Об очередях
2019-05-01
И снова об Амазоне. Снова о Лямбдах. И том, как их правильно готовить.
Есть в AWS штука под названием IoT. Точнее IoT Core. Оно работает как брокер для протокола MQTT. Это, как оказалось, популярный протокол в мире интернета вещей. Простенький бинарный протокол поверх TCP, по которому «устройства» посылают всякие сообщения. MQTT реализует модель «публикация-подписка». То есть устройства публикуют сообщения в некотором топике, а заинтересованные стороны подписываются на сообщения из интересующих их топиков.
Кстати, если подпрыгнуть, то можно в AWS IoT получать сообщения и через HTTPS, с авторизацией по клиентскому сертификату.
Кстати, AWS IoT не очень подходит для приёма сотен сообщений в секунду. Лимиты на аккаунт там достаточно низкие. Вам нужно держать долгие и параллельные коннекции, и делать кучу паблишей в каждой коннекции, чтобы как-то в них уложиться.
Так вот, присылают нам сообщения по MQTT в AWS IoT. А тот, в свою очередь, может по этим сообщениям (в определённом топике), что-то сделать. Например, вызвать Lambda.
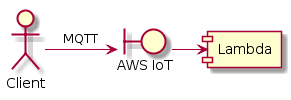
Лямбду вызывать может много кто. Странно, что про вызов лямбды из IoT написано только в документации IoT. Может, поэтому этот вызов так криво работает, накостылен?
Кривизна вот в чём. Лямбда может падать. Она может падать даже если ваш код лямбды работает идеально. Просто потому что контейнер не запустился. Или в VPC зайти не получилось и ваш инстанс PosgtreSQL в результате недоступен. Вот IoT запускает лямбду, но недостаточно полноценно отрабатывает ошибки.
Мы наблюдали такое.
С одной стороны внешний клиент
получает успешные подтверждения своей публикации
(MQTT сообщения PUBACK).
С другой стороны,
в логах лямбды вообще никаких исключений,
она, если исполняется,
исполняется без ошибок.
Но сообщения теряются.
Оказалось,
в логах AWS IoT
(и такие есть, могут писаться в CloudWatch)
есть невнятные ошибки вызова лямбды.
Вот так вот.
Как избежать потери сообщений? Некоторые рассуждения и посты в чужих блогах говорят: нужна очередь. Если какой-нибудь IoT не может запустить лямбду, в том числе, например, и потому, что на запуск лямбды нужно время, пусть вместо этого он быстро-быстро постит сообщения в очередь. А уже из очереди сообщения пусть выгребает лямбда, по мере возможности.
Очереди в Амазоне — это SQS (Simple Queue Service). И AWS IoT умеет посылать туда сообщения. А, с недавних пор, лямбды могут читать и обрабатывать сообщения прямо из SQS. Раньше SQS и Lambda можно было подружить лишь окольными путями: одна лямбда запускается по таймеру и проверяет наличие сообщений в очереди, и запускает нужное количество других лямбд, которые уже самостоятельно выгребают сообщения из очереди. Теперь эти проверки и выборки делает сам сервис Lambda, а ваш хэндлер лишь обрабатывает сообщения.
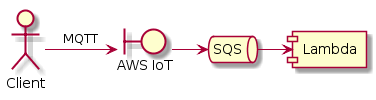
Так уж получилось, что у нас эти сообщения нужно скормить нескольким разным лямбдам. Но SQS — это канал «точка-точка». Если к одной очереди подключить несколько потребителей, то сообщения будут как-то распределены между ними. Никто из потребителей не получит всех сообщений.
Строго говоря, потребление сообщений из SQS происходит в несколько этапов. Сначала потребитель выбирает одно или несколько (до десяти) сообщений из очереди. При этом эти сообщения становятся невидимыми для других потребителей на время "visibility timeout". Соответственно, другие потребители будут выбирать другие сообщения. Если обработка завершилась успешно, потребитель явно удаляет выбранные сообщения из очереди. Если обработка не завершилась успешно, например, ваш хэндлер лямбды выбросил исключение, сообщения не удаляются из очереди, и их может выбрать кто-то другой спустя visibility timeout.
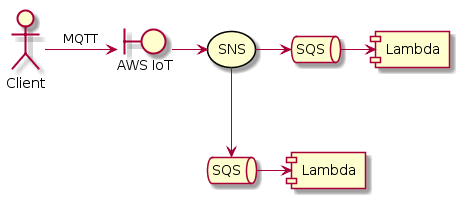
Для широковещательной рассылки, чтобы все получатели получали бы все сообщения, в Амазоне есть SNS (Simple Notification Service). Вообще-то SNS может рассылать сообщения в кучу разных мест. Это может быть и рассылка по E-mail, и SMS, и push уведомления на мобильные устройства. Но нас интересует, что SNS может отправлять сообщения в SQS.
Получается, что SNS делает fan-out рассылку наших сообщений. Но, для надёжности, мы оставляем SQS очередь перед каждой лямбдой, чтобы ничего не потерять. SNS + SQS — это стандартный паттерн в Амазоне.
Очереди в правильном месте могут помочь не только с IoT, но и, например, с DynamoDB Stream. Это такой поток операций записи в таблицу DynamoDB, на который можно подписать лямбду. И эта лямбда может делать что-нибудь полезное, например, писать в другую таблицу DynamoDB. Но беда в том, что у DynamoDB Stream может быть не более двух читателей. На практике лямбда, подписанная на стрим, выполняется только в один поток. И она вполне может не успевать. А вот если воткнуть промежуточную очередь, можно будет разгребать обновления и в несколько потоков.
SQS триггер работает. Но он приподнёс один очень неприятный сюрприз. Если лямбда часто падает, триггер отрубается. Почему — непонятно. В документации про это — ни слова.
А падать лямбда может просто так. Например, при деплое новой версии. Или при возрастании нагрузки. Похоже, всегда, когда Амазону приходится переразворачивать новые контейнеры с кодом лямбды. Это не проблема вашего кода. Просто так Lambda работает.
А если триггер отрубается, в очереди копятся сообщения. Ты включаешь его, и сообщения мощным потоком сыпятся на лямбду. Lambda масштабируется, запускает новые контейнеры. И отдельные запуски лямбды начинают падать. И триггер снова отрубается. Замкнутый круг.
Одна из причин падения лямбды всё же оказалась в нашем коде. Точнее в том, как он пишет в DynamoDB.
DynamoDB штука гибкая и масштабируемая. Она способна выдержать громадную интенсивность записи. Но это и стоит соответствующих денег. Поэтому для "write capacity" (и read тоже) DynamoDB настраивают автомасштабирование. Идея в том, чтобы держать эту ёмкость ровно на достаточном уровне для текущей нагрузки, не больше. В идеале capacity следует вашей текущей нагрузке, согласно, скажем, ежедневной интенсивности прихода сообщений (она, такая периодичность, есть).
Беда в том,
что при возрастании нагрузки DynamoDB нужно несколько минут,
чтобы отмасштабироваться вверх.
А в течение этих минут
ваша лямбда может получать ProvisionedThroughputExceededException.
Этими исключениями DynamoDB как бы говорит:
«Погоди, погоди, я (ещё) не могу принять столько много операций записи».
Был бы у нас постоянно запущенный сервис,
можно было бы подождать,
и повторить позднее.
Но в лямбде ждать нельзя,
ибо это стоит денег.
Нужно что-то делать.
Теоретически,
пусть ProvisionedThroughputExceededException роняет нашу лямбду.
Эксепшен в хэндлере есть фейл выполнения лямбды.
Фейл выполнения приводит к тому,
что сообщения возвращаются обратно в SQS,
спустя visibility timeout.
Та самая задержка,
что нам нужна.
Автоматически.
Но фейл выполнения лямбды отрубает у нас триггер. С отрубленным триггером сообщения накапливаются. Когда врубаем триггер обратно, накопленные сообщения вызывают ещё больше записей в DynamoDB. Этот эксепшен происходит ещё чаще. Лямбда падает. Триггер отрубается. Беда.
Приходит такая идея.
А что,
если не полагаться на возврат сообщений в очередь
при падении лямбды,
а сделать это руками,
когда приходит ProvisionedThroughputExceededException?
SQS позволяет задавать задержку сообщения при помещении его в очередь,
в течение этой задержки сообщение никто не увидит и не заберёт в обработку.
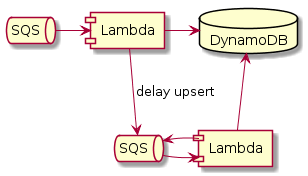
И из лямбды вполне можно пихать сообщения обратно в ту же очередь,
из которой она их загребает.
В результате, с точки зрения Амазона
лямбда будет выполняться успешно,
но то,
что не успела съесть DynamoDB,
будет возвращено в очередь
и будет вставлено позднее,
когда DynamoDB уже прочихается.

Это всё прекрасно, пока у вас нет мультипликации записи, и вы обрабатываете сообщения по одному. Но у нас, в самой сложной лямбде, одно сообщение на входе порождает двенадцать апсертов в DynamoDB. И мы выбираем сообщения из очереди батчами по десять, потому что тогда некоторые из них можно объединить и уменьшить количество вставок. Но в худшем случае получается, что на один вызов лямбды должно выполниться сто двадцать записей в DynamoDB. И вероятность того, что хотя бы одна из них завершится тем самым эксепшеном, весьма велика. И мы возвращаем те же самые десять сообщений обратно, чтобы попытаться сделать сто двадцать апсертов позднее.
На практике это однажды привело к тому, что в нашей очереди копились задержанные и новые сообщения, DynamoDB напрягалась по полной (максимум write capacity всё же был ограничен), лямбда работала в сотню потоков, но ничего не двигалось с места. Всё это хозяйство повторно пыталось обрабатывать одни и те же сообщения, безрезультатно, прожигая деньги заказчика.
Справедливости ради, именно такое поведение получилось бы, если бы триггер не отрубался, и десяток сообщений возвращался бы в очередь просто из-за падения лямбды.
Надо избавиться от мультипликации записи при обработке задержанных сообщений. А значит, нужно задерживать и повторять не исходные сообщения, а непосредственно апсерты в DynamoDB. Нужно придумать свой формат сообщений для этого, что оказалось довольно просто. И нужна отдельная лямбда, чтобы повторять задержанные апсерты. В моём случае я использовал тот же код, но хэндлер других сообщений. Вот такая штука работает.
Но у нас по-прежнему остаётся проблема вырубания триггера. Лямбда может падать и без эксепшенов, а просто, потому что ей захотелось. Конечно, она никогда не падает полностью, но процент успешных вызовов может временно упасть до 80%, пока оно масштабируется. Этого достаточно, чтобы триггер отрубился.
Пока техподдержка Амазона молчит, почему триггеры вырубаются, я прикрутил костыль. Просто ещё одна лямбда, которая запускается каждые три минуты, и проверяет все event source, связанные с SQS, и включает их, если они отключены.
class TriggersEnabler(
private val lambda: AWSLambda
) {
fun enableAll() {
val result = lambda.listEventSourceMappings()
for (mapping in result.eventSourceMappings) {
if (needToEnable(mapping)) {
enable(mapping)
}
}
}
private fun needToEnable(mapping: EventSourceMappingConfiguration): Boolean =
mapping.eventSourceArn.contains(":sqs:", true)
&& mapping.state.equals("Disabled", true)
// && mapping.stateTransitionReason.contains("Lambda", true)
// TODO: how to separate manually disabled from automatically disabled?
private fun enable(mapping: EventSourceMappingConfiguration) {
val request = UpdateEventSourceMappingRequest()
.withUUID(mapping.uuid)
.withEnabled(true)
lambda.updateEventSourceMapping(request)
}
}
Занятно, что у event source есть свойство stateTransitionReason.
В документации
сказано,
что там может быть два значения:
"User initiated" и "Lambda initiated".
Я думал,
что автоматические вырубания триггера будут "Lambda initiated".
Но на практике они все
"USER_INITIATED".
Втыкайте очереди везде, где можно, но не нужно терять сообщения. Вот.