О логах
2020-08-08
Логгирование. Журналирование. Логи. Журналы. Файлы логов. Вроде всё знакомо.
Почему вообще "log"? Это же «бревно». А "logging" — это "cutting down trees for logs".
Если верить вики-словарю, наш программистский "log" происходит от "logbook", то есть от судового журнала. Туда, в том числе, регулярно записывались показания лага, то есть "chip log". Типичный старый добрый лаг — это дощечка на верёвочке. Её бросали за кормой. Сколько верёвочки за единицу времени отмоталось — такова скорость судна. В узлах, которые на верёвочке завязаны. По сути, бревно на верёвке, ага.

Логи чаще всего пишут в файлы.
Эти файлы ещё ротируют, но есть заменяют новыми, а старые удаляют, чтобы логи не разрослись и не заполнили весь диск. Как правило, ротация происходит по времени (файлы подменяются раз в сутки, например) или по размеру файлов (по 10 мегабайт, например). Для ротации произвольных файлов в юниксах даже есть своя специальная программка logrotate. Её обычно запускают по крону.
В файлы могут писаться и бинарные данные. Например, в журнал транзакций пишут все события изменения состояния системы. Это используется в СУБД и журналируемых файловых системах. Смысл в том, что запись в журнал — относительно дешёвая операция. Это лишь дополнение одного файла. Эту запись можно быстро и гарантированно сбросить на диск через все кэши. И начиная с этого момента считать, что, мол, данные действительно записаны. А уже потом взяться за значительно более сложные изменения настоящих структур данных. Которые могут оборваться. Но у нас уже есть журнал, из которого можно всё восстановить.
Дальше будем говорить про журналы (текстовых) сообщений, в которых программы сообщают о своих действиях.
Самая стандартизированная версия таких логов — то, что часто называют access log. Это журнал доступа к веб серверу в Common Log Format. Так уж исторически сложилось, что первые http сервера писали логи именно в таком формате. И развелась куча инструментов, которые анализировали файлы именно в таком формате. Красивые графики нагрузки веб сервера рисовали. Сейчас, конечно, любой веб сервер можно настроить на логирование запросов в любом формате.
127.0.0.1 user-identifier frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326
Очень часто и до сих пор программы пишут свои файлы логов самостоятельно. Но ещё у нас есть syslog.
Syslog существует аж с 80-х. У syslog клиент-серверная архитектура. Впервые мы разделяем то место, где порождаются сообщения (приложение), от того места, где сообщения записываются в те самые файлы (syslog демон). Передача сообщений происходит по сети. Когда-то давно даже по UDP.
Клиентов, порождающих сообщения, много. А syslog демон один. Поэтому в формате сообщений syslog появились дополнительные поля, чтобы как-то сообщения различать. Как минимум распихивать их по разным файлам.
Facility.
Плохо переводимый термин.
В данном случае означает субъекта, который прислал сообщения.
Есть полтора десятка стандартных кодов:
kern, user, mail, daemon, auth и тому подобные.
Собственно, именно файлы с примерно такими именами
вы можете найти в /var/log типичного дистрибутива Linux.
Многие коды (например, uucp) уже устарели и никому не нужны.
А новых кодов (например, docker) никто вводить не собирается.
Severity level.
Уровень серьёзности.
В syslog определены такие:
emerg (Emergency, или panic),
alert,
crit (Critical),
err (или error),
warning (или warn),
notice,
info (Informational),
debug.
Эти уровни вполне живы и вовсю используются.
Message.
Сообщение.
Содержимое сообщения (CONTENT) — это просто строка.
Но выделяют также TAG,
куда обычно записывают имя приложения, отправившего сообщение.
А в более поздних версиях стандарта есть более отдельные поля
для имени приложения, его PID, идентификатора сообщения и тому подобного.
Ну и syslog демон ещё знает имя хоста,
приславшего ему сообщение.
Также присутствует момент времени (timestamp) создания сообщения.
Налицо всё большая структурированность сообщения,
по мере эволюции стандарта.
В современных линуксах вместо демона syslog
у нас присутствует journald,
который часть systemd.
Будем считать,
что кроме загадочного бинарного формата хранения логов и новых команд,
ничего для приложений не меняется.
В современном Debian/Ubuntu работает
и journalctl -f,
и tail -f /var/log/syslog.

Перейдём на клиентскую сторону. Как писать логи.
Конечно,
писать прямо в stdout и stderr никто не отменял.
А всякие докеры даже могут это выхлоп забрать и куда-нибудь передать для анализа.
Но в настоящих API для логирования есть много других интересных вещей.
Для логов из ядра есть специальный printk().
Всё правильно,
ведь stdout/stderr в ядре ещё нет.
И никакого syslog ещё нет.
Поэтому нужна специальная функция,
которая пишет сообщения в специальный буфер в ядре.
А прочитать сообщения можно с помощью команды dmesg.
Даже у простого printk() есть log level.
Те самые уровни важности по syslog.
От emerg до debug.
Плюс специальный псевдоуровень cont,
чтобы записать несколько сообщений в одну строку.
printk(KERN_INFO "Message: %s\n", arg);
Зачем нужен log level? Чтобы фильтровать сообщения при выводе. Скажем, писать в консоль при загрузке только критические ошибки, но не debug выхлоп.
Посмотрим на типичную архитектуру логирования на примере SLF4J. Simple Logging Facade for Java, ага. Это самое популярное API для ведения логов в Java. И активно вытесняет Log4j.
Здесь у нас тоже есть уровни логирования.
Они выбираются соответствующим методом у Logger.
error, warn, info, debug, trace.
В Log4j есть ещё уровень fatal.
Уровней поменьше, чем у syslog.
Зато они понятнее.
error — для ошибок, которые не могут быть исправлены и прерывают текущую обработку.
warn — для ошибок, которые могут быть исправлены или не критичны для последующей работы.
info — для информационных сообщений, которые (как правило) всегда должны быть видны в логах.
debug — для отладочных сообщений, которые обычно не видны, но при необходимости можно включить.
trace — можно втыкать в начало и конец каждого метода, чтобы, при необходимости, увидеть всю последовательность вызовов.
Уровни логирования упорядочены (на то они и уровни).
От самого высокого error до самого низкого trace.
Всегда можно ограничить вывод только сообщений от выбранного уровня и более приоритетных.
По умолчанию выводятся info, warn и error.
Logger logger = LoggerFactory.getLogger(HelloWorld.class);
logger.info("Hello World");
Здесь у нас также есть иерархия логеров.
В Java так принято, что в каждом классе заводится свой логер,
с именем, совпадающим с полным именем класса.
А класс объявлен в пакете.
А пакет в пакете.
Получается развесистое такое дерево логеров,
совпадающее с деревом пакетов,
с классами-листиками.
В Python, в стандартном logging тоже так можно,
только иерархии обычно менее развесистые получаются.
Так принято.
Иерархия логеров очень полезна. Для любой веточки этой иерархии можно задать уровень логирования. Или даже совсем отключить вывод каких-либо логов. В результате можно, например, выводить только ошибки, но для какой-нибудь подсистемы включить дебаг.
В этом основной фокус. Формирование сообщений логов — это одно. Тут можно не лениться и выдавать максимально подробные сообщения. А вывод этих сообщений в файлы или ещё куда — это другое. Тут можно задать и сообщения какого уровня будут выводиться, и в какие файлы какие логеры будут писаться. И, даже, как эти файлы будут ротироваться.
Более того, SLF4 — это только API для отправки сообщений. А к нему прилагается несколько бэкендов для, собственно, записи сообщений. От простых, которые либо просто ничего никуда не пишут, либо всё выплёвывают в stderr. До сложных и навороченных, вроде целой отдельной библиотеки logback.
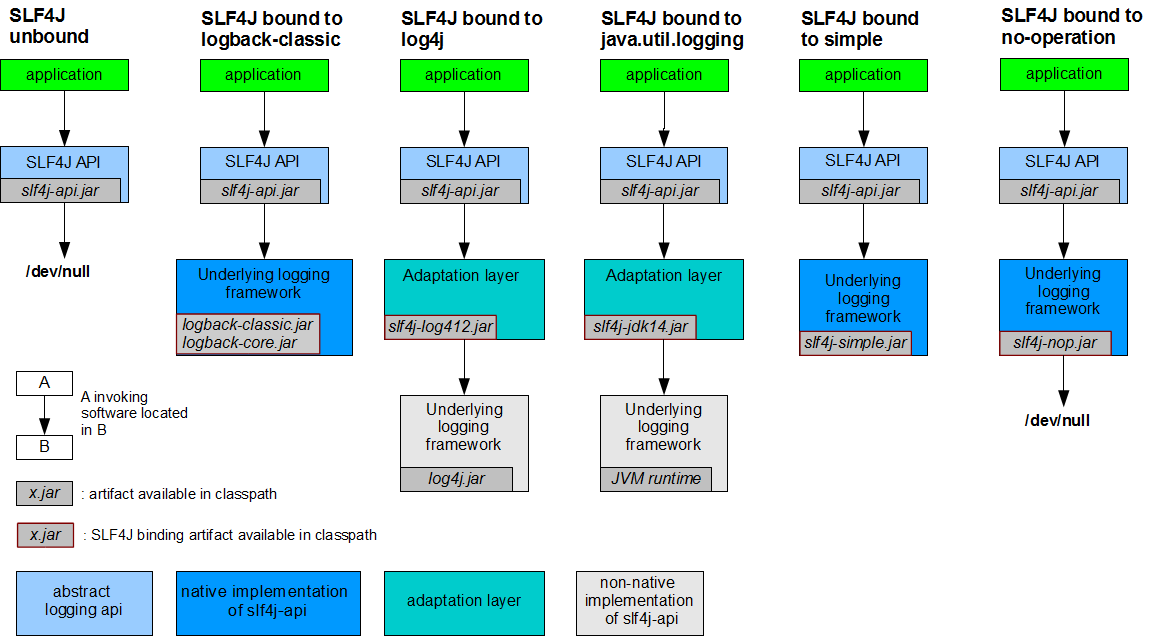
Более того, бэкенд системы логирования можно дополнить отправкой сообщений в любимый мною Sentry. Чтобы сообщения писались не в файл, а отправлялись в Sentry. Установленный вами или облачный (и платный) sentry.io. Как правило, в Sentry нужно отправлять только ошибки или ворнинги.
Sentry не просто собирает сообщения логов. Он их группирует в задачи и собирает статистику. Если данное сообщение вызвано ошибкой, можно увидеть, как часто эта ошибка происходит. Когда ошибка починилась, можно пометить, что больше такого быть не должно. Если ошибка вернётся или появится новая, Sentry пришлёт вам уведомление. Это гораздо удобнее, чем шерстить логи вручную.
Логи можно засылать и в Logstash, которое проиндексирует их в Elasticsearch. По этим данным можно нарисовать какие-нибудь уведомления. Или построить красивые графики в Kibana. Всё вместе это называется Elastic Stack (раньше называли ELK Stack).
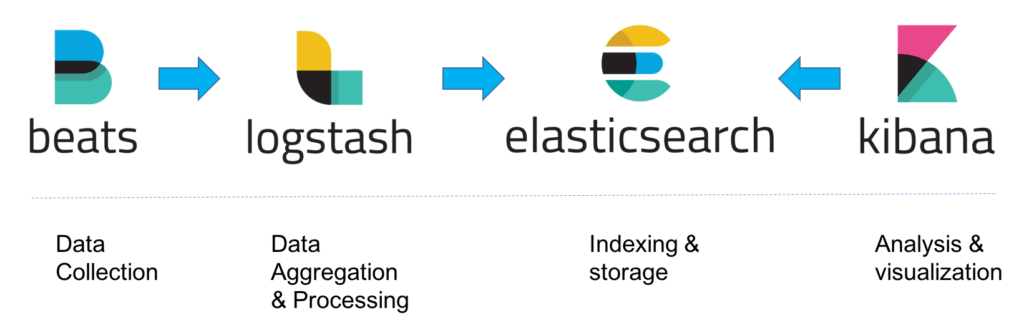
Log level. Logger. Ещё что-нибудь есть? Ведь сообщение — это всё ещё просто строка. Потому и понадобился целый движок полнотекстового поиска Elasticsearch. И целый Logstash, чтобы сообщения парсить. Как-то странно сначала формировать строку, а потом её парсить.
В SLF4J строку сообщения можно форматировать. Отдельно передавая аргументы. В основном это сделано для того, чтобы сэкономить на формировании сообщения, если данный уровень логирования отключен.
logger.debug("Temperature set to {}. Old temperature was {}.", newT, oldT);
В питоновом logging тоже так можно.
И Sentry,
который сам написан на Python,
умеет распознавать одно и то же сообщение с разными переданными аргументами,
и отдельно показывать значения аргументов.
logging.warning('%s before you %s', 'Look', 'leap!')
К сообщению можно прилеплять исключение. В SLF4J это делается прямо явно, исключение передается ещё одним аргументом в метод логирования. И по умолчанию при этом печатается полный стэктрейс исключения. Именно поэтому логи в Java, как правило, полны этих длиннющих стэктрейсов. В Python так не принято.
Goшная библиотека логирования logrus добавляет в сообщение ещё набор полей.
Вот такой код:
log.WithFields(log.Fields{
"animal": "walrus",
"number": 1,
"size": 10,
}).Info("A walrus appears")
Напечатает:
time="2015-09-07T08:48:33Z" level=info msg="A walrus appears" animal=walrus number=1 size=10
Красиво расцвеченное, если вывод в терминал:

Или даже сразу в JSON:
{"animal":"walrus","level":"info","msg":"A walrus appears","size":1,"time":"2014-03-10 19:57:38.562264131 -0400 EDT"}
В общем-то, этот JSON уже вполне пригоден для правильного индексирования в том же Logstash. Это называется "structured logging". Ссылку не дам, ибо пока это довольно общее понятие, но никоим образом не стандарт.
Идея в том, чтобы все переменные параметры в сообщении передавать именно как именованные параметры, а не как часть текста сообщения. Сам текст сообщения лишь сообщает, что вообще происходит.
Должно быть не Item 123 is processing а Processing item=123.
От себя добавлю, что само сообщение в этом случае должно быть максимально кратким и начинаться с глагола. Не обязательно точно соблюдать грамматику, главное, чтобы было понятно, действие ещё только собирается совершиться или уже совершилось, или же произошла ошибка. Различать «до» и «после» особенно важно при обращении к сторонним сетевым сервисам.
Processing item=123 — перед началом обработки.
Processed item=123 — после успешного завершения обработки.
"Completed" — тоже отличный глагол.
Failed to process item=123 — если произошла ошибка.
Тут нужно приложить исключение или другой какой error (в Go).
Только ни в коем случае не "Can't..." или даже "Cant...".
Что значит, пытался, но не смог?
Пытался, но всё failed.
Какой уровень логирования при этом нужен, решайте сами. Это зависит от критичности этих действий с точки зрения пресловутой бизнес-логики. Хорошо, когда результат каждого явного действия пользователя отражается одной записью в логе. Как в access log. Хорошо также видеть в логах все критичные ошибки, которые мешают работе.
В питоновом logging тоже есть некий аналог полей структурированного логирования.
Хотя это больше похоже на прямую передачу параметров форматеру.
Вот этот код:
FORMAT = '%(asctime)-15s %(clientip)s %(user)-8s %(message)s'
logging.basicConfig(format=FORMAT)
d = {'clientip': '192.168.0.1', 'user': 'fbloggs'}
logging.warning('Protocol problem: %s', 'connection reset', extra=d)
Напечатает что-то вроде:
2006-02-08 22:20:02,165 192.168.0.1 fbloggs Protocol problem: connection reset
В SLF4J тоже можно передавать произвольные ключи-значения при логировании. Но сделано это через жопу. Называется это MDC (Mapped Diagnostic Context) и работает примерно как в Python.
Вот так используется MDC:
MDC.put("first", "Richard");
MDC.put("last", "Nixon");
logger.info("I am not a crook.");
И если сконфигурировать logback правильно:
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<layout>
<Pattern>%X{first} %X{last} - %m%n</Pattern>
</layout>
</appender>
То будет напечатано что-то вроде:
Richard Nixon - I am not a crook.
Опять-таки, как будут интерпретироваться эти значения, полностью определяется бэкендом, конфигурацией апендера в данном случае. И далеко не все популярные бэкенды вообще знают про какой-то MDC.
Кажется, я хочу в Java новую библиотеку логирования. Как будто в истории Java их было мало. С синтаксисом вызова поближе к logrus. Чтобы сразу красиво и удобно иметь структурированные логи.