О слоях
2015-10-02
У людоедов есть слои. Как у лука. И у программ есть слои. Тоже как у лука. Или как у тортика. Однако, в последнее время, под натиском моды на распределённые системы и микросервисы, все как-то позабыли про архитектурные слои монолитных приложений. Может быть, зря. Оказывается, в каждой уважающей себя компании есть свои правила построения этих самых слоёв.
У нас тут, в потуге обучения стажеров, родилось такое видение этих слоёв типового веб приложения.
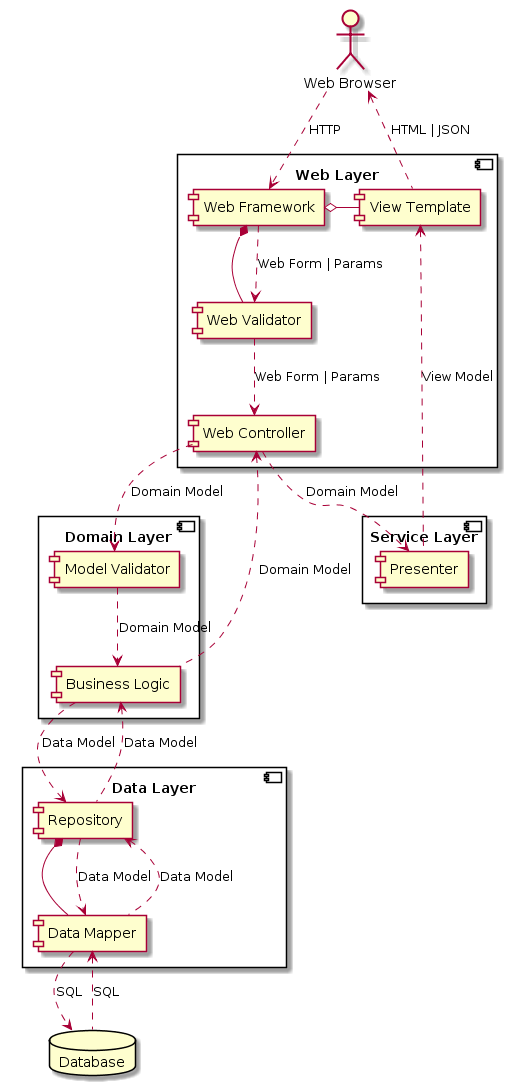
Всё как в лучших домах. Есть веб слой. Есть слой предметной области, содержащий бизнес логику приложения. Есть слой доступа к данным. Где-то сбоку есть слой сервисов, в данном случае какой-то маленький. Между слоями бегают модельки. В каждом слое модельки могут быть своими.
Из великого и могучего Веба к нам приходит HTTP запрос. Ловится он некоторым сервером-контейнером, внутри которого крутится наше приложение. В случае Явы это будет, скорее всего, сервлет-контейнер.
Наше приложение, чтобы не возюкаться с деталями HTTP, пользуется некоторым фреймворком. Например, Spring. Фреймворк позволяет работать с параметрами HTTP запроса или даже целиком с засамбиченными формами. Также он может провести некоторую первичную валидацию данных: наличие и тип полей и т.п.
Параметры или формы попадают в контроллер. Он решает, что с этим делать и как жить дальше. Он что-то дёргает у бизнес логики.
Бизнес логика ничего не знает ни про веб, ни про запросы, ни про формы. Она работает со своей моделью предметной области, представленной чаще всего кучкой классов. Правильность состояния модели может проверяться специальным отдельным валидатором.
Бизнес логика внезапно захочет сохранить какое-нибудь состояние. Для этого она обратится к слою данных. Там есть репозиторий, который умеет запихивать объекты в базу данных. Для преобразования одного в другое имеется маппер. Слой данных может манипулировать своей собственной моделью, отличной от модели предметной области, — набором объектов, которые нужно сохранять в БД. Ну а сама БД у нас, как правило, работает через SQL.
Потом данные надо извлечь из БД. Посредством того же SQL. Вытащить через маппер и репозиторий, чтобы получить какие-то удобоваримые объекты.
Бизнес логика с этими объектами может что-то поделать, родить какие-то свои объекты предметной области. И результат нашего запроса, в виде нормальных объектов, возвращается контроллеру.
Теперь данные нужно отобразить. Надо сконвертировать значения предметной области в нечто человекопонятное и человекочитаемое. Этим занимается презентер. Он, например, переводит даты в строку, форматирует числа, осуществляет интернационализацию текстовых сообщений, и прочее, и прочее. В результате получается отдельный набор данных — модель представления.
Модель представления — набор строчек, которые надо отобразить, — с помощью шаблона преобразуется в обычный HTML, который передаётся назад браузеру и отображается им как обычная веб страница. Или преобразуется в JSON, если у нас тут какое-то хипстерское API и нам нужно вернуть результат в машиночитаемом виде.
Радует, что входящий запрос, обработка и запись в БД идут явно несколько по другому пути, чем чтение из БД, обработка и выдача ответа. Это такой легкий наношажок в сторону CQRS.
Можно долго спорить: должен ли слой сервисов быть отдельно от слоя предметной области, стоит ли выделить контроллеры в отдельный слой, должен ли репозиторий называться репозиторием, почему нельзя использовать везде одну и ту же модель, и т.п. Но это всё не важно. Это лишь некое обобщение реальной практики разработки. Философия. В реальности, на каждом отдельно взятом проекте, всё будет немного иначе.
Ну а еще более эпичное обобщение сделал дядя Боб (он же Роберт Мартин) аж в 2012 году. Называется это The Clean Architecture.
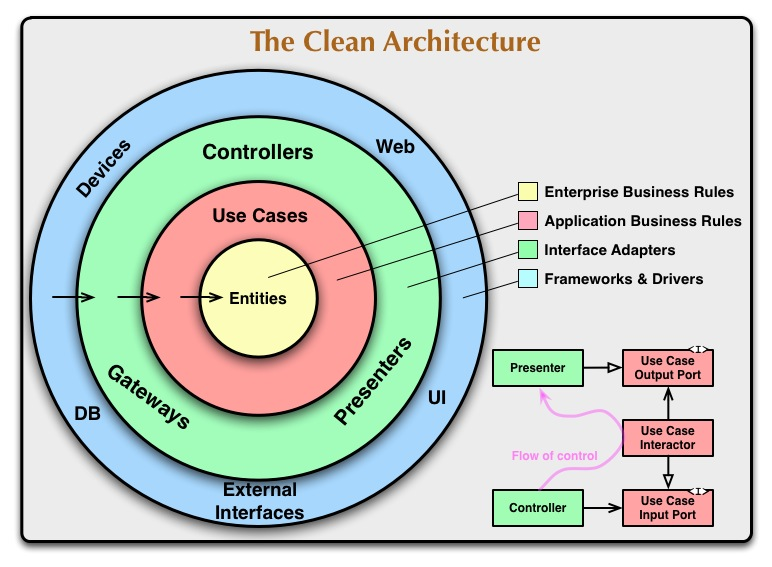
Суть в том, что приложение у нас слоистое. Как лук. В серединке живут самые основные и базовые сущности и правила нашей предметной области. Поверх них строятся какие-то сценарии использования — что, зачем и как нужно делать с сущностями предметной области, чтобы сделать что-то кому-то хорошо. Поверх всего этого возникают адаптеры к внешним системам. Это и шлюзы-репозитории к базам данных, и презентеры для работы с UI, и контроллеры для веба. Ну а сверху имеют место быть самые легко отшелушивающиеся оболочки: собственно базы данных, всякоразные UI, и другие прочие.
Чем ближе к ядру, тем более абстрактны понятия, тем менее изменчив код, тем больше мы думаем о том, для чего нужно это приложение, и что оно должно делать.
Чем более снаружи, тем больше специфичной конкретики, тем чаще все может меняться, тем больше мы думаем о том, как оно должно работать и взаимодействовать с внешним миром. Любой внешний кусочек, будь то база данных или UI, должно быть можно легко подменить.
Зачем всё это нужно, хорошо объяснил сам дядя Боб. Вся эта идея не зависит от используемых фреймворков, если всё сделать правильно, то можно будет безболезненно менять менее любимые фреймворки на более любимые по ходу дела. Как минимум, можно будет легко заменить UI: надо лишь поменять шаблоны или сделать совсем не веб UI, а, например, CLI. Легко должно быть поменять БД: лишь подменив маппер репозитория. Ну и, наконец, помним, что тесты — это тоже в некотором смысле интерфейс. Тесты — это внешняя система, которая тестирует вашу систему абсолютно на тех же правах, что и другие внешние системы. Тестируемость улучшается.
И самое главное правило: направление зависимостей. Внешние слои могут пользоваться всеми благами внутренних слоёв. А вот внутренние слои ни в коем случае не должны знать, во что их оборачивают или могут обернуть. Так как база данных у нас является внешним слоем, интерфейс репозитория должен определяться в слое предметной области. Именно она определяет что и когда должно сохраняться. А вот реализация репозитория — это и есть внешний заменяемый слой. Это классический пример инверсии зависимостей. Предметная область вынуждена вызывать слой данных, чтобы что-то сохранить. Но она не хочет зависеть от конкретной реализации репозитория. Вот и определяем интерфейс, а кто там его реализует — уже не наша проблема.
А что, если всё же вспомнить о микросервисах? А микросервисы — это луковица луковиц. Каждый микросервис — это маленькое (веб) приложение, которое должно быть красиво построено согласно Ясной Архитектуре. Но и сами микросервисы должны быть как-то организованы. И лучше бы по слоям. Есть микросервисы, которые нужны для реализации бизнес логики. А есть микросервисы, которые нужны для связи с внешним миром.
А что, если вспомнить о распределенных системах? Допустим, нам нужно отмасштабировать БД. Подменяем наш нижний слой: вместо одной БД запользуем некий кластер, в простейшем случае хотя бы с мастер-слейв репликацией. И немного подкрутим репозиторий, чтобы читал с реплик. Всё.
А теперь вспомним про highload. Воспользуемся универсальным способом решения проблем: введем еще один уровень абстракции. Наше веб приложение будет запущено на нескольких узлах, а сверху добавим еще один слой: лоадбалансинг. И пусть входящие запросы балансируются между инстансами нашего приложения. Еще один слой, и никто не уйдет обиженным.

Все красивые картинки поместил в презентацию я. Людоеда только не хватает.