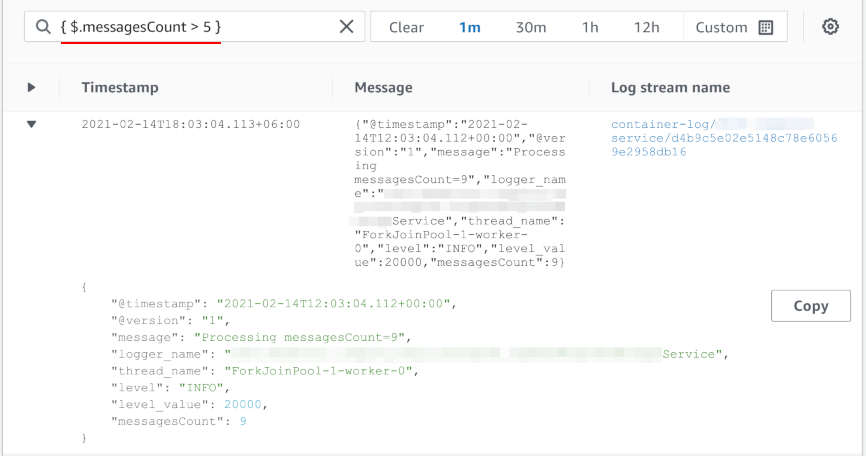
Из выражения поиска можно создать metric filter. Это постоянное сканирование логов и формирование метрики (CloudWatch Metrics) из результатов сканирования. В простейшем случае можно просто подсчитать, сколько раз (с какой частотой) появляется в логах сообщение, подпадающее под фильтр. Но если в логах есть осмысленные значения, можно использовать и их в качестве метрики. В случае JSON можно просто брать значение из поля. В случае текстовых логов можно плясать с регулярными выражениями, но это, понятное дело, сложнее и более хрупко (легко может сломаться, если формат логов изменится).
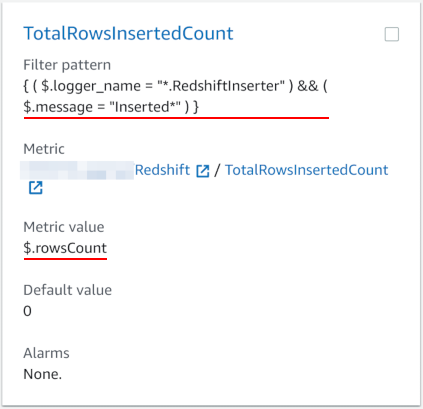
А уж если в CloudWatch есть метрики, то по ним можно строить красивые графики, добавлять их на дашбоарды, и создавать алармы. А алармы можно публиковать в SNS топики, а там уже можно получать письма, СМС или даже сообщения в Слак через AWS Chatbot.
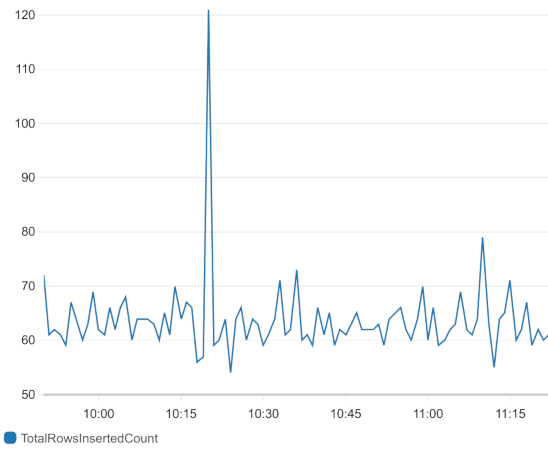
Можно построить полноценную систему мониторинга. Только всё ручками, ручками. Все фильтры, метрики, графики, алармы придётся добавлять ручками. Ну или через Terraform, что лишь немного помогает в повторении конфигурации, если нужно, но не более. Никто за вас не просканирует и не найдёт все важные параметры вашего приложения, которые нужно мониторить.
Меня в этих фильтрах по логам сильно огорчает лишь то, что нельзя создать метрики с измерениями. С dimensions.
У метрик, кроме значения, например, количества сообщений, бывают также измерения, например, тип сообщения, или на каком хосте это сообщение было получено. То есть это дополнительные нечисловые характеристики, метки, связанные с каждым значением. По этим меткам можно фильтровать и группировать значения метрик. Можно выводить красивые stacked графики, рисуя каждое измерение отдельным цветом.
А самое главное, если у вас появится новый тип сообщения, ничего менять не надо, у вас уже есть метрика, где тип сообщения является измерением. Новый тип лишь увеличит размер этого измерения на один. На графике появится линия ещё одного цвета. Это SOLIDно.
В случае с фильтрами по логам для каждого нового типа сообщения придётся создавать новый фильтр и новую метрику. Надо не забывать это делать. И придумывать понятные уникальные имена для метрик. Это не SOLIDно.
Ещё в CloudWatch Logs есть Insights. Это тоже способ опрашивать логи и визуализировать полученные данные. Только с совершенно другим синтаксисом запросов. И он тоже понимает JSON логи как родные.
Можно фильтровать логи по полям (команда filter),
выводить в таблице только нужные поля логов (команда fields),
сортировать эту таблицу по нужным колонкам (sort),
ограничивать количество строк в ней (limit).
В результате получается именно что таблица с данными из логов.
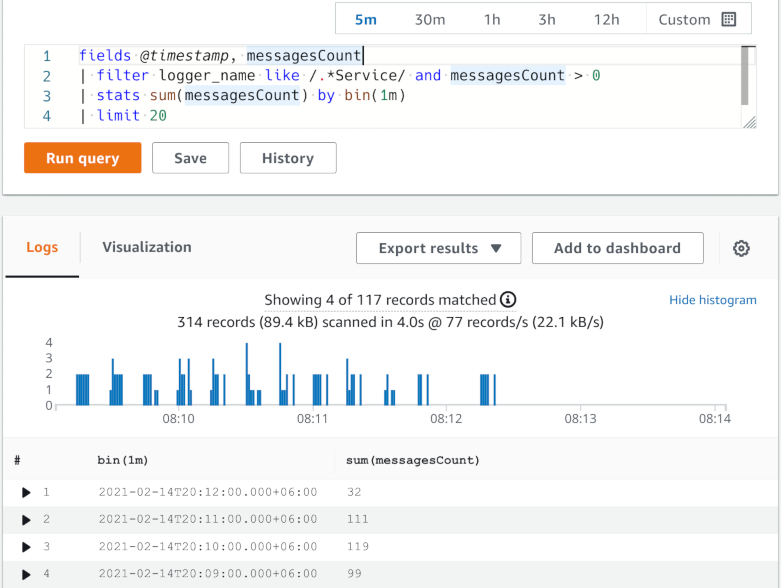
А также можно визуализировать числовые значения из логов,
группируя их за временные интервалы (команда stats).
В этом случае получается график как по метрикам.
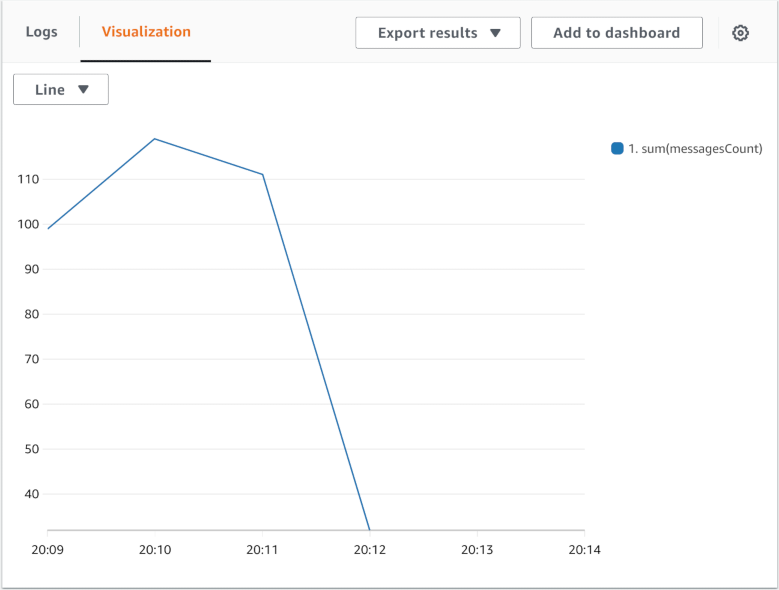
Можно визуализировать более одного значения на одном графике. Можно группировать не только по времени, но и значению любого другого поля, чтобы нарисовать, например, столбчатую диаграмму. Это вроде как добавляет те самые измерения, но, похоже, нельзя одновременно использовать группировку и по времени, и по измерению, чтобы выдать stacked график по времени.
И таблицу логов, и графики от Insights тоже можно добавить на дашбоард. Однако, данные Insights — это не CloudWatch Metrics, поэтому по ним нельзя напрямую выставить алармы. Хотя, можно, конечно, вызывать запросы в Insights ручками и постить custom metrics. Костыли, например, на Lambda.
Insights — довольно новый инструмент (с 2018). Может, и добавят более тесную интеграцию с метриками. Да и более подробная документация по командам определённо не помешает.
Структурированные логи теперь означают логи в JSON. Помимо стандартных таймстампа, логера, логлевела, имени потока и текстового сообщения, которое никуда не девается, в JSON можно запихнуть любые другие полезные поля, которые имеет смысл видеть в данном сообщении отдельно.
JSON формат и значения в отдельных полях JSON сильно упрощают анализ логов и извлечение из них полезных данных. В AWS CloudWatch из логов можно извлекать метрики, строить графики, формировать алармы.
Удобные структурированные логи «из коробки» уже существуют в Java. Спасибо стараниям Logstash и Elastic Stack.