О деплое MongoDB
2014-09-07
Ну давайте про Монгу. Хоть Монга и сверхпопулярна, и её используют даже там, где бы и не стоило, но мне часто задают вопрос: как правильно развернуть кластер на Монге. Вообще-то, чтобы правильно ответить на этот вопрос, достаточно дважды внимательно прочитать официальную документацию. Думаю, еще раз про это, и на русском, не помешает.
![]()
В отличие от более других NoSQL в Монге разделены репликация и шардинг. И replication factor определяется не настройками базы или коллекций, а самой конфигурацией кластера. И, соответственно, узлы в кластере играют определенную роль и не равнозначны. Видно, что так сложилось исторически. И жить от этого не легче.
Конечно, с Монгой можно работать и безо всех этих кластерных заморочек. Тупо запускаете mongod хоть на локалхосте и подключаетесь к нему из клиента. Но пойдем дальше.
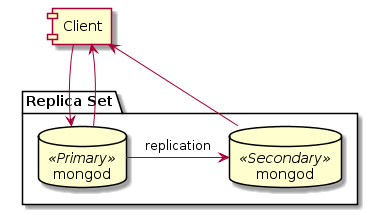
Репликация. Когда-то в Монге была мастер-слейв репликация. Но это было настолько давно, что уже не актуально. Теперешняя репликация базируется на понятии репликасета (Replica Set). Репликасет — это набор узлов (точнее процессов mongod), которые реплицируют данные друг на друга (т.е. содержат одинаковый набор данных). Один из этих узлов избирается Primary и все операции записи направляются на него. А он уже реплицирует эти операции (повтором операций из журнала) на другие Secondary узлы.
Если Primary становится недоступным (с точки зрения других узлов репликасета), то устраиваются выборы. И некий новый узел становится Primary. Чтобы избежать неоднозначностей, в выборах должно участвовать большинство (строго больше половины) известных узлов репликасета. А это значит, что узлов должно быть нечетное количество. Если же вам неохота хранить аж три копии данных, когда достаточно двух, можно добавить арбитра (Arbiter). Арбитр, это mongod, запущенный со специальным ключом. Он входит в репликасет, он, как и другие узлы, хранит у себя полную конфигурацию репликасета, он участвует в выборах, но он не хранит реальные данные репликасета и никогда не становится Primary. Такой вот грязный хак.
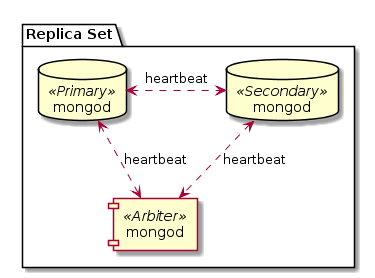
Так как арбитр по сути почти ничего не делает, его можно разместить где-нибудь рядом на одном узле с настоящими mongod, однако сильно не рекомендуется размещать его на одной машине с другим членом того же репликасета. Ибо так слегка нарушится концепция выборов.
Членам репликасета можно назначать приоритеты, чтобы при выборах Primary назначался более на эти узлы, чем на другие.
С точки зрения клиента подключение к репликасету несколько отличается от подключения к одиночному mongod. Нужно указывать имя репликасета и адрес одного из узлов. И клиент будет открывать подключения ко всем узлам репликасета (разве что кроме арбитров) и сам разбираться, кто там Primary, чтобы именно ему слать команды на запись.
При записи можно указать, какой степени надежности сохранения данных мы хотим достичь: просто послать команду и забыть, дождаться записи в журнал на Primary, дождаться записи данных на диск на Primary, дождаться репликации на один, два, большинство, конкретное число Secondary. Это называется Write Concern и похоже на соответствующие опции Кассандры. Помните, что ожидание репликации сильно задержит выполнение операции записи. Впрочем, ожидание сброса на диск тоже может быть долгим, ибо в Монге это делается по таймеру.
При чтении можно потребовать читать только с Primary, предпочтительно с Primary, только с Secondary, предпочтительно с Secondary или с ближайшего (с наименьшими сетевыми задержками) узла. Это называется Read Preference. Помните, что при чтении с Primary мы получаем строгую целостность, чтение сразу после записи прочтет измененные данные, ибо эти данные находятся на одной машине, а модификация их происходит через блокировку. А вот при чтении с Secondary будет достигнута только целостность в конечном счете (eventual consistency), когда-нибудь, после репликации, читаемые данные совпадут с записанными.
Репликасет предназначен для увеличения надежности хранения данных и обеспечения отказоустойчивости кластера. Можно также увеличить производительность кластера на чтение, если читать с Secondary, за счет eventual consistency. Если же нужно масштабировать производительность записи, а также хранить данных больше, чем уместится на одном узле, нужен шардинг (Sharding).
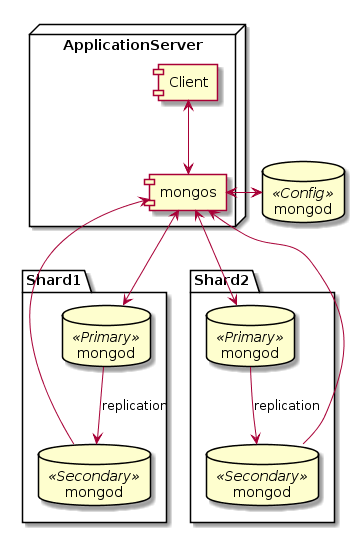
В Монге есть автоматический шардинг. Для этого нужно собрать кластер с соответствующей конфигурацией, включить шардинг для базы данных, указать ключ шардинга для коллекции. И Монга самостоятельно размажет ваши данные ровным слоем между шардами. Все множество значений ключей шардинга (или хэшей ключей) разбивается на диапазоны. Для каждого диапазона назначается шард, в котором данные из этого диапазона будут храниться. Например, от минус бесконечности до "N" — в шарде №1, от "N" до плюс бесконечности — в шарде №2.
Шардами в Монге могут быть либо отдельные инстансы mongod, либо репликасеты. Первый вариант рекомендуется только для разработки, ибо потеря любого узла приводит к потере части данных. А вот второй вариант — шарды из репликасетов — это и есть настоящий большой промышленный кластер Монги. Получается, что сначала происходит размазывание данных по шардам, а затем реплицирование между членами репликасета.
Иногда, когда данных не сильно много, но очень нужна хорошая производительность на запись, можно совместить на одном узле Primary и Secondary сервера разных шардов, чтобы и запись распределить между узлами, и несколько копий данных иметь. Например, так:
| Шард №1 | Шард №2 | Шард №3 | |
|---|---|---|---|
| Узел №1 | Primary | Arbiter | Secondary |
| Узел №2 | Secondary | Primary | Arbiter |
| Узел №3 | Arbiter | Secondary | Primary |
Впрочем, это не есть официально рекомендуемая конфигурация, так что решайте сами.
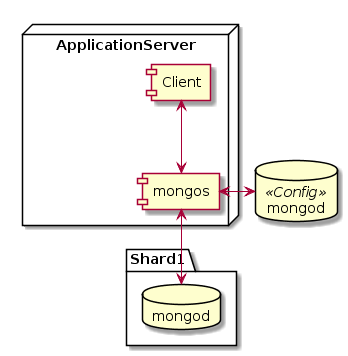
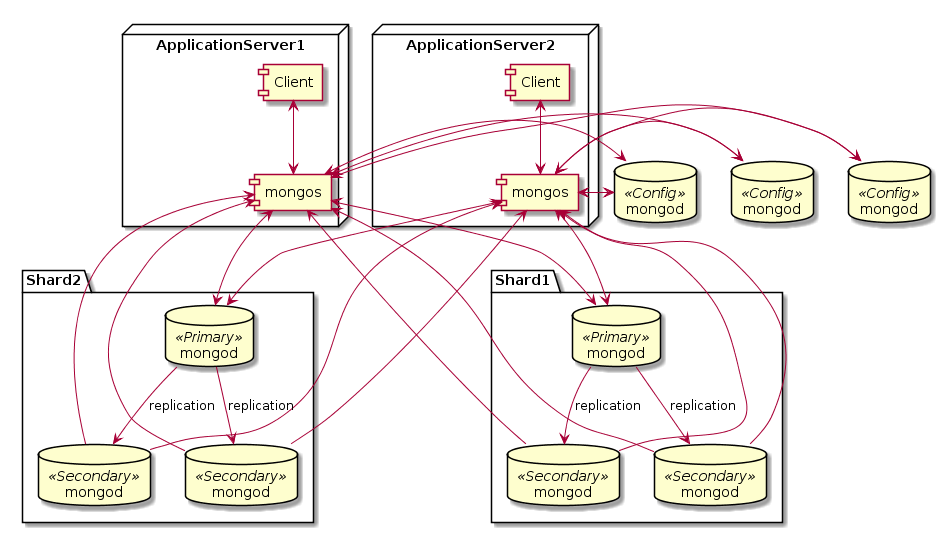
Кроме шардов из репликасетов, нужна еще пара компонент. Роутер запросов под названием mongos (Mongo Switch) — процесс, через который должны направлятся все запросы к шардированному кластеру. Именно он выясняет, на каком шарде находится (или должен находится) нужный документ, и перенаправляет туда запросы. Также он занимается миграцией и балансировкой шардов. Рекомендуется запускать mongos на каждом клиенте, т.е. на том узле, где у вас запущено приложение, использующее Монгу. Т.к. mongos ничего не хранит на диске и лишь немножко кушает память и ЦПУ, это вполне возможно. Для клиента подключение к mongos выглядит как подключение к одиночному mongod. Т.е. с точки зрения приложения, что есть шардинг, что его нет — почти одинаково.
Еще нужны конфиг сервера (Config Servers). Это обычные mongod, которые хранят метаданные о кластере. Это те самые диапазоны ключей шардинга, как они разбросаны по шардам. Объем метаданных — мизерный по сравнению с реальными данными. Запись в конфиг сервера происходит только при изменении конфигурации: добавлении или удалении новых шардов или перебалансировке кластера. В продукшене рекомендуется запускать три конфиг сервера для надежности (это не репликасет, это три отдельных сервера, синхронизацией между ними занимается mongos). Для карманного тестирования достаточно одного конфиг сервера.
Подытожим. Есть узлы с клиентским приложением. На этих же узлах должен быть запущен mongos. Клиент подключается к mongos на локалхосте. mongos подключается к шардам и конфиг серверам. Три конфиг сервера развернуты на трех разных узлах где-то в сторонке. Шарды представляют собой репликасеты. В каждом шарде/репликасете должно быть несколько узлов для хранения данных, в зависимости от того, сколько копий данных вы хотите хранить. Эти узлы сами выберут между собой, кто из них Primary. Общее число узлов в шарде/репликасете должно быть нечетным. Если у вас четный replication factor, нужно в каждый шард/репликасет добавить арбитра. Арбитров можно расположить где-нибудь сбоку или же раскидать по узлам с данными, важно только, чтобы он не находился на одном узле с другими серверами своего репликасета.
Ну и все это хозяйство вполне может быть размазано по разным датацентрам вокруг земного шарика. Впрочем, тогда вам может понадобиться тэгировать процессы mongod и данные, чтобы оптимизировать доступ.
Ну и помните, что для разработки достаточно одного единственного процесса mongod. Ну а если хотите потыкать шардинг, то его минимальная конфигурация включает в себя один mongos, один конфиг сервер, и один шард из единственного mongod.