О Docker Swarm Mode
2017-04-16
Вернёмся к нашему рою Докеров. Я уже писал про Docker Swarm. Это когда вы можете запустить кучку Docker Engine в кластере ваших компутеров и управлять контейнерами в этом кластере. Тогда речь шла о Docker Swarm, который представляет собой несколько контейнеров, запущенных в обычном Докере. А с версии Docker Engine 1.12 (июль 2016) у нас появился Swarm Mode, непосредственно внедрённый в Docker Engine. Вот до него-то я и добрался.
Напоминаю. Раньше мы брали самый обыкновенный Докер. Запускали в нём, на каждом физическом узле, контейнер с Consul, чтобы иметь единое распределённое хранилище для метаданных нашего кластера. Потом запускали специальный образ Swarm в виде менеджера (тоже, при необходимости, распределённого) и узлов (воркеров) кластера. Этот Swarm контейнер получал доступ к Docker Engine API на каждом узле, где он запущен, путём проброса сокета Докер демона. И клиенты, включая Docker Compose, общались удалённо теперь уже с менеджером Swarm кластера по тому же самому протоколу и API. Т.е. замена одного Docker Engine на кластер Docker Swarm для клиента и пользователя выглядела почти прозрачной.

Теперь всё по-другому. Теперь Swarm Mode — это особый режим работы Docker Engine. И поддерживается он прямо из коробки. И привносит свои нюансы.
Docker развивается стремительно. Версия 1.12 осталась в далёком прошлом. Так же как и версия 1.13. Теперь Докер нумеруется а-ля Убунту, и текущая версия 17.04.0, соответственно, от апреля 2017 года.
Теперь у нас два Докера: Community Edition и Enterprise Edition. Второй от первого отличается, пока что, лишь наличием платной поддержки. Но, например, Community Edition уже официально не поддерживается под RedHat Enterprise Linux.
Допустим, у нас есть две-три машинки, на которые мы хотим водрузить Docker Engine и объединить их в Swarm.
Для начала нам нужно немного поконфигурировать Докер демон.
Учитывая неразбериху со способами инициализации
(даже в Убунту проник systemd,
а в Дебиане до сих пор можно выбирать между systemd и sysvinit),
универсальным способом конфигурирования
становится файл
/etc/docker/daemon.json.
Об этом способе часто умалчивают.
Ну и это JSON,
со всеми его прелестями в виде
отсутствия комментариев
и необходимости не запутаться,
где там должен быть массив,
а где просто значение.
Нам очень может понадобится обращаться к нашему кластеру извне,
а не только с менеджерских хостов.
Поэтому добавляем прослушивание Докер демоном TCP сокета.
При этом надо явно добавить и Unix сокет,
который прослушивается по умолчанию,
иначе локальная команда docker перестанет работать.
"hosts": [
"unix:///var/run/docker.sock",
"tcp://0.0.0.0:2375"
]
Если у нас есть локальный Docker Registry, и мы поленились настраивать на нём HTTPS, нам нужно включить этот Registry в список доверенных.
"insecure-registries": [
"192.168.2.25:5000"
]
Наконец, чтобы как-то пометить наши Докеры, чтобы потом правильно раскидать по ним сервисы, мы можем захотеть указать в конфиге метки. Хоть метки — это ключи и значения, в конфиге они задаются просто как строки.
"labels": [
"backend=yes",
"worker=yes"
]
После изменения конфига,
очевидно,
нужно перезагрузить демон.
Например посредством service docker restart.
Теперь можно создавать Swarm.
На той машинке,
которая станет одним из менеджеров кластера,
и с которой вы хотите начать это безобразие,
нужно выполнить команду.
Внимание,
с появлением Swarm Mode
у простой и понятной команды docker
появилось очень даже много подкоманд.
Сейчас будем знакомиться с
docker swarm.
$ docker swarm init --advertise-addr 192.168.2.12
Swarm initialized: current node (2epmgc34aa0o7x6z6ho7v8u66) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join \
--token SWMTKN-1-0pcqn90yv70657tpbepxaqjw3et3ihcalpbee8ndzifxg5zncn-5r3zjl1evea481i3mzetnwoff \
192.168.2.12:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
Вам нужно указать адрес, по которому данный узел Swarm будет доступен для других узлов. Это довольно важно, если у вас есть несколько интерфейсов, например, для обмена трафиком внутри датацентра.
Узел,
на котором мы запустили docker swarm init,
становится (первым) менеджером будущего кластера.
И нам дают некий токен,
который нужен,
чтобы подключить к этому кластеру другие узлы.
Команда не идемпотентна. Попытка проинициализировать Swarm повторно приводит к ошибке.
$ docker swarm init --advertise-addr 192.168.2.12
Error response from daemon: This node is already part of a swarm. Use "docker swarm leave" to leave this swarm and join another one.
С одной стороны,
понятно почему.
С другой стороны,
такая ошибка затрудняет автоматизацию.
Можно задать ключ --force-new-cluster true,
тогда каждый раз будет создаваться новый кластер,
это тоже не то,
что хотелось бы.
А вот ключа игнорировать наличие кластера — нет.
Итак, у нас, оказывается, есть два типа узлов. Менеджер — с него можно управлять кластером. Менеджеров может быть несколько, они устраивают выборы, определяют кворум и всё такое. По умолчанию узел-менеджер также является и воркером, но можно создать и чистого менеджера. Воркер — запускает на себе контейнеры и всё такое. Чтобы присоединить к кластеру воркера или менеджера, используются разные токены.
Токен для присоединения воркера пишется в выхлопе docker swarm init.
Это вариант для человеков.
Для автоматизации вам нужно просто вывести токен.
Это можно.
$ docker swarm join-token worker -q
SWMTKN-1-0pcqn90yv70657tpbepxaqjw3et3ihcalpbee8ndzifxg5zncn-5r3zjl1evea481i3mzetnwoff
Чтобы присоединить другой Docker Engine к этому Swarm, его нужно присоединить по токену. Нужно ещё указать адрес одного из менеджеров.
$ docker swarm join --token SWMTKN-1-... 192.168.2.12:2377
Эта команда снова не идемпонентна. Попытка присоединиться к кластеру, если узел уже в кластере, приводит к ошибке.
Узлы кластера общаются между собой по кучке портов. TCP порт 2377 — обращение к менеджерам. TCP и UDP порт 7946 — обмен метаданными между узлами. UDP порт 4789 — overlay сеть между узлами. А если мы собираемся использовать зашифрованный overlay, нужно разрешить ещё и протокол 50 (ESP). Но вроде как дополнительно шифровать overlay не очень нужно, ибо, если верить документации, весь трафик между узлами и так шифруется.
Чтобы разобраться с узлами кластера
у нас добавилось семейство команд
docker node.
Например, можно узнать,
сколько у нас узлов в кластере и каково их здоровье.
$ DOCKER_HOST=tcp://192.168.2.12:2375 docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
5qt2all7nm1sapczihel6crn7 * docker2 Ready Active Leader
tbojo6bwq3p9rzxf1gzni1ig6 docker1 Ready Active
Это команды,
которые работают только в Swarm Mode,
и работают только на узлах-менеджерах.
Но мы не зря разрешали удалённый доступ к Docker Engine.
Можно выполнить команды удалённо,
указав адрес менеджера в переменной окружения DOCKER_HOST.

Docker Swarm у нас вроде готов.
Попробуем взять docker-compose.yml и развернуть его.
$ DOCKER_HOST=tcp://192.168.2.12:2375 docker-compose up
Compose does not use swarm mode to deploy services to multiple nodes in a swarm. All containers will be scheduled on the current node.
To deploy your application across the swarm, use `docker stack deploy`.
Что?
Ну да. Swarm Mode — это вам не старый добрый Swarm на контейнерах. Swarm Mode не совместим ни с чем, кроме себя самого. А Docker Compose теперь пригоден только для запуска кучки связанных контейнеров на одном хосте (локально).
Вместо docker run у нас теперь docker service create.
Вместо кучи других команд,
которые работают только на одном Докере,
у нас теперь целая куча команд
docker service,
работающих в Swarm Mode.
Сервисы в Docker Swarm — это немножко покруче
просто контейнеров,
запущенных через docker run.
Это, в общем-то,
сервисы в понимании Docker Compose.
Можно крутить их количество в кластере
с помощью docker service scale.
Можно смотреть,
на каких узлах кластера сервис развёрнут:
docker service ps.
А самое клёвое,
можно на лету менять настройки сервисов,
например,
проброшенные порты,
с помощью docker service update.
Но мы же не хотим забрасывать наши любимые
и тщательно выверенные docker-compose.yml?
Не заменять же их шелловыми скриптами с docker service?
Слава хипстерам,
создатели Докера на нас не забили,
и у нас есть docker stack.
Тут всё странно.
Стек — это множество сервисов.
docker stack deploy разворачивает это множество в Swarm
согласно описанию в формате
Distributed Application Bundles.
А получить этот DAB файл
(который на самом деле JSON)
из docker-compose.yml можно с помощью docker-compose.
Зачем ещё один формат?
Но docker stack deploy умеет работать и с docker-compose.yml.
$ DOCKER_HOST=tcp://192.168.2.12:2375 \
docker stack deploy --compose-file docker-compose.yml ${PROJECT}
Тут надо явно указать название стека, который вы разворачиваете. В Docker Compose это называлось проектом и по умолчанию бралось из имени текущего каталога.
Но и docker-compose.yml тут должен быть не простой.
Он должен быть версии 3 или выше
(сейчас крайняя версия 3.2).
Основное отличие версии 3 от старой доброй версии 2 —
свойство deploy у каждого сервиса.
docker-compose это свойство игнорирует,
а docker stack deploy как раз использует.
В deploy как раз и указываются некоторые штуки,
влияющие на то,
как сервис воткнётся в Swarm.
Можно ограничить узлы,
на которых будет запущен сервис.
Можно задать режим развёртывания.
version: '3'
services:
nginx:
image: nginx
deploy:
placement:
constraints:
- 'engine.labels.frontend == yes'
mode: replicated # maybe 'global' is better here
ports:
- '80:80'
networks:
- frontend
worker:
image: worker
deploy:
placement:
constraints:
- 'engine.labels.worker == yes'
mode: replicated
networks:
- frontend
networks:
frontend:
deploy.placement.constraint — это ограничения.
engine.labels.* — это метки,
что мы задали в daemon.json,
т.е. метки Docker Engine.
Есть ещё метки узлов.
Они навешиваются через docker node update,
который нужно выполнить,
соответственно,
на менеджере кластера.
Опять неудобно для автоматизации,
нужно ходить на менеджера,
но знать имена всех остальных узлов.
Метки узлов доступны для проверки как node.labels.*.
Синтаксис ограничений,
по сравнению со старым Swarm,
изменился.
deploy.mode — это режим развёртывания.
Пока их два.
replicated — это по умолчанию.
Сервисов будет запущено столько,
сколько скажете сразу при создании,
либо до скольки отмасштабируете через docker service scale.
И размазаны их контейнеры будут по кластеру ровным слоем,
учитывая ограничения,
конечно.
global — будет запущен ровно один
(не более)
сервис на каждом узле кластера,
учитывая ограничения.
Сети, указанные в docker-compose.yml здесь
по умолчанию будут overlay.
Т.е. будут спокойно работать
между узлами кластера.
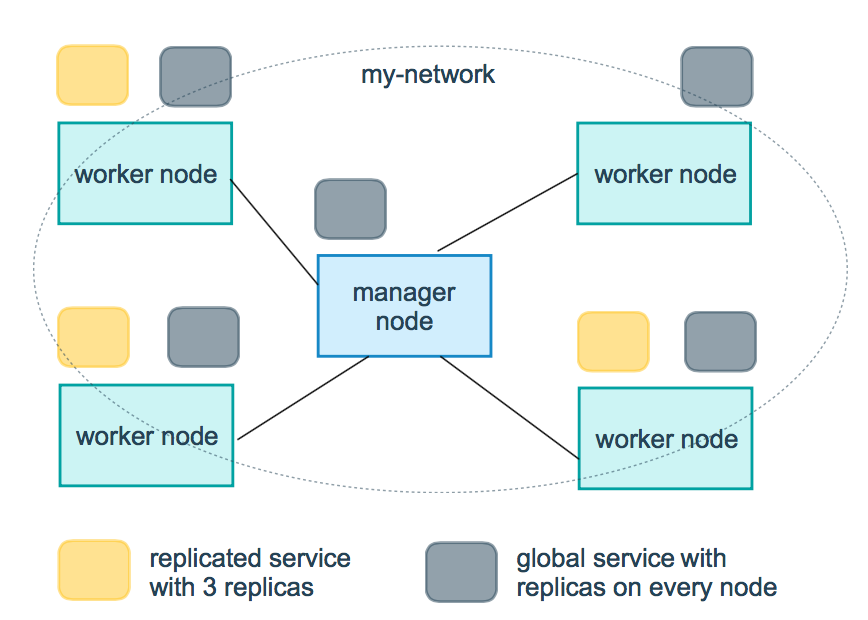
С сетью всё вообще очень интересно.
Давным-давно,
как вы помните,
нужно было проставлять linkи между контейнерами,
и имя линка появлялось в /etc/hosts.
Теперь внутри Docker Engine у нас есть DNS сервер.
Linkи не нужны,
достаточно, чтобы сервисы были в одной сети.
А одна сеть на docker-compose.yml и так формируется по умолчанию.
Имена сервисов резолвятся в IP адреса в этих внутренних сетях.
А если сервисов отмасштабировано несколько экземпляров,
то одно доменное имя будет резолвится на несколько IP адресов.
Обычный round robin DNS.
И всё это справедливо для нынешнего Docker Compose.
В Swarm Mode пошли чуть дальше. Теперь каждому сервису выдаётся один виртуальный IP (VIP). Доменное имя сервиса резолвится в этот один единственный VIP. А трафик на этот VIP уже магическим образом распределяется между актуальными контейнерами (уже со своими IP). Понятно, зачем это надо. В зависимости от нагрузки на узлы кластера, может потребоваться более тонкая балансировка, чем простой round robin. Но при желании можно вернуться на старое поведение, без VIP, а с множеством IP адресов на одно доменное имя сервиса.
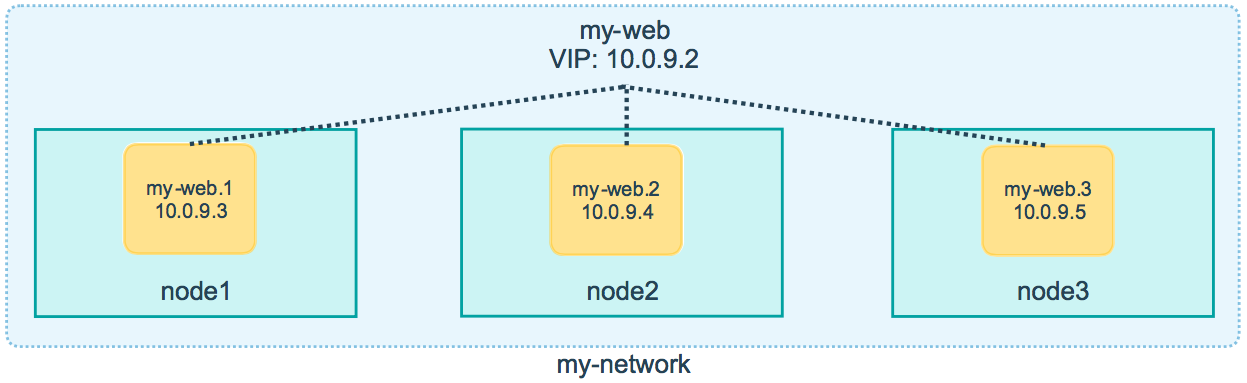
Серьёзные изменения произошли в публикации портов. Синтаксис остался прежним. А вот смысл теперь совсем другой.
Раньше,
когда мы публиковали порт,
это означало,
что Docker Engine на том хосте,
где запущен контейнер с данным сервисом,
начинал слушать указанный порт
и пробрасывать соединения в контейнер.
Но мы не можем точно контролировать,
на каком узле будет запущен сервис.
В результате нам
либо нужно запускать сервисов заведомо столько,
сколько узлов в кластере,
убеждаться,
что они запустились действительно на всех узлах,
и использовать внешний балансер.
Ну,
по сути,
делать то,
что теперь нам гарантирует deploy.mode = global.
Либо наоборот,
внедрять балансер,
например,
HAProxy,
в виде сервиса,
прибивать его,
с помощью ограничений,
к определённому узлу,
весь внешний трафик
направлять на этот узел,
а балансировать уже внутри Докера.
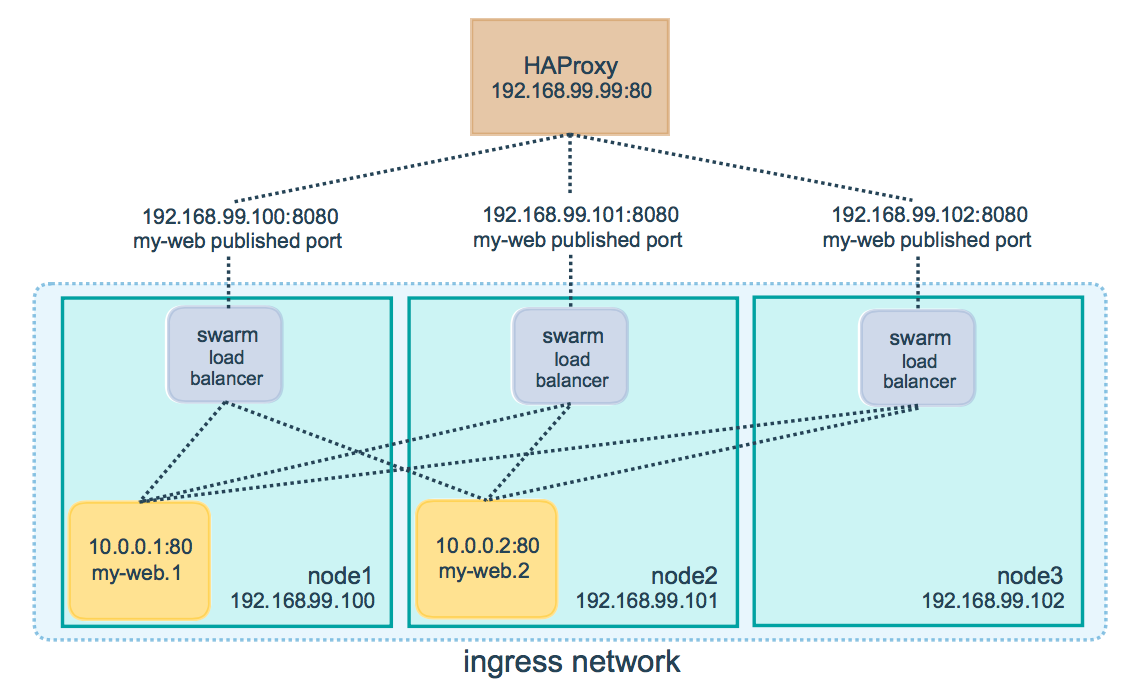
Теперь этих мучений во многих случаях можно избежать. Потому что в Swarm Mode есть Ingress Routing Mesh. Если вы публикуете порт в каком-то сервисе, этот порт начинает слушаться на всех узлах кластера. И принимать внешний трафик можно на любом узле кластера. Даже том, где контейнер с данным сервисом в данный момент не запущен. Swarm магическим образом всё это дело смаршрутизирует и сбалансирует до нужного контейнера. Круто? Круто.
Но есть нюансы. Так как эти меши, это, по сути, трансляция адресов, ваше приложение в контейнере видит не реальный IP адрес клиента, а некий адрес во внутренней сети Докера.
Если вам нужно доставить IP адрес клиента
до вашего сервиса,
у вас есть два пути.
Либо мы снова добавляем внешний балансер,
и пусть он каким-то образом внедряет IP адрес клиента.
В случае HTTP это может быть
дополнительный заголовок
X-Forwarded-For.
Для других протоколов можно использовать
HAProxy Proxy protocol.
Либо можно отключить этот меш
для данного сервиса,
и использовать обычный проброс портов,
работающий только на одном хосте.
Это должно хорошо работать для global сервисов.
Чтобы можно было указать режим публикации портов, синтаксис всё-таки изменился. Можно воспользоваться возможностью обновлять сервисы.
$ docker service update ${PROJECT}_nginx --publish-add mode=host,target=80,published=80
А можно сразу прописать новый хитрый синтаксис
в docker-compose.yml.
ports:
- target: 80
published: 80
protocol: tcp
mode: host
Последний вариант требует версии compose файла аж 3.2 и будет работать только в только-только релизящемся Docker Engine 17.4.0.
Ну что ж. Docker Swarm Mode — состоявшийся факт. Оно не совместимо с предыдущим Swarm, который, тем не менее, продолжает поддерживаться.
Создание Swarm кластера существенно упростилось. Хотя не очень удачные неидемпотентные команды и необходимость копирования токенов, не сильно помогают в автоматизации развёртывания.
Появилось оооочень много новых команд docker.
Старые команды тоже остались,
но они не будут работать со Swarm Mode.
Docker Compose сократили до локального инструмента.
Вместо него предлагают использовать новые команды docker,
в частности docker stack deploy.
Однако, весьма полная совместимость на уровне compose файлов осталась.
Mesh роутинг и VIP здорово упрощают развёртывание и разработку в типовых случаях (http микросервисы?). В сложных случаях без явного балансировщика всё равно не обойтись, либо внешнего, либо внутри Swarm.
UPD
Ещё один момент.
В deploy можно указать параметры перезапуска сервисов.
По умолчанию Swarm пытается запустить нужное количество контейнеров,
всегда, и после ребута узлов.
Если контейнер падает, снова запускается новый экземпляр.
А несколько трупиков от предыдущих запусков или попыток запуска сохраняются.
Если в образе ошибка,
и контейнер падает всегда,
получается вечный цикл:
запуск, падение, подчистка старых трупиков, снова запуск.
Выглядит это очень странно,
и нужно успеть вскрыть трупики,
чтобы понять причину падения.