О ветках
2018-03-17
Допустим, у нас есть Git. Или другая распределённая система контроля версий. Например, мой любимый Mercurial. Такая система, где ветки являются отдельным измерением.
И у нас есть проект, команда и сроки. Проект горит. Сроки горят. Задницы команды тоже горят.
Раз есть ветки, появляется соблазн их использовать. Раз хотим использовать, появляется вопрос «Как?». И куча рекомендаций по бранчеванию от различных источников разной степени доверенности.
Весьма, к сожалению, популярен Git Flow.
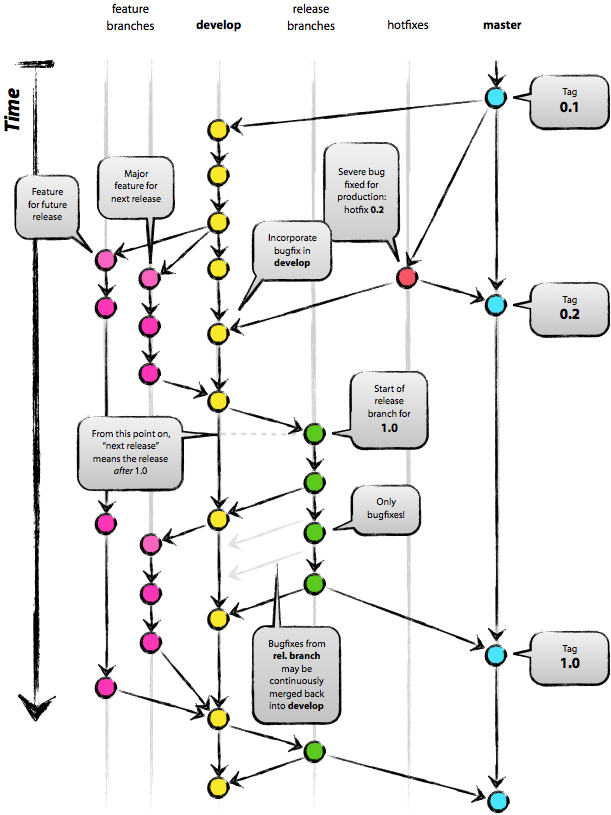
Смотрите,
сколько тут красивых веток.
master,
где лежат аккуратно помеченные тегами
семантического версионирования,
окончательные и бесповоротные,
чудовищно стабильные
релизы.
develop,
где,
якобы,
происходит постоянная ежедневная разработка.
Хотя на самом деле разработка происходит
в feature branches,
которые ответвляются от develop для каждой фичи,
и вливаются обратно,
когда фича готова.
А ещё есть ветки подготовки релиза.
А ещё есть ветка хотфиксов.
Раздолье для любителей наводить порядок.
Спасибо что тут merge, а не
rebase.
А то ведь бывают ещё
чудовищные варианты не только с постоянным rebase,
но и со squash
веток в master.
Министерство правды
завидует этим героям.
Так затирать историю даже они не умели.
Социальный кодинг («Fork you!») добавляет масштабов. Ветки могут являть собой форки репозитория. А изменения оттуда приносятся через Pull/Merge Request и соответствующую процедуру кодоревью. Это уже GitHub Flow получается.
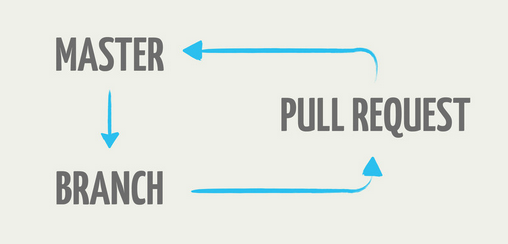
Я не люблю пулреквесты. За то, что это сторонний инструмент, относительно самой системы контроля версий. Самое ценное: собственно ревью и соответствующее обсуждение — хранятся где-то совсем отдельно от историй изменения кода. Это — неправильно. С другой стороны, принимать изменения со стороны только через процедуру ревью — выглядит хорошо.
Но сейчас меня интересует работа одной команды. Нет изменений со стороны. Не нужны пулреквесты. Зато есть очень-очень большая необходимость выкатывать любые изменения как можно быстрее. Чтобы любой чих, любая новая кнопочка, любые новые экранчики были бы сразу видны заказчику. Чтобы можно было честно хвастаться достижениями каждого дня.
Нужно быстро. Поэтому работа одного разработчика должна быть как можно быстрее доступна другим разработчикам. Фронтендер должен как можно быстрее заполучить хоть как-то частично работающий вызов бэкенда. Пользователи библиотеки или сервиса должны как можно быстрее заполучить хотя бы заглушки нужных функций.
И что нам тут дадут ветки?
Разработчик может
запереться в своей ветке
и неделями что-то пилить,
что никто не увидит.
Если он ещё забывает вытягивать изменения
из того же develop,
то он получит ещё и увлекательные два дня мержа
потом.
Ну и смысл такого изоляционизма?
К тому же возникает вопрос
готовности фичи.
Когда мержить в develop?
Когда написан код?
Когда проведено тестирование?
Кем и где протестировано?
Но у нас же всё горит,
и гораздо выгоднее выкидывать на заказчика
не полностью готовую фичу,
а малейшие видимые инкрементальные изменения.
Показать заказчику быстро — довольно просто.
Нужен Continuous Integration/Delivery.
Чтобы,
как только изменения появляются,
сразу собирать и деплоить их.
Но нужно знать,
откуда брать изменения.
Как правило,
это одна ветка.
Хотите — develop.
Хотите — master.
Одна ветка. И изменения в ней должны появляться как можно чаще.
На Lean Pocker было ещё веселее. Там деплоились запушенные коммиты в любую ветку. Суровый «фигак-фигак и в продакшен».

К чему это я?
Не делайте веток.
Фигачьте сразу в develop.
Можно даже фигачить в master.
Оставьте ветки для изоляции окружений.
А если у вас одно единственное окружение,
и оно сразу продакшен,
ну и фигачьте сразу в master.
Не думайте, что если будете все работать в одной ветке, то избавитесь от мержа. Мерж всё равно происходит. С ветками вы их явно мержите. Желательно часто, чтобы ничего не пропустить. А если работать в одной ветке, мерж сам происходит при pull. Постоянно. Всегда. А в этом деле чем чаще — тем лучше.
Боитесь что-нибудь сломать кривым коммитом? Во-первых, кривым должен быть пуш, а не коммит. Если вы что-то сломаете, а следующим коммитом почините, а потом запушите всё вместе, ошибки никто и не заметит. Ибо ваши коммиты остаются только вашими, пока они не запушены. А во-вторых, нефиг деплоить ошибки. Ваш Continuous Integration должен гонять все доступные тесты, и не деплоить тот код, который тесты не прошёл. И должен громко кричать «Ай-ай-ай», и вывешивать ваше имя на доску позора, если вы накосячили.
Говорят, что мастер должен быть стабильным? Не мастер, а последний тег мастера. Расставляйте теги в те моменты, когда считаете, что релиз готов. Деплоить вполне можно и теги. И продолжайте фигачить в мастер. Если у вас вообще есть понятие «релиз». А то в режиме горящих задниц каждый пуш должен быть отрелизен.
Каждая фича должна разрабатываться изолированно? Зачем вам это? Всё равно при мерже всё смешается (в Git). А ФИО разработчика (для blame) никуда не денется. Поставьте номер фичи в коммите, и все тасктрекеры радостно притянут эти коммиты к задаче.
Но ведь нельзя делать фичу так, чтобы не сломать (хотя бы временно) то, что уже есть? Можно! Ещё как можно.
Это вопрос организации кода. И культуры разработки. Тот самый SOLID. Не должно быть общих файлов, куда вынуждены лезть для правок все разработчики (Привет солюшенам VS и прочим IDEшным файлам, не должно им быть в репозитории). Все изменения должны добавлять код/файлы, но (по возможности, конечно) не менять существующие. Стоит избегать дублирования, когда одни и те же изменения приходится вносить в несколько файлов.
Грамотно структурированный код представляет собой дерево. И это дерево должно расти от листьев. Новые функции — это новые листья, классы, файлы. Их можно и нужно писать независимо от всего остального. И тестировать независимо. И всё дерево будет работать как прежде, пока новые листья болтаются без дела, но компилируются, и их тесты проходят.
Чуть позже, когда листик будет достаточно готов, к нему достаточно протянуть веточку. Вписать новую директиву в какой-нибудь конфигурационный файл, добавить определение Spring Bean. И вот оно, пожалуйста, новый код начал работать. Уже протестированный и достаточно стабильный код.
Для такой инкрементальной разработки отдельные ветки не нужны.
И для максимально частых релизов отдельные ветки не нужны. Но это отдельный больной вопрос. Не все разработчики могут придумать, как делать фичу маленькими видимыми кусочками. Чтобы хвастаться каждым маленьким изменением. Не все даже умеют делать маленькие коммиты. Тут надо тренироваться. Наполовину работающий прототип таки лучше, чем совсем ничего.
Но ветки, конечно же, иногда нужны. Иногда случаются эксперименты, которые с высокой вероятностью вообще никогда не сольются с основным кодом. Их разумно делать в отдельной ветке. Иногда совсем не получается запилить фичу, не сломав всё остальное. Такие длинные масштабные изменения тоже разумно делать в отдельной ветке. Но все эти эксперименты и рефакторинги на практике плохо совместимы с режимом горящей задницы :) Это ж надо время, чтобы неспешно всё перетряхнуть.
Фигачьте в мастер! Очень прошу. Это работает. Это не страшно. Это, за счёт уменьшения бюрократических процедур слияния и досмотра, заметно ускоряет доставку фич заказчику.
UPD
https://trunkbaseddevelopment.com/