О мониторинге
2015-02-08
Уговорили доложить о чем-нибудь девопсовом. Докладываю о мониторинге.

Под мониторингом в ИТ понимают несколько довольно разных вещей. В зависимости от того, что является целью и задачей мониторинга.
Во-первых, мы хотим мониторить метрики. Те самые цифры, которые показывают трафик на сетевых интерфейсах, загрузку ЦПУ в процентах или load average в попугаях.
Некоторые цифры сами по себе имеют смысл (загрузка ЦПУ). Для других интересно их изменение во времени (счетчики пакетов/байтов на сетевых интерфесах). Во втором случае нам нужна по сути производная (в математическом смысле) наблюдаемой величины.
Цифры эти мы собираем с завидной периодичностью. Раз в пять минут, раз в минуту, иногда даже хочется раз в секунду. А значит, метрики у нас образуют временные ряды, они же time series data. Если дать волю математикам, они могут сделать с временными рядами много интересного. Предсказать будущие значения, обнаружить аномальные отклонения, и прочее. Но простым бородатым сисадминам это обычно не интересно.
В старые времена было модно получать эти самые цифры через SNMP. Еще один протокол со словом "simple" в названии. Протокол, позволяющий управлять различными устройствами по сети, а также снимать показания всяких счетчиков, т.е. метрики. Любой приличный свич или роутер и в наши дни вполне себе умеет SNMP. SNMP — это не только сетевой протокол, но и обширные стандарты, описывающие параметры устройств, которыми можно управлять и которые можно считывать. Как общие параметры, например, всех свичей, так и специализированные параметры конкретного производителя или даже конкретного устройства.
Ну а сейчас модно использовать протокол, специфичный для наблюдаемой системы. Для БД, например, сбор метрик осуществляется какими-нибудь запросами к специальным таблицам или выполнением специальных команд через обычное клиентское подключение. А протокол передачи метрик определяется системой сбора метрик. Встречаются универсальные агенты, вроде Diamond, которые умеют собирать метрики кучей разных способов и отправлять их куче разных серверов мониторинга.
Метрики нужно не только собирать, но и хранить. Для этого часто используется принцип под названием RRD — Round Robin Database. А также конкретную реализацию этого принципа: RRDtool. Фокус номер один: нам нужны только свежие данные. Никому не интересны метрики пятигодичной давности. Поэтому, при вставке новых, мы просто выкидываем старые данные. Фокус номер два: нам не нужны детальные данные. Допустим, мы собираем метрики каждые пять минут. Такая детализация нам нужна только на пару дней. Для более старых данных нам достаточно, скажем, получасовой точности. Все равно в графиках за неделю пятиминутные отчеты не разглядишь. А для данных старше месяца возмем двухчасовую точность, спишем их в архив. Применив оба фокуса мы сможем отвести под хранения одной метрики в течение пяти лет буквально килобайты. Причем размер этот фиксирован и определяется на этапе создания RRD. Компактно и эффективно.
RRDtool используется под капотом кучи разных систем мониторинга: Cacti, Ganglia, Munin... тысячи их.
Некоторые обходятся и без RRDtool. Zabbix хранит метрики в реляционной БД. OpenTSDB — это вообще специальная база данных для хранения time series data, построенная поверх HBase, который построен поверх Hadoop, который... OpenTSDB никогда не удаляет и не «сворачивает» старые данные, совсем не RRD, все отчеты хранятся в том виде, как были сохранены. Graphitовый Whisper похож на RRD, но не RRDtool, по некоторым тонкостям использования он удобнее.
Собрать метрики мало. Их обычно еще визуализируют в красивые графики. RRDtool сам умеет генерировать готовые png файлы. OpenTSDB и Graphite тоже умеют, но как правило к ним есть еще разнообразные вебмордочки, чтобы удобно и красиво собрать разные графики на одном экране. Graphite тут немного уникален, потому что позволяет производить разнообразные математические операции над данными: находить производные, складывать, вычитать, умножать метрики, по-разному сводить несколько графиков на одной картинке.
Получается, что цепочка обработки метрик довольно длинна. Нужно собрать их на месте, передать по сети, сохранить в БД, преобразовать, нарисовать графики, показать графики пользователю. Инструментов на каждом этапе довольно много. Не все инструменты покрывают всю цепочку. Стандартов взаимодействия (ну, кроме, пожалуй, SNMP) шагов цепочки нет. Не все так радужно.
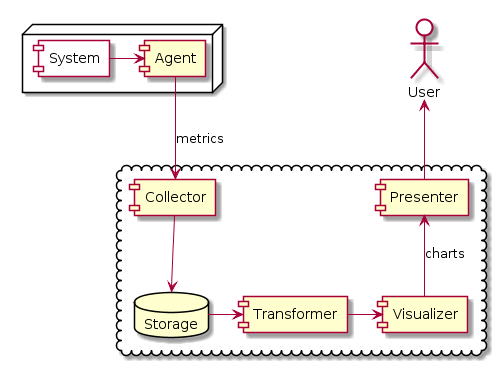
Во-вторых, кроме метрик мы хотим получать уведомления и алерты, когда на наших серверах, в нашем кластере или датацентре что-то пошло не так.
Базовым показателем здесь является факт сетевой доступности узла сети. Мы делаем ping: посылаем несколько ICMP Echo-Request и ждем ICMP Echo-Reply от узла. Если все пинги вернулись — все хорошо. Если часть пингов вернулось — все хорошо, хотя может быть и не так хорошо, как надо. Если ни один пинг не вернулся — все плохо. Если было хорошо, а стало плохо, надо послать СМС админу. Если было плохо, а стало хорошо, надо снова послать СМС админу. Так всякие Nagios и работают. Впрочем, Nagios умер и теперь надо использовать Icinga.
Наличие или отсутствие пинга, это вроде как и не метрика, тут нет числового значения. Или булева метрика, где есть два значения: пинг есть или пинга нет. Или метрика в процентах: количество вернувшихся ICMP Echo-Reply пакетов. Или метрика в миллисекундах: среднее время отклика, между посылкой Echo-Request и получением Echo-Reply. И то, и другое, и третье может представлять интерес, в зависимости от характера наблюдаемых явлений. Действие одно, а метрик несколько.
По-хорошему, мы должны делать какие-то проверочные действия над системой: посылать пинги, запрашивать статус БД и счетчики интерфейсов, — снимать множество метрик по каждому действию, сохранять их во временные ряды, анализировать ряды на предмет поиска аномалий и выхода значений за указанные пределы (было бы суперкруто, если эти пределы определялись автоматически), посылать уведомления, если имеются аномалии.
Т.е. вполне можно объединить сбор метрик, проверку работоспособности системы и отсылку уведомлений. Только почему-то почти никто так не делает. Nagios/Icinga пользуется своими средствами сбора показателей и проверки выхода значений за границы, и шлет уведомления, но не хранит сами значения и их историю. Graphite хранит метрики и историю, но не анализирует значения показателей. Zabbix, конечно, объединяет и то и другое, но он вещь в себе и не взаимодействует с другими системами.
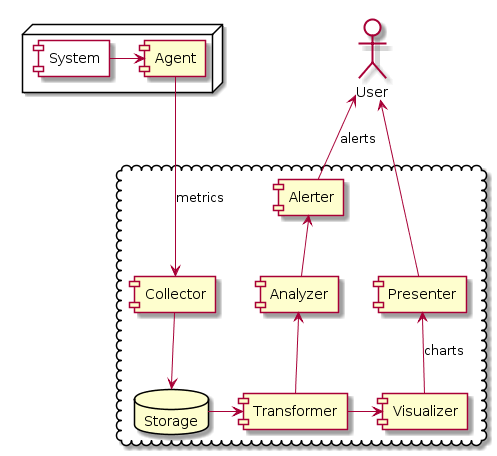
В-третьих, мы хотим видеть ексепшены и сведения о падении нашего приложения. Это те самые просьбы отослать крэшдампы и стектрейсы разработчику, которые вы видите в Windows, Ubuntu, Android и любой приличной системе, взаимодействующей с пользователем. Для мобильных приложений это особенно актуально, потому что аппаратных конфигураций тут просто чудовищное количество.
Ну а для своего серверного приложения можно поднять Sentry. Это не супергерой, а сервер для сбора данных об ексепшенах под свободной лицензией. В более сложных облачных случаях можно попробовать платный New Relic.
В-четвертых, мы хотим видеть не только ошибки приложения, но и статистику его использования. Нам нужно мониторить события. Для серверных приложений событием может быть запись в логе. Т.е. нам нужно мониторить логи. Для клиентских приложений событием может быть любое действие пользователя: нажатие на кнопку и т.п.
Тут мы переходим грань между чисто техническими нуждами мониторинга и рыночным анализом. Например, мы можем половине пользователей показать зеленую кнопку, а другой половине — красную кнопку. Затем, подсчитав количество нажатий на зеленую и на красную, мы можем определить какой цвет больше нравится нашей аудитории. Это называется A/B тестом.
Ну а из анализа логов запросов к веб серверу естественным образом вытекает статистика посещаемости веб страниц этого сервера. Что уже может быть интересно и сисадминам.
Сбором логов занимается, например, Logstash. Визуализацией — Kibana. Оба этих продукта имеют тесное отношение к Elasticsearch, потому что логи, это вам не просто числа.
Аналитикой занимаются, например, Google Analytics или Flurry Analytics. Первый больше заточен под веб, второй — под мобильные приложения. И то и другое — платные облачные продукты.
В случае мониторинга крэшей или событий нам приходится наблюдать систему изнутри. Нужны явные действия программиста, чтобы отправить стектрейс в Sentry, чтобы сделать запись в лог, чтобы нажатие на кнопку отразилось в Google Analytics. Либо же нам нужно вмешательство в выполняемый код, аналогичное отладке или профилировке, чтобы отследить ветки выполнения кода и найти проблемные места, это может New Relic.
Крэши и события — это не просто числовые метрики. С каждым событием связана целая кучка сопутствующих данных: цвет нажатой кнопки, User-Agent, куки, сам стектрейс... Конечно, количество событий в единицу времени вполне является метрикой, проблема в том, как их группировать. Допустим, событием является прохождение IP пакета через сетевой интерфейс. Мы можем сгруппировать по IP адресу отправителя или получателя, и получить метрики трафика пользователя или конкретного сайта. Или группировать по протоколу (TCP или UDP) и номеру порта, тогда получим трафик различный приложений, например, браузера. Получается, что из одного набора событий можно извлечь множество различных метрик в зависимости от интерпретации сопутствующих событию данных. Именно поэтому для анализа логов используется Elasticsearch — инструмент для полнотекстового поиска.
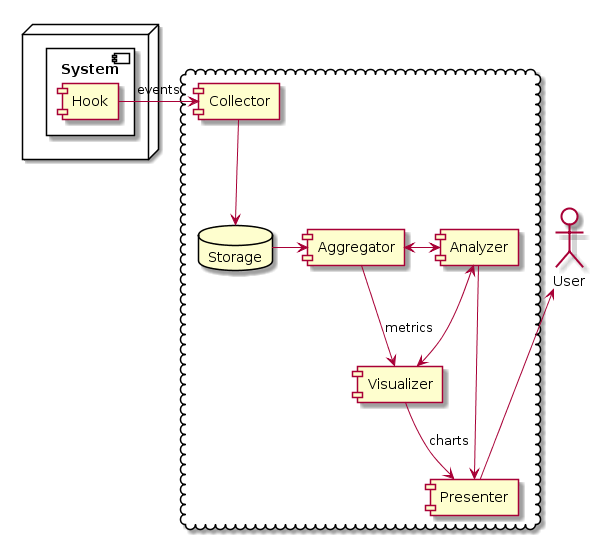
А универсальных инструментов для мониторинга метрик, анализа состояния системы и отсылки уведомления, сбора и анализа ошибок, логов и событий — нет. И, к сожалению, нет и приемлемого способа собрать это дело из существующих решений. Ибо нет стандартов по их взаимодействию. Есть, где развернуться девопсам/программистам.