Об AWS
2018-06-11
Переход на Terraform заставил меня узнать об амазоновом облаке такие вещи, которые лучше бы я и не знал. О Terraform — в следующий раз. А сейчас — снова об AWS.
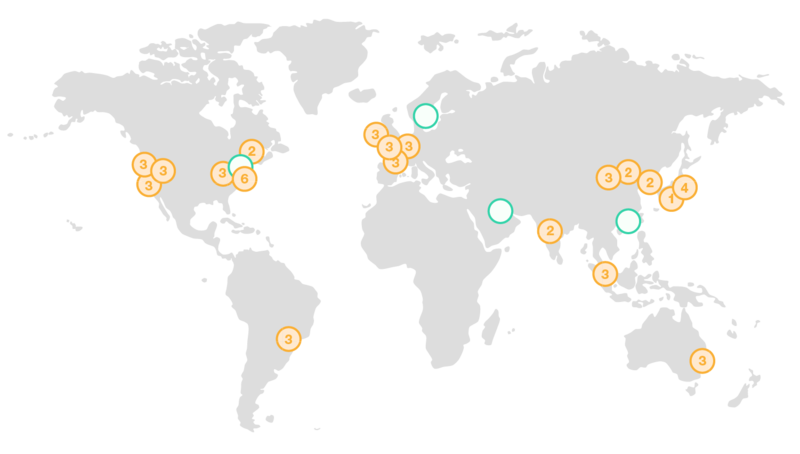
Регионы. Regions.
Датацентры Амазона
разбросаны
по всему миру.
Ну кроме России.
У регионов очень милые
имена.
В Ирландии — eu-west-1.
Во Франкфурте — eu-central-1.
В Орегоне (штат США такой, на западном побережье) — us-west-2.
В Северной Вирджинии (это уже восток США) — us-east-1.
N. Virginia — это «домашний» регион AWS,
здесь раньше всего появляются новые плюшки.
Как правило, все ресурсы Амазона привязаны к конкретному региону, и живут именно в нём. Даже там, где существуют глобальные пространства имён, вроде бакетов S3, всё равно данные хранятся в конкретном регионе.
Зоны доступности.
Availability Zones.
Их несколько (как правило три) в каждом регионе.
Амазон вроде как обещает,
что никогда не будет отключать регион весь сразу,
а только отдельные зоны доступности.
Поэтому настоятельно рекомендуется
размещать отказоустойчивые кластеры
одновременно в нескольких зонах.
Имя зоны доступности
получается из имени региона добавлением буковки.
В Орегоне, например,
есть три зоны: us-west-2a, us-west-2b, us-west-2c.
Самый главный (и исторически первый) ресурс в амазоновом облаке — это виртуальные машины EC2. Elastic Compute Cloud. Вот эти вот зоны доступности и многое остальное, о чём я расскажу позднее, оно идёт от EC2. И даже если вы не работаете с EC2 напрямую, наверняка почти все сервисы Амазона работают поверх EC2. И многие соображения и ограничения из EC2 распространяются и на эти сервисы.
Идентификаторы ресурсов.
О-о-о...
Тут полнейший разнобой.
Чаще всего встречается буквенно-цифровое обозначение,
где по первым буквам можно догадаться,
что это за ресурс.
i-0de8aad2fb20a47ce — это идентификатор инстанса EC2.
subnet-3447c77f, vpc-5e757727 — это подсеть и VPC.
А вот такое: E1VO622G1KKGV1 — это CloudFront Distribution.
Но похоже,
что рано или поздно всё перейдёт на ARN
(Amazon Resource Name) —
идентификаторы,
технически очень похожие на URN.
Вот тот же самый CloudFront Distribution,
но в виде ARN: arn:aws:cloudfront::999999999999:distribution/E1VO622G1KKGV1.
А вот ARN Application Load Balancerа: arn:aws:elasticloadbalancing:us-west-2:999999999999:loadbalancer/app/sitec-test-alb/fb97bc09692c72ea.
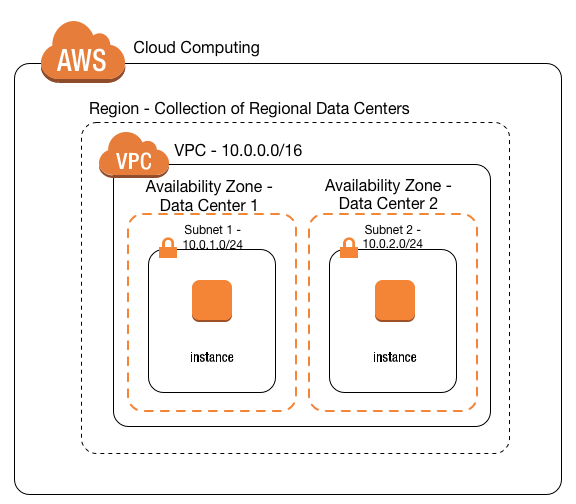
Ничто не мешает заводить EC2 инстансы (и даже Fargate контейнеры), и раздавать им сразу публичные IP адреса (пока они есть, и пока они не заблокированы). Но когда у вас куча микросервисов, вовсе не обязательно выставлять каждый из них голой попой в Интернеты (и платить за публичный IP для каждого). То же касается и всяких баз данных и кэшей (которые managed сервисы в Амазоне). Их все можно элегантно объединить в VPC, Virtual Private Cloud.
Можно подумать, что VPC — это просто серая сеть, которая объединяет созданные в ней ресурсы. Так оно и есть. Но несколько сложнее.
VPC создаётся на весь регион. Но внутри должна содержать подсети, subnets. А каждая подсеть уже создаётся для конкретной availability zone. У подсети определён CIDR блок адресов. Либо серые IPv4, какие выберете. Либо настоящие IPv6, какие разрешит Амазон. Ресурсы в VPC всегда создаются в определённой подсети, и получают IP адрес из её блока.
Точнее не сами ресурсы, а их сетевые интерфейсы, Elastic Network Interfaces. Такие интерфейсы в VPC получают не только EC2 инстансы, но и RDS инстансы, и ElastiCache инстансы, и задачи Fargate, и даже NAT Gateway и Elastic Load Balancer. И ко всем ним применимы правила, о которых далее.
Из VPC нужно ходить в интернеты. Чтобы пакеты какие-нибудь скачать. Чтобы к DynamoDB или ECS подрубиться. Хоть это и амазоновые сервисы, но с точки зрения «из VPC» они находятся «там».
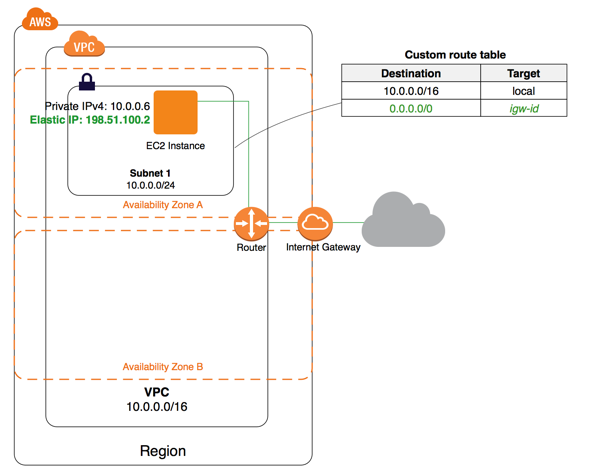
Способ выйти в интернеты номер раз. Нужен Internet Gateway. Он один на весь VPC. Ну просто ресурс такой, у него даже настроек нет. Нужно, чтобы у EC2 инстанса или ELB в подсети был настоящий IP адрес. Нужно прописать маршрут в таблице маршрутизации (Route Table), что, мол, в интернеты ходить через этот Gateway. Ну и связать данную подсеть с этой таблицей маршрутизации.
На каждую avaiability zone
нам нужна своя подсеть.
Назовём их публичными.
Одна таблица маршрутизации,
тоже публичная.
Где будет сказано,
что в 0.0.0.0/0 и ::/0 (не забываем про IPv6)
нужно ходить через Internet Gateway.
И Route Table Accosiations,
чтобы сказать,
что каждая из наших публичных подсетей
работает с данной таблицей маршрутизации.
Но это пока ещё не всё.
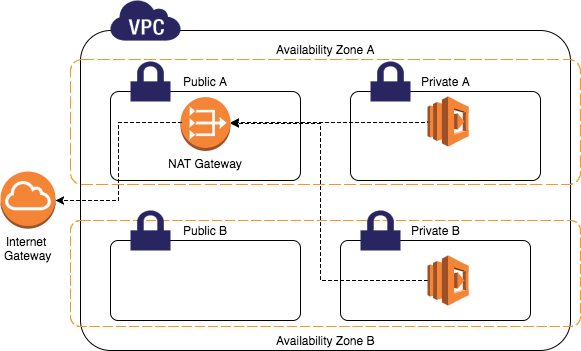
Способ выйти в интернеты номер два. Здесь не нужны публичные IP на каждом интерфейсе. Потому что будет NAT. Нужен NAT Gateway. Этой штуке нужно выдать публичный Elastic IP и разместить её Elastic Network Interface в одной из публичных подсетей, что мы создали ранее. Достаточно будет одного NAT Gateway на VPC.
А теперь мы можем создать ещё подсети. Снова в каждой availability zone. И ещё одну таблицу маршрутизации. Только в маршрутах теперь указываем, что в интернеты ходить надо через NAT Gateway. Связываем новые подсети с этой новой таблицей маршрутизации. Теперь интерфейсам в этих подсетях не нужно иметь публичный адрес. Их трафик будет натиться на NAT Gateway. Так как прямые подключения из интернетов в эти подсети будут невозможны, назовём их приватными. Как и в случае любого NAT, мы сэкономили на публичных адресах.
В случае IPv6 экономить на адресах нужды нет. Но ограничить входящие подключения тоже хочется. От греха подальше. Для этого нужен Egress-Only Internet Gateway. Он работает так же как обычный Internet Gateway, но пропускает только исходящие (egress) соединения.
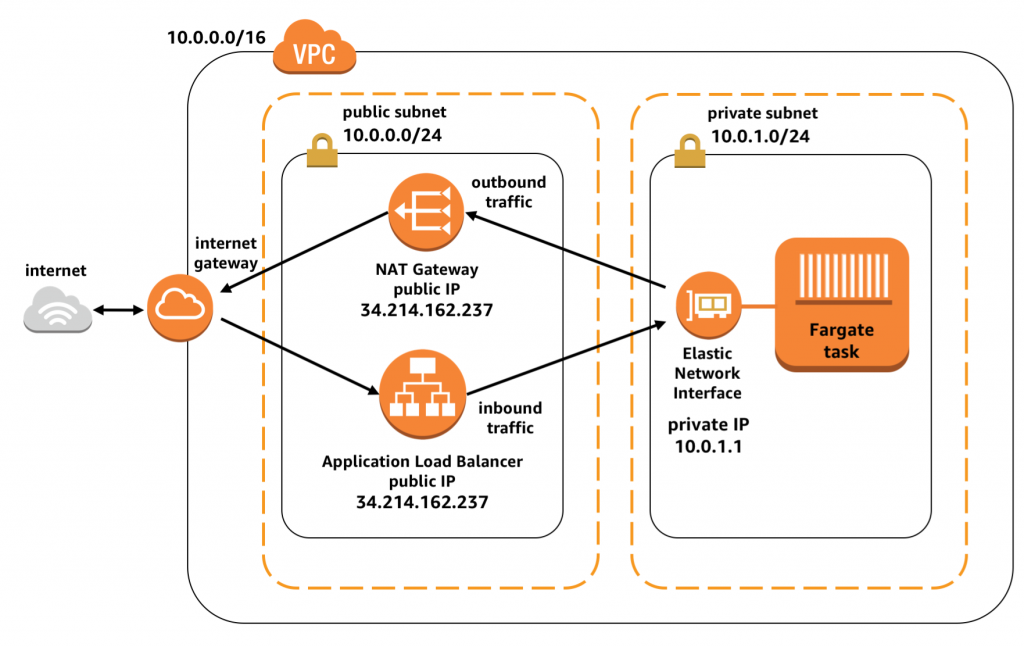
Аналогично работает Elastic Load Balancer (ELB). Его интерфейсы, где он слушает входящий трафик, должны быть расположены в публичной подсети, и иметь реальный IP. Ему главное эти подсети указать, а остальное он сам сделает. А дальше он будет прокидывать запросы на ваши бэкенды уже в приватных подсетях. Только ему нужно, чтобы его интерфейс и интерфейс бэкенда были в одной avaiability zone. Так что одним адресом на всю VPC не отделаетесь. Нужно по адресу и интерфейсу на каждую зону доступности.
Ну а теперь последний, но очень толстый нюанс. Security Groups.
Все эти наши Elastic Network Interface, что EС2 инстансов, что Fargate taskов, что load balancerов, что RDS или ElastiCache, обязательно привязаны к некоей Security Group. А часто даже к нескольким Security Group. Будем говорить, что интерфейс (или сервис) находится в Security Group.
А сами эти Security Group — это такой firewall. Точнее то, что в классических файерволах называют «zone». Некая зона, или группа ресурсов, для которой заданы правила фильтрации входящего и исходящего трафика, а также правила проброса трафика между зонами.
Вот и для Security Group можно задать правила для входящего трафика. С каких IP адресов, на какие порты можно. Из какой другой Security Group можно. Можно задать правила для исходящего трафика. На какие IP адреса, на какие порты можно. На какие другие Security Group можно. Отдельно задаётся, можно ли интерфейсам из одной Security Group ходить к другим интерфейсам в этой же группе, то есть разрешён ли self трафик.
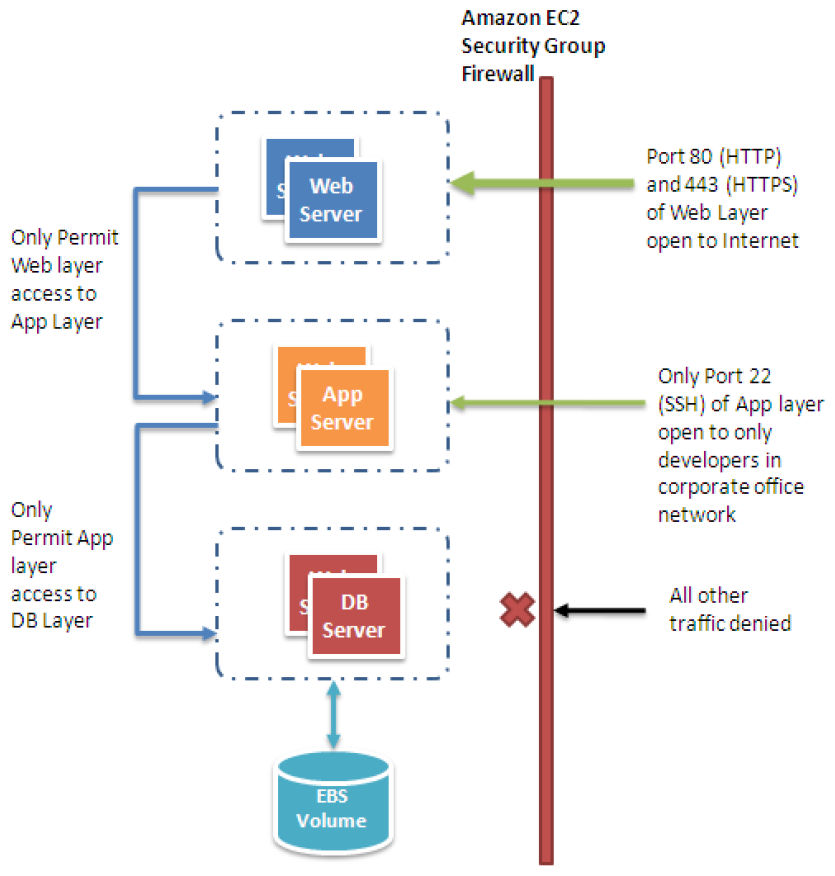
Например, возьмём load balancer. Пусть он живёт в своей Security Group, а балансируемые им сервисы — в другой Security Group.
Load balancerу нужно разрешить
входящий трафик отовсюду
(из сетей 0.0.0.0/0 и ::/0)
на те порты,
что он слушает
(443 в случае HTTPS).
И разрешить исходящий трафик в Security Group
балансируемых сервисов,
явно указав эту самую их группу.
Причём разрешить нужно как порты,
куда будет идти балансируемый трафик,
так и порты,
куда будет делаться health check.
В частном случае можно все порты на выход открыть.
А в Security Group,
где расположены ваши сервисы,
нужно, наоборот,
разрешить входящий трафик из Security Group
load balancerа,
на основные порты,
и порты health check.
А если этим сервисам нужен доступ
к какому-нибудь DynamoDB,
или это контейнеры ECS,
то им ещё понадобится разрешить исходящий трафик
куда угодно
(опять 0.0.0.0/0 и ::/0).
Конечно, проще поместить весь ваш маленький кластер, вместе с load balancers и всякими ElastiCache, в одну единственную Security Group. Разрешить в ней self, входящий трафик на пару публичных портов балансера, и исходящий трафик. И всё. Но это тоже нужно не забыть сделать.
Вот такой он сложный, этот VPC. А если учесть, что при старте Fargate контейнеров или Lambda, которым нужен доступ к VPC, выделение Elastic Network Interface занимает где-то минуту, становится ещё и грустно. Но, се ля ви.
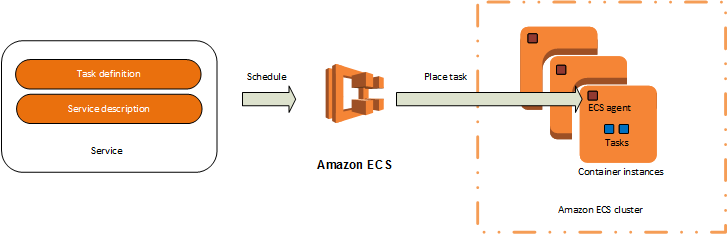
Кстати, о ECS и Fargate.
ECS. Elastic Container Service. Штука для запуска Докеров в Амазоне. Запущенный там сервис можно связать с load balancer. Лучше с Application Load Balancer, который понимает HTTP(S) и может разруливать трафик, исходя из пути запроса. Ну и терминацией TLS занимается. И вот с момента, когда наш сервис связался с балансером, ELB начитает играть существенную роль в работе ECS.
Во-первых, у нас таки будет нормальная балансировка трафика. Можно запустить несколько экземпляров сервиса (в ECS это называется task), балансер будет обо всех них в курсе, и будет делать честный round-robin запросов на них. Можно даже включить какой-то stickyness.
Во-вторых, балансер будет проверять доступность каждого экземпляра сервиса. Application Load Balancer умеет делать это одним единственным способом. Он посылает HTTP запрос на указанный порт и указанный путь, и ожидает ответ «200 OK» (или любой другой, какой настроите). Если какой-то task не ответил, балансер рапортует об этом ECS, а ECS прибивает задачу (и запускает новую).
Проблемой тут может быть время холодного старта. Те же Spring Boot приложения начинают слушать порт и отвечать на запросы через минуту-другую (зависит от доступного CPU) после запуска. Поэтому в настройках ECS сервиса нужно тщательно указывать параметр «health check grace period». Мол, ненене, на мнение load balancer о здоровье задачи мы начинаем обращать внимание только спустя вот столько секунд.
В-третьих, балансер следит за временем обработки запроса. Если ваш сервис не ответил в течение 60 секунд, пользователь, конечно, получит свои «504 Gateway Timeout». Но балансер снова нажалуется ECS, а тот снова прибьёт провинившуюся задачу.
А если эта задача — единственный экземпляр этого сервиса? Правильно, пользователь будет видеть «503 Service Unavailable» ещё пару минут, пока новая задача не прочухается и не станет видна здоровой балансеру.
Что делать? Можно увеличить этот шестидесятисекундный таймаут по умолчанию. Но зачем? Если бэкенд не отвечает минуту, значит, это какой-то неправильный бэкенд. Надо с этим что-то делать. Подымать несколько задач на сервис, чтобы и нагрузка балансировалась, и умирали не все сразу. Искать узкие места. Думать, как делать тяжёлые операции асинхронными...
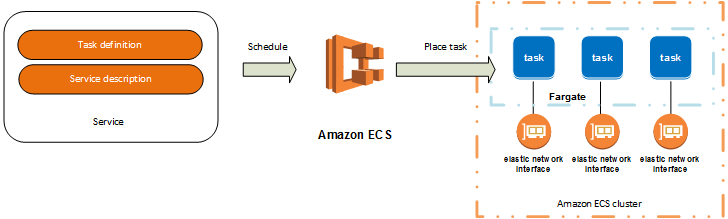
Fargate. Это новый способ запуска контейнеров в ECS. Совсем недавно был доступен только в Северной Вирджинии, теперь появился в Ирландии и Орегоне точно.
Раньше для запуска контейнеров
вы заводили виртуальные машинки EC2.
Запускали их из специального образа,
где уже есть Docker и ECS агент.
Скажем,
пару машинок t2.medium,
с 2 vCPU и 4 гигами памяти на борту.
Запускаете их в разных availability zone,
конечно же.
(vCPU — это условный попугайский CPU,
которым меряется производительность
в Амазоне).
И вот на этих машинках
вы запускаете столько контейнеров,
сколько влезет.
В случае Fargate вы запускаете ваши контейнеры незнамо где. Вы просто задаёте для таска ECS требования по памяти и CPU (обязательно оба). И Fargate запустит таску на «железе», соответствующему этим требованиям. Выбор доступного «железа» — не сильно большой. Минимум — 0.25 vCPU и 512 мегабайт памяти.
0.25 vCPU — это сильно мало.
Тот же контейнер,
когда вы запускали его на EC2,
если вы его не ограничивали по CPU,
мог воспользоваться всеми 2 vCPU,
доступными на этой виртуалке.
А с Fargate — только 0.25.
На времени запуска Spring Boot
это сказывается ооочень драматично.
(Ирония ещё в том, что на t2 инстансах EC2 эти 2 vCPU достаются очень дёшево, там на полную катушку можно их юзать лишь где-то 20% времени, что более чем достаточно, чтобы делать быстрые холодные старты, а потом не делать ничего, нагружающего CPU)
512 мегабайт ОЗУ — это сильно много. А «много» — это в облаках значит, что ещё и дорого. Вы что, серьёзно считаете, что каждому экземпляру вашего микросервиса нужно 512 мегабайт памяти? Я, может быть, хочу 1 vCPU и 256 памяти. Но такого нет.
Можно воткнуть в одну задачу/сервис несколько контейнеров. В конце-концов, задачи в ECS — это такие podы Kubernetes. Тогда получится как-то более разумно обойтись с памятью. Но на один сервис в ECS можно натравить только один load balancer. В результате, в одну задачу/сервис вы можете воткнуть лишь один «публичный» контейнер, плюс несколько «приватных» контейнеров. «Приватные» смогут общаться только друг с другом, но не смогут принимать запросы из внешнего мира.
Далее.
В Fargate почему-то сломали то,
что всегда работало в Docker.
Файл /etc/hosts.
В Docker у каждого контейнера появляется уникальное имя.
И это имя является и доменным именем этого контейнера.
И это имя прописывается в /etc/hosts и указывает,
да хоть бы даже на 127.0.0.1.
Это — нормально.
В Fargate нужной записи в /etc/hosts почему-то не появляется.
В результате,
как минимум в Java,
попытки получить адрес локального интерфейса
завершаются
UnknownHostException.
Лечится грязно,
но лечится:
CMD echo "127.0.0.1 $HOSTNAME" >> /etc/hosts && exec java ...
Далее.
Как контейнеру узнать IP адрес,
на котором он запущен?
При запуске в EC2
можно было спросить http://169.254.169.254/latest/meta-data/local-ipv4
и получить ответ.
В Fargate этот фокус не работает.
Зато работает
ECS Task Metadata.
Запросив http://169.254.170.2/v2/metadata
можно узнать почти всё об этой задаче.
Включая набор контейнеров,
и IP адрес,
на котором они все запущены.
private fun queryMetadata(): String {
val query = URL("http://169.254.170.2/v2/metadata")
log.debug("Querying $query")
val metadata = query.openConnection().apply { connectTimeout = metadataConnectTimeout }
.getInputStream().reader()
val host = parseMetadata(metadata)
return host
}
private fun parseMetadata(input: Reader): String {
val json: JsonNode? = ObjectMapper().readTree(input)
return json?.get("Containers")?.get(0)?.get("Networks")?.get(0)?.get("IPv4Addresses")?.get(0)?.asText()
?: "unknown"
}

Fargate не выглядит серебряной пулей. Если у вас много мелких контейнеров, да ещё и каждый обслуживает внешние запросы, то кластер на EC2 окажется существенно дешевле. А развернуть несколько EC2 инстансов с Terraform проблемы не составляет. Или вообще на Lambda/Serverless перейти?..