О ClickHouse
2017-03-05
А у нас на продакшине ClickHouse. А у вас? Вот так вот получилось. Ну и продолжается, само собой.
![]()
Задача была такая. Есть юзеры. Они генерируют события. Не буду распространяться, какие именно события, дабы не нарушать NDA. По каждому событию сейчас у нас получается семнадцать параметров. Причём два из них — массивы строковых значений. Событий генерируется довольно много: от половины до даже пяти миллионов за сутки. В пиковые моменты случается до ста пятидесяти событий в секунду. И эти числа ещё собираются расти по мере появления новых пользователей.
По этим событиям нужно строить, казалось бы, обычные аналитические штуки. Самые популярные (часто встречающиеся) значения параметров (в том числе из массивов) за последние двадцать четыре часа, семь и тридцать дней. Графики изменения параметров за те же периоды. Просто счётчики событий. Всё это, выбранное и сгруппированное по значениям других параметров. Что-то порядка десятка подобных отчётиков, чтобы ещё обновлялись по возможности в реальном времени. И безо всякой гарантии, что новые отчёты внезапно не понадобятся.
Но кроме этого, все эти события, все семнадцать параметров, надо изображать как они есть, в виде журнала, и выгружать в CSV. Заостряю на этом внимание, потому что это требование несколько противоречит предыдущим. Как оказалось, одно дело — это составлять агрегированные метрики по исходным данным на лету. А совсем другое дело — хранить исходные логи, как они есть.
Подход номер раз. Я сказал: это ж timeseries данные. Давайте возьмём InfluxDB и будем складывать всё туда. Тем более, что Инфлюксина вроде стала более-менее стабильной (только только вышла версия 1.0), и обросла солидной инфраструктурой.
Впрочем, инфраструктурой мы так и не воспользовались. А в InfluxDB совершенно разочаровались. Да, она может хранить всё, что нам нужно. Да, она может делать нужные нам запросы. Теоретически. Но на практике не всё так просто.
InfluxDB не умеет делать достаточно сложные аналитические запросы. Напрямую, одним запросом. Нужно собирать промежуточные агрегации и строить результат в несколько шагов. Либо во временных таблицах, что медленно и требует памяти и диска. Либо формировать агрегации на лету с помощью так называемых Continuous Queries, или даже с помощью сложного и мощного Kapacitor, что требует очень хорошего знания самой InfluxDB и её языка запросов, хорошего понимания того, что нужно получить и посредством каких преобразований, ну и снова требует памяти, диска и CPU. Может, был бы у нас аналитик данных, он бы побаловался. Но мы, простые смертные программисты, задачу многошагового агрегирования не осилили.
А ещё оказалось, что InfluxDB имеет своё понимание временных промежутков, от которого никуда не деться. За текущие и прошлые сутки, недели, месяцы проагрегировать — пожалуйста. За последние (от текущего момента, а не от полуночи) двадцать четыре часа — никак.
InfluxDB не даёт никакой гарантии касательно того, когда только что вставленные данные появятся в результатах запросов. Eventual consistency во всей красе. Жутко неприятно только, что даже безо всякой нагрузки этот интервал может составлять минуты.
Ну а добила нас InfluxDB непомерными и непредсказуемыми требованиями к оперативной памяти. Даже на небольших данных, в самом начале проекта, сложные аналитические запросы приводили к выеданию гигабайт ОЗУ. Выглядело это так. Всё работет, данные вставляются. Открываем страничку, где рисуются наши отчёты. И парочка самых тяжёлых отчётов зависает на минуты, а потом валится с ошибкой. InfluxDB в этот момент съедает всю ОЗУ, потом весь свап, и потом запрос таки падает от нехватки памяти. Спасибо, что вся Инфлюксина не падает, а только поток тяжёлого запроса. Мы подумали, что платить за сервера с тридцатью двумя или шестидесятью четырьмя гигабайтами ОЗУ для обработки жалкого миллиона (на тот момент) записей — это слишком жирно. Тем более, что непонятно, хватит ли и этих гигабайт.

Подход номер два.
PostgreSQL.
Попробовали,
проверили,
потестировали.
Оказалось,
что старый добрый реляционный SQL
прекрасно умеет все те аналитические запросы,
которые оказались не по зубам InfluxDB.
Прямо поверх исходной таблицы с журналом событий.
SUM, GROUP BY, ORDER BY, LIMIT.
Джойны таблицы с самой собой,
точнее по массивам внутри данных.
Чтобы не париться со схемой,
юзали jsonb.
Индексы правильные построили.
Всё прекрасно работало
и память не жрало.
Postgres — прекрасен.
Так всё жило несколько месяцев. А пользователей становилось всё больше. И запросы стали выполняться всё медленнее. Уже минутами. Окончательный ахтунг случился, когда запросы стали падать из-за нехватки места на диске. Оказывается, Postgres создаёт временные файлы, что вполне ожидаемо. Но что эти файлы вполне могут быть размером больше десяти гигабайт — внезапно.
На популярных VDS
дисковое пространство денег стоит.
А сто сорок миллионов записей
стали занимать сто двадцать гигабайт диска.
Многовато.
Как освободить место?
Ну давайте сдампим старые данные в файлики,
и удалим их из Postgres.
Ок.
Как положено,
сделаем vacuum analyze.
Ах, обычный вакум не возвращает дисковое пространство операционной системе,
он просто помечает место в уже используемых страницах
как свободное.
Вставлять ещё без дополнительного пожирания диска можно,
но места не добавилось.
Может, надо сделать vacuum full?
Чорт, ему нужно свободное место,
чтобы полностью перекопировать таблицу.
А места уже нет.
Пат.
Почему запросы стали медленными?
Потому что транзации.
По идее,
даже банальному count(*)
должно быть достаточно лишь индекса,
чтобы дать ответ.
Но у нас ещё и интенсивная вставка происходит.
А значит,
помимо индекса,
надо сверяться с visibility map
для каждой строки,
чтобы убедиться,
что данная строка действительно видна в данной транзации.
Получается слишком много IO
для выполнения запроса.
Получается слишком медленно.

Проблемы с Postgres, спасибо ему, начались не внезапно. Мы начали смотреть по сторонам, чтобы понять, что делать. Думали о Cassandra. И тут случился ClickHouse.
У ClickHouse замечательная документация. Там всё написано, как начать и продолжить.
Идея такая, в каком-то смысле противоположная текущему подходу к timeseries, что применяется в том же InfluxDB. Во-первых, мы не знаем, какого рода отчёты нам понадобятся. Во-вторых, если отчётов потребуется слишком много, придётся хранить много агрегированных данных, которые многократно дублируют исходные данные. Их объём может быть значительным. Так почему бы не вспомнить тот же SQL и старый добрый OLAP? Пусть у нас будут только исходные данные, но в виде, удобном для разных хитрых манипуляций. А если мы сможем хранить данные достаточно компактно, чтобы уменьшить IO, то сложные запросы ещё и выполняться будут достаточно быстро.
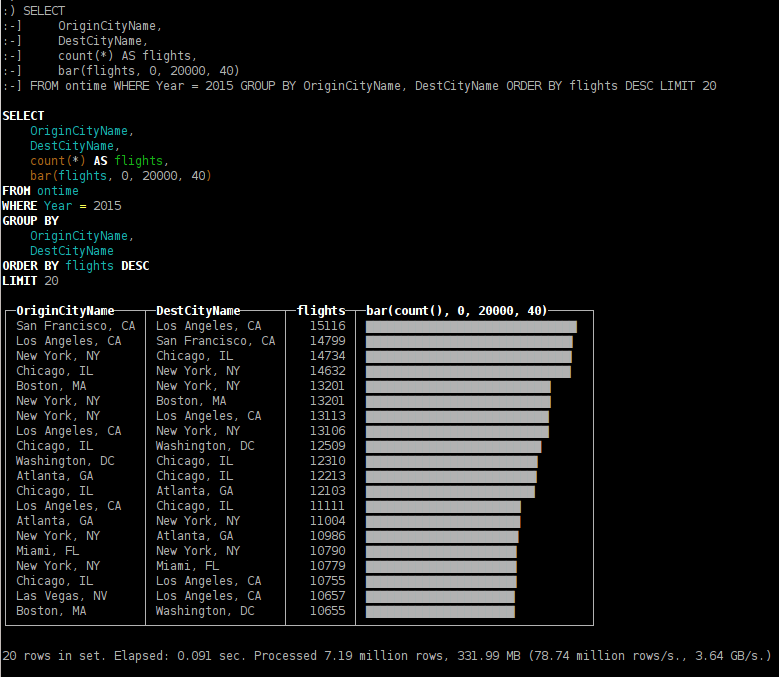
Вот такой он, ClickHouse. Это колоночная база данных. Колонки данных физически хранятся в разных файлах. Для аналитики это важно, так как в одном запросе, как правило, используются далеко не все колонки. Вот которые не используются, можно не читать. К тому же колонку можно очень хорошо сжать, если там будут повторяющиеся значения. И Кликхауз жмёт.
В самом популярном движке таблиц Кликхауса MergeTree
данные упорядочены по дате
и по первичному ключу.
И объединяются в кусочки по ключу.
Каждый кусочек представлен на диске каталогом,
в котором лежат файлики.
По паре файликов (данные и индекс?)
на каждую колонку.
Когда мы вставляем,
создаются новые кусочки.
А потом они в фоне объединяются.
Эти файлы на диске очень не похожи на то, что обычно бывает в базах данных. Какой-то блокнот с зипом. Надеюсь, эта конструкция неприхотлива к потере отдельных файлов.
Сжимает Кликхаус потрясающе. То, что в Постгресе занимало сто двадцать гигабайт, в виде загзипованного csv дампа занимало пять гигабайт, будучи вставлено в Кликхаус, заняло два(!) гигабайта на диске.
Зато нет транзакций, невозможны апдейты, а удалять данные можно только партициями, т.е. кусками за целый месяц. Ну и фиг со всем этим, не для того держим.
Запросы, которые в Постгресе затягивались на минуты, в Кликхаусе выполняются за пару секунд. На том же объеме данных. Он ещё гордо показывает какое чудовищное количество гигабайт он читает при выполнении запроса. Эквивалетный объем несжатых данных, конечно. Маркетинг.
Да, на простеньких запросах Постгрес быстрее, он может ответить за миллисекунды. Кликхаус редко отвечает быстрее сотен миллисекунд.
Есть репликация.
Для этого нужен ZooKeeper.
Раз уж разводим зоопарк разных БД,
нужно за ним присматривать.
Для репликации имеется отдельное семейство движков БД,
например, ReplicatedMergeTree.
Получается,
что реплицируются отдельные таблицы.
Движок через ZooKeeper координирует куски данных,
имеющиеся в каждой реплике.
И реплики обмениваются пропущенными кусками.
Соответственно,
получается мультимастер.
Писать можно в любую реплику,
данные появятся в обеих.
Получается,
что тут на репликах и запись масштабируется.
Есть шардинг.
Тут тоже нужен ZooKeeper.
Для шардинга есть отдельный движок таблиц
под названием Distributed.
Он сам не хранит данные,
а берёт их из других таблиц-шардов,
доступ к которым осуществляется через этот Distributed.
Это могут быть любые таблицы,
в том числе и реплицируемые.
С ключом шардинга ClickHouse обращается весьма вольно.
Для чтения он вообще не нужен,
потому что запрос всегда будет направлен во все шарды,
а финальный результат будет собран на хосте,
где живёт Distributed таблица.
Для записи ключ нужен только чтобы обеспечить
равномерное распределение данных
между шардами.
Или не обязательно равномерное,
можно указать разные веса разным шардам.
А можно вообще шардить вручную,
напрямую записывая в скрытые под Distributed таблицы.
Кликхаус всё стерпит.
Мы до репликации и шардинга ещё не дошли, то технически к этому готовы. Хотя, такими темпами до ста двадцати гигабайт данных в Кликхаусе ещё не скоро доберёмся.
Подключаться к Кликхаусу можно как минимум двумя способами.
Родной консольный клиент clickhouse-client использует
некий бинарный протокол.
Зато, похоже,
только он умеет показывать симпатичный прогресс бар
во время выполнения запроса.
Кстати, этот консольный клиент —
самая весёлая консоль,
что я видел,
порадует вас смайликами.
Ещё есть HTTP протокол,
можно просто курлить.
И есть JDBC драйвер,
который,
впрочем,
почему-то ходит на сервер тоже через HTTP.
Случилось с ClickHouse и штуки три (пока три) неприятных момента. Документацию читать внимательно надо.
Во-первых,
у JDBC драйвера стоит очень
маленький таймаут
на подключение к серверу.
Пятьдесят миллисекунд.
Этого,
конечно,
хватит для локальной сети
или даже одного датацентра.
Но подключиться к серверу
на другом берегу Атлантического океана
уже не получится.
Лечится указанием property при создании DataSource или Connection
по имени connection_timeout
с более вменяемым значением.
Во-вторых, Кликхаус очень не любит одиночные инсерты. Ему подавай батчи. Официальная документация даже говорит, что одиночные инсерты, пожалуйста, не чаще одного в секунду на одном сервере. Оно понятно, почему. MergeTree нужны достаточно большие куски, чтобы заняться их слиянием. Постоянно сливать отдельные строки выходит слишком дорого. Мы сдуру попробовали вставлять наши события по одному. Кликхаус нещадно насиловал диск на запись, и упорно задерживал инсерты. Т.е. в логе писал соответствующее сообщение. И вставляемые данные появлялись в запросах с дикой задержкой аж в часы. В отличие от InfluxDB эта задержка прямо коррелирует с нагрузкой на сервер.
Пришлось расчехлить знание многопоточного программирования на Java, и собирать батчи на нашем клиенте. Асинхронно, по тысяче строк за раз, но не реже раза в тридцать секунд, и не забыть записать всё накопленное при шатдауне системы. Почему эта буферизация не сделана в JDBC драйвере? Или даже на сервере? Та же Кассандра спокойно пишет данные в журнал, и лишь потом с ними разбирается. Похоже, надо смириться с тем, что при вставке в Кликхаус данные могут быть потеряны. Ну а пока с батчами всё ок. Один сервер держит нашу нагрузку.
В-третьих, Кликхаус не очень приятно работает с датами. Слишком легко облажаться. Дату-время он хранит в виде юниксового таймстампа. Прощай миллисекунды. Здравствуй, проблема 2038 года. Но также ClickHouse готов принимать в качестве даты и времени строки в формате ISO 8601. При этом никаких таймзон и даже смещений от UTC не предусмотрено. А для конвертации он использует в лучшем случае таймзону, прописанную в конфиге, а в худшем случае, системную таймзону, подхваченную при старте сервера.
В консольке Кликхауса это не так страшно,
ибо Кликхаус очень строго относится к типам данных
(даже строже, чем Постгрес),
поэтому,
чтобы использовать строку как дату,
нужно явно использовать функции toDate() и toDateTime()
(и даже Date автоматически из DateTime не выводится).
И вроде как консолька по умолчанию
использует таймзону сервера.
А вот JDBC драйвер спокойно съедает String
там, где ожидается DateTime.
И поди пойми,
в какой момент происходит конвертация,
и в каком часовом поясе,
клиента или сервера.
Надо переходить на long.
При переходе из Postgres пришлось распотрошить jsonb в отдельные колонки. Но у нас же колоночная база. Если потом понадобится добавить ещё одну колонку, это же будет очень дёшево, правда?