О ClickHouse
2019-11-16
Два с половиной года назад я уже писал про ClickHouse. С тех пор он у нас просто работал. На продакшине. Но тут я делал доклад про него на митапе Райфайзена. И оказалось, что за два с половиной года кое-что всё же изменилось.
Данных стало больше. Сейчас мы храним все запросы лишь за 6 последних месяцев. И это более 2.5 миллиардов записей. Но на дисках они занимают лишь порядка 140 гигабайт. И это в двух репликах.
Всё крутится на шести серверах. По 4 гигабайта ОЗУ и 2 ядра ЦПУ на каждом.
Мы начали использовать шардинг и реплики. Причём конфигурация у нас получилась весьма несимметричная.
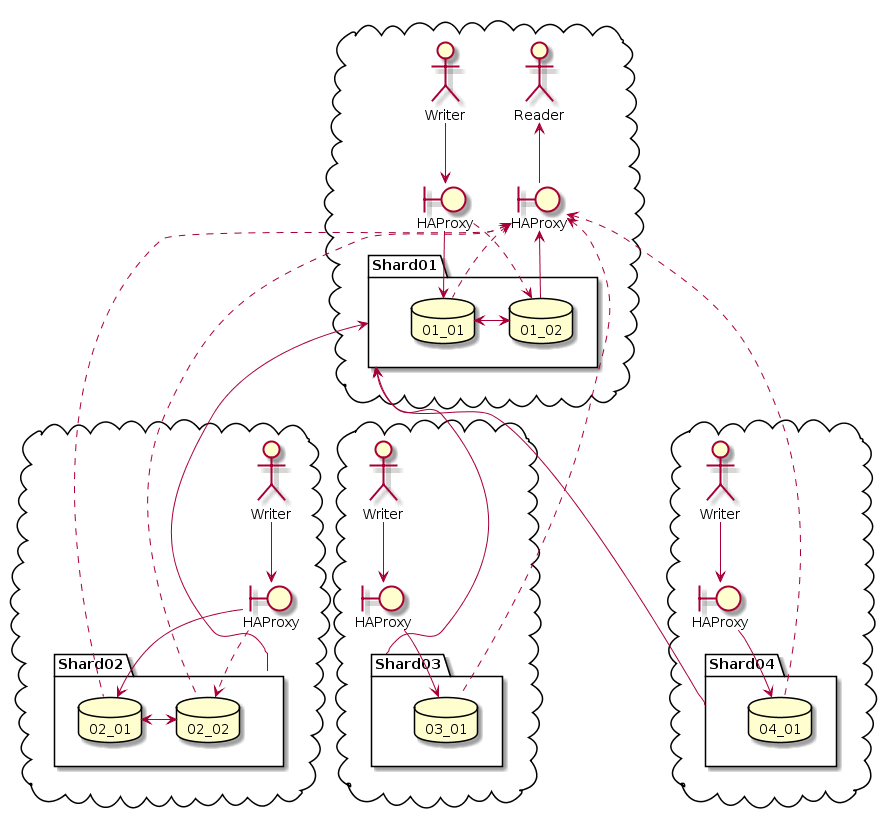
Только в двух, самых нагруженных, шардах есть по две реплики. В основном, чтобы разделить записи от чтений. Запись, как правило, происходит в одну реплику. А чтение, как правило, из другой.
«Как правило», потому что доступ ко всем серверам проксируется через HAProxy. Там же HTTP, он прекрасно проксируется. Проксируется в режиме бэкапа. То есть обращение, как правило, происходит к одному серверу, но если он недоступен, то к другому.
В самом ClickHouse репликация делается как обычно.
ENGINE = ReplicatedMergeTree(
'/clickhouse/tables/{shard}/decisions', '{replica}')
PARTITION BY toYYYYMM(eventDate)
ORDER BY (domainName, time, decision)
SETTINGS index_granularity=8192;
Два этих текстовых параметра — это путь до таблицы шарда в ZooKeeper и имя реплики. Актуальные значения берутся из макросов в конфиге. А индивидуальный конфиг на каждый сервер вполне спокойно можно накатить Ansibleом.
Пришлось поднять ZooKeeper, что доставляет боль. У нас он стоит на каждом узле с ClickHouse. Нужен ZooKeeper посвежее, чем есть в Debian. Пришлось ставить в виде jar, скачанного с официального сайта. И нужно его тщательно настраивать, а то засрёт весь диск своими снапшотами.
Шарды у нас каждый сам по себе. Те, кому нужно писать, пишут в ближайший шард, чаще всего в том же датацентре.
Distributed таблица объявлена на каждом сервере. Так что читать со всего кластера можно с любого сервера. Но чтение, как правило, нужно только в UI (и его бэкенде), который находится возле первого шарда. Так что чаще читается оттуда. Но, если тамошние ClickHouse вдруг станут недоступны, HAProxy перенаправит чтение на сервер куда-нибудь подальше.
Сама Distributed таблица вполне обычная.
CREATE TABLE distributed.decisions
AS decisions
ENGINE = Distributed(logs, default, decisions, rand());
Запись происходит в каждый шард индивидуально,
минуя Distributed таблицу.
Так что rand() распределение хоть и объявлено,
но не используется.
Мы храним живые данные только за последние шесть месяцев. Потому что хостимся мы не в Амазоне, и нельзя просто так взять и создать диск нужного большого размера в любом датацентре. Поэтому храним столько, сколько влезает на имеющиеся диски. Старые партиции, данные за месяц, мы «отцепляем» и rsyncаем на единственный сервер с большим диском. Этих старых данных там уже на двести гигабайт набралось.
Теоретически, на этом сервере с большим диском можно поднять ещё один шард в качестве архива. И это будет работать, можно будет запросить данные за любой период. Просто, в случае запроса на свежие данные наш архивный шард вернёт ничего.
Но мы так не сделали, потому что если шард недоступен, то весь распределённый запрос будет тормозить, ждать таймаута. А реплику для такого объёма данных нам пока влом поднимать.
Со временем оказалось, что, хоть в целом ClickHouse работает с достаточной скоростью, есть один кейс, где всё притормаживает. Когда на заглавной странице пользовательского интерфейса нужно одномоментно запросить среднее время отклика за период, количество принятых и отклонённых запросов, топ разрешённых и отклонённых доменов и категорий, все вместе эти запросы выполняются слишком долго, срабатывают таймауты в браузере.
Поэтому мы решили пойти наперекор идеологии ClickHouse, где предлагается хранить все исходные данные как есть и строить необходимые агретаты по мере необходимости, и построить предварительно подготовленные агрегаты. Тем более, что в официальной документации преагрегация подробно расписана.
Магия делается с помощью AggregatingMergeTree.
CREATE MATERIALIZED VIEW decisions_hourly_agg
ENGINE = ReplicatedAggregatingMergeTree(...)
AS SELECT
eventDate,
toStartOfHour(time) AS time,
userID,
avgState(latency) AS latency,
countState() AS total,
sumState(decision = 'ALLOWED') AS allowed,
sumState(decision = 'FORBIDDEN') AS forbidden
FROM decisions
GROUP BY eventDate, userID, time;
Это материализованное представление,
то есть оно сохраняет своё состояние на диск,
а не запрашивает оригинальные данные каждый раз.
И сохраняет оно значения
-State
функций.
В данном случае: avgState(), countState() и sumState().
В sumState() даже можно указать условие суммирования
(на самом деле суммируются результаты вычисления булева выражения, которые в данном случае рассматривается как 0 или 1).
Чтобы из -State функции получить полноценный агрегат, нужно применить соответствующую -Merge функцию.
CREATE VIEW decisions_hourly
AS SELECT
eventDate,
userID,
time,
avgMerge(latency) AS latency,
countMerge(total) AS total,
sumMerge(allowed) AS allowed,
sumMerge(forbidden) AS forbidden
FROM decisions_hourly_agg
GROUP BY eventDate, userID, time;
Мы просто сделали view для этого.
Главное,
чтобы GROUP BY совпадали.
Теперь количество запросов, среднее время отклика
и график этих значений по времени
получаются быстрее.
Но да,
с точностью только до часа.
За эти два с половиной года и сам ClickHouse немного изменился.
Раньше при создании таблицы с самым распространённым движком
MergeTree
обязательно нужно было использовать колонку типа Date.
Именно значения этой колонки,
с точностью до месяца,
использовались для партицирования.
ENGINE = MergeTree(eventDate, (domainName, time, decision), 8192)
Теперь же у нас есть новый синтаксис. И партиции можно создавать по любой колонке, даже по любому выражению по любой колонке. Кажется, это существенно расширяет области применения ClickHouse. Ключ сортировки теперь может включать в себя больше колонок, чем первичный ключ. Появилось больше настроек движка.
Определение движка в новом синтаксисе, аналогичное старому синтаксису, выглядит так:
ENGINE = MergeTree()
PARTITION BY toYYYYMM(eventDate)
ORDER BY (domainName, time, decision)
SETTINGS index_granularity=8192
ClickHouse очень интенсивно развивается. Новые стабильные версии выходят каждую неделю. И каждая новая версия действительно что-то исправляет. Если вы обнаруживаете странные ошибки или исключения C++ в логах, попробуйте обновить версию, наверняка поможет.
Интересным оказалось, что в какой-то момент создатели ClickHouse переключились на статическую сборку для Debian. Имена пакетов изменились. Будьте внимательны.
$ apt search clickhouse
clickhouse-common-static/main,now 19.17.2.4 amd64
Common files for ClickHouse
clickhouse-server/main 19.17.2.4 all
Server binary for ClickHouse
clickhouse-server-base/main 19.4.5.35 amd64
DEPRECATED PACKAGE (use clickhouse-common-static): Server binary for clickhouse
clickhouse-server-common/main 19.4.5.35 all
DEPRECATED PACKAGE (use clickhouse-server): Common configuration files for clickhouse-server-base package
А вот формат хранения не менялся. Мы пару раз обновляли ClickHouse, и ни разу не потребовалось никаких особых миграций. Только при обновлении реплик бывало, что, из-за сменившегося алгоритма подсчёта контрольных сумм, пока версии на репликах были разными, они ругались друг на друга, мол, неправильно вы тут контрольные суммы блоков считаете.
ClickHouse показывает себя стабильным и надёжным решением. Мы довольны.
И это именно аналитическая БД. Не timeseries. Похоже, timeseries и аналитические БД разошлись в ходе своей эволюции.
Timeseries — это чтобы красивые графики рисовать. Тут не нужно хранить данные всегда, а только за период, нужный для графиков. Тут не нужна абсолютная точность, а нужно агрегировать и сворачивать данные до точности, достаточной для графиков.
В аналитике же важно хранить все исходные значения. И уметь строить по ним совершенно разные агрегаты, группируя по разным измерениям, за разные периоды и с разной точностью.
ClickHouse — отличная аналитическая БД.