О MongoDB
2017-09-17
После долгого перерыва я снова столкнулся с MongoDB. Не по своей воле.
В этом перерыве я тыкал разное. InfluxDB, чтобы понять, что Graphite, точнее Whisper, нифига не устарел, и вполне имеет право на жизнь. ClickHouse, чтобы окончательно решить, что для такого рода данных, когда нужно хранить разовые события, привязанные ко времени, а потом делать по ним разную хитрую аналитику, я буду использовать только ClickHouse. Но больше всего возился со старым добрым PostgreSQL, интенсивно заюзывая его модный jsonb.

А вот теперь пришлось снова тыкать MongoDB. В которую пришлось складывать эти самые разовые события, привязанные ко времени, и делать аналитику.
Историческими судьбами в этой Монге сложилась странная схема данных. Есть три коллекции. В одну события складываются как есть, но живут они там только четыре часа. Появилась в Монге такая возможность, индексы с TTL, что сильно удобнее старых capped collections.
В другую коллекцию складываются типа агрегированные данные, сгруппированные по одному из измерений, и собранные за пять минут. На каждые пять минут, на каждое уникальное значение этого измерения — создаётся новый документ. А в нём массив, который пополняется новыми событиями, которые в течение этих пяти минут возникнут.
В третью коллекцию складываются типа агрегированные данные, сгруппированные по другому измерению. Но собранные за неделю. Так же, в массиве. Почему за неделю, неизвестно. Видимо, потому, что размера монгодокумента хватает, чтобы хранить события за всю неделю для каждого уникального значения измерения.
В Монге по-прежнему искусственно ограничен размер документа. И это по-прежнему 16 мегабайт. Помните, зачем? Потому что операции над документами атомарны. И при передаче по сети шестнадцати мегабайт ещё можно сделать вид, что это происходит «атомарно».
Я сразу забраковал эту схему, потому что она подразумевает постоянные апдейты документов. А старый движок Монги, который теперь называют MMAPv1, модифицировал документы «на месте». Если было место, дописывал на месте. Если не было места, ему приходилось копировать документ в конец коллекции и дописывать там. А чтобы место было, он отводил для документа на диске место с запасом. Поэтому этот движок был чудовищно жаден до диска. И очень не любил, когда документы не просто модифицировались, а ещё и увеличивались в размере. Ну прям наш случай.
Над этим движком смеялись все кому не лень. Все разработчики настоящих баз данных. Ибо это были просто memory mapped файлы. В плане скорости это давало некоторые преимущества. Ибо на диске это BSONы, ОС маппит эти BSONы в память, а движку БД остаётся только кидать BSONы из памяти в сокеты и обратно. Но в плане надёжности сохранения данных это было никак. Там, конечно, прикрутили потом журнал. Но это не особо помогло.
И вот теперь, уже вполне солидно, официально и по дефолту у Монги работает другой движок — WiredTiger. Он уже вполне похож на настоящую БД. Он — версионник, MVCC. Это значит, что он никогда не апдейтит «на месте», для него, что insert, что update — одна фигня. Он жмёт данные на диске. Очень хорошо жмёт, кстати. У него есть свой самостоятельный кэш, а не только дисковый кэш ОС.
У WiredTiger тоже есть журнал. Впрочем, журнал всё равно сбрасывается на диск по таймеру. И если в операции записи вы выражаете желание дождаться записи в журнал, ваш запрос действительно будет ждать следующего тика скидывания журнала на диск, и только потом завершится.
«Связанный тигр» — существенный прогресс MongoDB как настоящей базы данных. Рекомендую, если приходится иметь дело с Монгой.

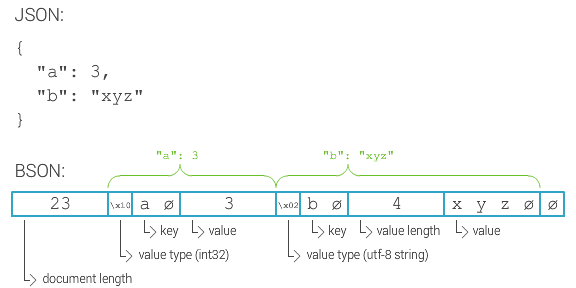
BSON. Продолжаю восхищаться этим изобретением ребят из 10gen. Все разработчики БД, которые, на волне хайпа по NoSQL, добавляют поддержку JSON. Не надо, прошу вас. Добавляйте поддержку BSON.
JSON — это текстовая фигня с сомнительной эффективностью хранения и парсинга, и совсем никакой поддержкой нормального набора типов данных. Там нет целых чисел, и тем более long. Там совсем-совсем невозможно нормально хранить бинарные данные. А бинарные данные у вас всегда будут. Оно вам надо, каждый раз эту фигню парсить и сериализовывать на входе и на выходе, даже если у вас внутри это как-то мегоэффективно хранится, как в jsonb?
BSON — это нормальный эффективный бинарный формат. Тут для каждого значения хранится длина, а значит, можно эффективно пробежаться по документу и извлечь только то, что надо. Тут есть нормальные int и long, и массивы байтов, и timestamp. Как правильно замечает Википедия, какой-нибудь ProtoBuf может быть эффективнее. Но в ProtoBuf нужна схема. А BSON гибок как JSON.
Кажется, Монга научилась использовать несколько индексов одновременно. Но, похоже, предпочитает по старинке брать лишь один индекс для выполнения данного запроса. Дело в том, что индексы, точнее планы запросов, по-прежнему выбираются методом честного соревнования. Если Монга не помнит, какой план запроса был лучшим, она гоняет все возможные планы, и выбирает самый быстрый, и запоминает его на будущее. Просто. Тупо. Эффективно?
Aggregation framework возмужал. Когда-то это была лишь упрощённая и ограниченная замена map-reduce. Но теперь это довольно мощная штука. Заметно мощнее обычных запросов, но почти такая же эффективная. Судя по тому, с какой скоростью в новых версиях Монги добавляют сюда новые возможности, скоро с aggregation framework можно будет делать всё.
Чаще всего aggregation pipeline
собирается из
$match, $project и $group.
$match
— это аналог where.
Здесь можно задать условия выборки документов из коллекции.
Тут работают индексы,
если они есть.
$project
— это аналог выражений после select,
проекция.
Тут всё значительно мощнее,
чем в проекции обычного find().
Можно не только включать и исключать поля.
Можно высчитывать любые выражения
по содержимому документа.
Например,
можно взять,
и сделать $filter
и даже $map
по содержимому массива в документе.
$group
— это аналог group by.
По данному ключу
(а в частности, по ключу null, т.е. для всех документов)
можно собрать агрегацию:
сумму, минимум, максимум,
всё такое.
Есть и другие интересные операторы.
$unwind
позволяет развернуть массив
в виде последовательности документов.
Примерно так,
как это может делать PostgreSQL со своими массивами.
$lookup
позволяет вытащить из другой коллекции
целый документ и воткнуть сюда.
По сути, это join.
Все эти милые операторы собираются именно что в pipeline. Выхлоп предыдущего шага является входом следующего шага. Можно строить длинные цепочки преобразований, чтобы в конце получить лишь одно число, как оно часто и нужно в этих агрегациях :)
Всё это достаточно мощно, что люди всерьёз пишут конверторы из SQL в монговские aggregation pipeline.
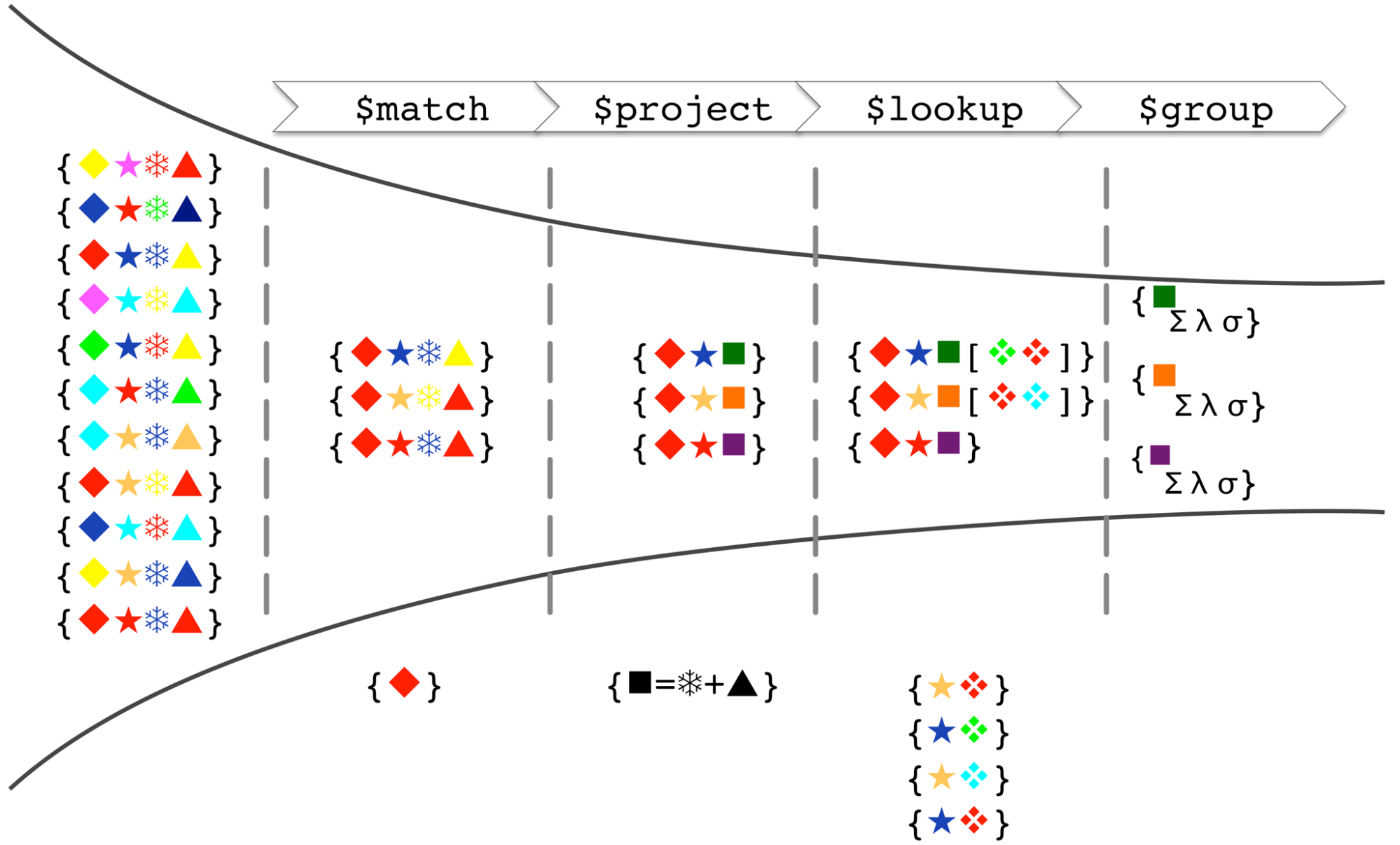
Схема данных, как всегда, имеет значение. Не обольщайтесь schemaless, это вовсе не thoughtless для разработчика. В данном случае засада оказалась в количестве «горячих» документов.
С коллекцией номер раз всё понятно. Мы туда просто инсертим, и всё. Никакие документы не модифицируются.
С коллекцией номер два сложнее. Здесь в течение пяти минут интенсивно обновляются одни и те же документы. Сколько их, определяется мощностью множества значений того измерения, по которому происходит группировка. В данном случае — сотни. Практические замеры показали, что за пару часов модифицируются лишь тысячи документов. Несмотря на относительно большой размер этих документов — десятки килобайт — они все прекрасно помещаются в кэш размером меньше полугигабайта. Поэтому проблем с апсертами в эту коллекцию не было.
Проблемы случились с коллекцией номер три. Агрегаты за неделю, по второму измерению. Средний размер документа тут маленький — килобайты. Хотя встречаются документы, вплотную приближающиеся к заветным 16 мегабайтам. Но вот мощность множества значений этого второго измерения — миллионы. Миллионы «горячих» документов, килобайтного размера. Это, по-хорошему, уже нужен кэш в несколько гигабайт.
Памяти добавили, ядер добавили, IOPS добавили. А не помогало.
Оказалось,
что я избаловался акторами
и прочими прелестями асинхронной обработки.
Даже наша фиговина,
которая должна была в эту самую Монгу пихать события,
хоть и принимала эти события через один сокет в одном потоке,
потом вовсю юзала ThreadPoolExecutor,
раcпихивала задания по очередям,
а потом выполняла в столько потоков,
в сколько нужно.
А вот MongoDB, как, впрочем, и большинство других баз данных, включая PostgreSQL, — не такая. Она — синхронная. Одно подключение — один поток, который выполняет все запросы в этом подключении строго последовательно.
И оказалось, что апдейты этой третьей коллекции по неизвестной причине (возможно из-за необходимости распаковывать и запаковывать документы) очень жрут CPU на сервере. Вставляем через одну коннекцию — упираемся в один поток на сервере, который выжирает лишь одно ядро CPU. И всё медленно.
Ок.
Сделаем четыре потока на нашей клиентской стороне,
нам же всё равно, у нас же ExecutorService.
Получаем четыре коннекции к Монге.
А там — четыре потока на четырёх ядрах CPU,
которые занимаются тем,
чем они хотят заниматься.
Работает?
Работает.
Проблема решена.
Тупой подход: «Тормозит? Добавь потоков!»
— сработал.
Ну,
конечно,
есть нюансы,
которые решились по ходу дела.
По-хорошему,
нужно не давать разным потокам на Монге
лезть в одни и те же документы.
Чтобы не порождать конфликтов и блокировок.
Делается это переупорядочиванием
входящих событий
и грамотным созданием заданий в ExecutorService.

И всё-таки, для этой задачи я бы взял ClickHouse. Прям руки чешутся. Зачем нужны все эти предварительные агрегации? Зачем хранить данные в трёх экземплярах? Если можно за приемлемое время быстренько прогрепать всё, что было за указанный период.
Для сравнения, те же самые события мы, ради Истории, решили записывать в логи и складывать в архив. CPU совсем прохлаждается, памяти не нужно, IOPSов тоже не нужно, ибо последовательная запись в один поток. Нужно место на диске. И тут по компактности WiredTiger побеждает gzip :) Подозреваю, ClickHouse уделает обоих. А извлекать данные будет сильно удобнее, чем с помощью zgrep.
UPD
Ухты. WriteConcern сильно влияет на CPU у MongoDB.
У меня было { w: 0 }, т.е. никаких подтверждений и результатов выполнения.
Заслали команду по сети, и ок.
И работало, со средней загрузкой всех ядер где-то в 60%.
Поставил { w: 1 }, т.е. давай, давай результат выполнения.
И Монга сдохла, CPU не хватило.