О Redis
2021-12-26
Я уже писал о Redis. Тогда я рассказал, как использовать Redis как кэш из Spring. И немного о типах данных.

Но Redis — это несколько больше, чем просто кэш. Для просто кэша и memcached хватит. Кэш — это лишь две операции: записать значение и прочитать значение. А в Redis, даже на простейшем типе данных String, этих операций гораздо больше. И можно творить интересные вещи.
Кейс №1. У нас в системе есть какие-то рекламные кампании, и у них есть бюджет. Нужно сделать так, чтобы, расходуя этот бюджет, они из него не вышли. Сложность в том, что у нас распределённая система, и расход этого самого бюджета случается в разных сервисах.
Давайте использовать Redis
для контроля расхода бюджета.
При создании кампании будем записывать в Redis
вещественное число — доступный нам бюджет.
В качестве ключа будем использовать id кампании.
А там,
в тех разных сервисах, где этот бюджет расходуется,
будем выполнять команду INCRBYFLOAT
с отрицательным значением,
уменьшающим бюджет.
Ну и проверять результат операции,
что он всё ещё больше нуля.
Значит, деньги ещё есть.
Вся магия тут в том, что базовые операции в Redis — атомарны. И операции над одним ключом — строго сериализуемы. Поэтому, в рамках одного сервера Redis, можно инкрементировать значения одного и того же ключа из кучи разных потоков — наших с вами распределённых сервисов.
Конечно же,
использование float чисел
(точнее double precision в Redis) в данном случае допустимо
только если вас не очень волнует точное значение бюджета
после его расходования,
и не важно уйти точно в ноль,
а достаточно лишь иметь гарантированную отсечку на расходование денег.
Иначе вам нужно использовать целые числа,
считать копейки или доли копеек,
и использовать команду INCRBY
или DECRBY.
Любопытно, что в Redis эти целые (long) и вещественные (double precision) числа хранятся в виде действительно строки, дясятичной записи чисел. Несколько расточительно в плане расходуемой памяти и затрат CPU на преобразование форматов. Видимо, так было сделано в угоду универсальности, чтобы не вводить дополнительные типы данных. String, так String. И только операции инкремента вводят какие-то требования к тому, что в этих строках должно быть записано. Впрочем, о памяти вы задумаетесь только, если у вас будут миллиарды этих значений. А о производительности только, если у вас этих декрементов будут сотни тысяч в секунду.
Вы уже поняли, да? В memcached вы не сможете так просто инкрементировать значения. Вам понадобится ещё механизм блокировок, чтобы избежать гонок. А Redis сам сериализует атомарные операции над ключами. Впрочем, если мы начнём делать сам Redis распределённым, всё будет уже не так радужно. Но об этом попозже.
Кейс №2. Очень похож на предыдущий. Ограничение скорости. Количества запросов в секунду, например. Например, в обращении от множества распределённых клиентов к одному внешнему API, которое будет нас банить, если мы будем в него стучаться слишком часто. Или в обращении к нашей системе через кучи распределённых эндпоинтов, но мы хотим прирезать скорость каждому клиенту индивидуально.
Паттерн настолько распространённый,
что в документации к Redis он любезно расписан
прямо в описании команды INCR.
Rate limiter.
INCR — это как бы «базовая» команда для всех типов инкрементов.
Идея такая.
Мы заводим по ключу на каждого клиента или тип запроса,
которые нам нужно считать отдельно.
И тупо считаем,
то есть инкрементируем значение.
Когда счётчик превысит порог,
мы предпринимаем какие-то действия,
блокируем клиента, например.
А чтобы счётчик не рос вечно,
мы выставляем у записи TTL
командой EXPIRE.
Да, Redis умеет и такое,
автоматически удалять ключи
спустя указанное время.
Документация Redis предлагает два варианта реализации rate limiter. Оба рабочие, но имеют свои нюансы.
Вариант 1. В ключ, кроме идентификатора того, что нам нужно считать, мы добавляем ещё идентификатор текущего момента времени. Если нужно считать запросы в секунду, то округляя до секунды. Если нужно считать запросы в минуту, то округляя до минуты. И, каждый раз при обработке запроса, мы делаем две операции:
> INCR "${id}${truncated_now_time}"
> EXPIRE "${id}${truncated_now_time}" "${time_slot_duration * 2}"
Мы инкрементируем значение счётчика,
относящегося к текущему временному интервалу
(к текущей секунде или текущей минуте).
И выставляем TTL от длительности временного интервала
(секунда или минута),
просто, чтобы старые записи не накапливались в Redis.
Ну и проверяем результат INCR,
не превышает ли он порога.
Плюс этого варианта: мы используем только стандартные команды Redis, безо всяких продвинутых вещей. Существенный минус: момент, когда наш счётчик «сбрасывается», совпадает с началом секунды или минуты настоящего времени. Это порождает проблему тирании часов. В ИТ под этим подразумевают то, что слишком много событий запланировано и происходят не равномерно по времени, а привязано к началу минуты, часа, суток, недели, года...
Вариант 2.
Ключом является только идентификатор того,
что мы считаем.
А сбрасывается наш счётчик в момент исчерпания TTL.
Соответственно,
делать EXPIRE нужно не каждый раз,
а лишь сразу после сброса счётчика
(когда его инкрементированное значение будет равно единице).
Сделать INCR, проверить результат,
и, если результат единица, сделать EXPIRE
атомарно уже не получится.
Но тут нам поможет суперфича Redis — скрипты.
Для Redis можно писать скрипты на Lua.
Чудесно,
что любая последовательность команд в скрипте
будет выполняться атомарно.
Вот и надо засунуть INCR и EXPIRE в скрипт.
Вот такой:
local current
current = redis.call("incr", KEYS[1])
if current == 1 then
redis.call("expire", KEYS[1], ARGV[1])
end
Здесь KEYS — это массив ключей,
которыми оперирует скрипт.
В данном случае ключ один.
А ARGV — это массив аргументов скрипта.
Сюда мы передаём TTL для нашего вызова EXPIRE.
Напоминаю, в Lua индексы массивов начинаются с единицы.
Вызывается скрипт командой EVAL.
> eval "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2], ARGV[3]}" 2 key1 key2 first second third
1) "key1"
2) "key2"
3) "first"
4) "second"
5) "third"
Первым аргументов EVAL передаётся сам скрипт.
Как есть.
Как строка.
Вторым аргументом — количество ключей.
Потом идут сами ключи, согласно указанному количеству.
Потом собственно аргументы скрипта.
Скрипты в Redis компилируются и кэшируются.
То есть, повторные вызовы с тем же телом скрипта будут быстрее.
А, чтобы не передавать длинные скрипты при каждом вызове,
можно воспользоваться командами SCRIPT LOAD
и EVALSHA.
С ними вы загружаете скрипт лишь раз,
а при каждом вызове указываете SHA1 хэш от тела скрипта.
Хорошие клиенты Redis могут всю эту возню со скриптами красиво спрятать. Например, в ioredis (для JavaScript) можно определить свою команду в виде Lua скрипта и далее вызывать её точно так же, как и встроенные команды Redis.
Обратите внимание,
что ключи данных,
которыми оперирует скрипт,
передаются явно,
отдельно от остальных аргументов.
И они не должны быть захардкожены в теле скрипта.
Это нужно планировщику Redis.
Чтобы сериализовывать операции над ключами,
планировщику нужно знать эти ключи.
Поэтому же существуют команды EVAL_RO
и EVALSHA_RO,
чтобы дать знать Redis,
что эти скрипты не изменяют данные,
а значит, их можно лучше оптимизировать,
например, выполнить на репликах.
Со скриптами можно творить и более интересные вещи.
Кейс №3.
Те самые операции над бюджетами из первого кейса нужно дополнительно проверять.
У нас есть три момента,
когда может изменяться бюджет.
При торговле: bid.
При получении уведомлений о результатах торгов: notice.
По истечение таймаута на получение уведомления: timeout.
bid может случаться только один раз.
Если нам вдруг приходит повторный bid с тем же идентификатором,
он не должен менять бюджет.
notice может случаться только после bid.
notice без предшествующего bid не должен менять бюджет.
Повторный notice с тем же идентификатором тоже не должен менять бюджет.
timeout может случаться только после bid,
но не после notice.
Если мы уже видели bid и notice, timeout не должен менять бюджет.
Повторный timeout тоже не должен менять бюджет.
У bid, у notice и у timeout есть уникальный идентификатор операции.
Его мы будем использовать в качестве ключа.
А в качестве типа данных будем использовать Set, множество.
Просто множество уникальных значений.
А для атомарной проверки и модификации этого множества
нам понадобится скрипт.
После тщательной отладки и кучи тестов
скрипт получился такой:
local result = {} -- ожидаемый результат, итоговое состояние множества
-- разбор первой группы аргументов: элементы множества, которые нужно проверить
local numChecks = tonumber(ARGV[1]) -- количество аргументов в первой группе
local checks = {} -- элементы множества, которые нужно проверить
for i = 2, 2 + numChecks - 1 do -- перебор аргументов указанного количества
table.insert(checks, ARGV[i]) -- добавление в элементы, которые нужно проверить
table.insert(result, ARGV[i]) -- добавление в ожидаемый результат
end
table.sort(checks) -- сортировка массива элементов, которые нужно проверить
-- redis.log(redis.LOG_NOTICE, cjson.encode(checks))
-- разбор второй группы аргументов: элементы множества, которые нужно добавить
local numAdds = tonumber(ARGV[2 + numChecks]) -- количество аргументов во второй группе
local adds = {} -- элементы множества, которые нужно добавить
for i = 3 + numChecks, 3 + numChecks + numAdds - 1 do -- перебор аргументов
table.insert(adds, ARGV[i]) -- добавление в элементы, которые нужно добавить
table.insert(result, ARGV[i]) -- добавление в ожидаемый результат
end
-- redis.log(redis.LOG_NOTICE, cjson.encode(adds))
table.sort(result) -- сортировка массива ожидаемых элементов множества
-- получение текущего сохранённого множества
local stored = redis.call('smembers', KEYS[1])
table.sort(stored) -- сортировка массива сохранённых элементов
-- redis.log(redis.LOG_NOTICE, cjson.encode(stored))
-- сравнение ожидаемого результата с текущим сохранённым множеством
if #stored == #result then -- если длины массивов совпадают
local eq = true -- флаг равенства
for i = 1, #stored do -- перебираем элементы текущего сохранённого множества
if stored[i] ~= result[i] then -- если элементы не равны
eq = false -- флаг равенства = не равны
break
end
end
if eq then -- если ожидаемый результат уже равен тому, что хранится
return redis.error_reply('repeat equal') -- ошибка: повтор операции
end
end
-- сравнение текущего сохранённого множества с теми элементами, которые нужно проверить
if #stored ~= #checks then -- если длины массивов не совпадают
return redis.error_reply('misorder count') -- ошибка: неправильный порядок операций
end
for i = 1, #stored do -- перебираем сохранённые элементы
if stored[i] ~= checks[i] then -- если элементы не равны
return redis.error_reply('misorder content') -- ошибка: неправильный порядок операций
end
end
-- добавление элементов во множество
local added = redis.call('sadd', KEYS[1], unpack(adds)) -- unpack разворачивает массив в varargs
-- проверка количества новых элементов множества (результат sadd)
if added > #adds then -- если добавилось больше, чем ожидалось
return redis.error_reply('misorder sadd') -- ошибка: неправильный порядок операций
end
if added == 0 then -- если добавилось ноль новых элементов
return redis.error_reply('repeat sadd') -- ошибка: повтор операции
end
-- успешное завершение проверок
return redis.status_reply('ok') -- ответ: ok
Возможно,
в вашем случае можно будет выкинуть половину проверок.
Как минимум, проверку результата выполнения SADD.
Но я оставил.
Для надёжности.
В Lua, к сожалению, нет встроенного типа для множеств. Тут есть только table. Ассоциативные массивы. Которые работают как обычные массивы (с индексацией от единицы, как правило), если ключом является целое число. Ну как в PHP. И в Lua нет встроенных функций сравнения таблиц (и массивов). Поэтому получилось так длинно. Для сравнения понадобилась и сортировка массивов, и сравнение длин, и последующий перебор и поэлементное сравнение. Дважды :)
Как видите,
дебажить пришлось через redis.log().
Как видно из названия,
оно пишет в лог Redis.
Есть и более продвинутые методы.
Но обошлось без них.
Вызывается этот скрипт так:
> EVALSHA ${sha1} 1 ${op_id} 0 1 bid
> EVALSHA ${sha1} 1 ${op_id} 1 bid 1 notice
> EVALSHA ${sha1} 1 ${op_id} 2 bid timeout 1 notice
> EVALSHA ${sha1} 1 ${op_id} 1 bid 1 timeout
Я воспользовался тем же синтаксисом с указанием количества аргументов, чтобы отделить элементы множества, которые должны быть записаны в момент проверки, от новых элементов, которые нужно добавить в множество.
В качестве ключа для хранения множества мы используем ID операции. Этому ключу потом выставляется TTL порядка двух суток, чтобы записи уничтожались после того, как все уведомления гарантированно были получены или сработали все разумные таймауты.
На bid мы ожидаем,
что множество операций было пустое.
Иначе ошибка.
На notice мы ожидаем,
что предыдущей операцией был один лишь bid.
Если там уже случился timeout, будет ошибка.
Хотя мы можем проверить и notice после bid и timeout,
и произвести какие-то другие операции с бюджетом в этом случае.
На timeout мы ожидаем,
что предыдущей операцией был лишь bid.
Типы данных в Redis — мощная штука. Различные атомарные команды над ними — тоже мощная штука. А Lua скрипты, которые позволяют создавать свои собственные атомарные команды — ещё более мощная штука. Ух.
Но хватит про команды. Теперь немного про масштабирование.
Redis прекрасно работает даже когда это один сервер. И производительности даже одного сервера вам хватит надолго. Хоть это и in-memory БД, не бойтесь, вы не потеряете данные. Redis делает регулярные снапшоты данных на диск, а при старте считывает снапшот с диска. Так что, при graceful shutdown, вы ничего не потеряете.
Но это не отменяет того, что вы можете потерять сам сервер. Чтобы такого не случилось, вы можете поднять реплики. А чтобы новый мастер автоматически выбирался бы при падении старого, и ваши клиенты автоматически переподключались бы на нового мастера, вам нужен будет Sentinel. Это такой отдельный специальный распределённый сервис, который следит за здоровьем Redis. И клиентам нужно подключаться к нему.
Репликация в Redis — асинхронная. И только асинхронная. И мультимастера нет. Отсюда два вывода. Репликация не масштабирует ваш Redis на запись. Вся запись идёт через единственного мастера. И, если вы читаете из реплик, вы можете прочитать устаревшие данные. Ну и при внезапном падении мастера вы можете потерять последние записи.
Если вы хотите добавить не только отказоустойчивости, но и производительности, вам понадобится Redis Cluster. Это уже, как это принято у нас в NoSQL, шарды. А каждый шард уже может быть набором реплик. Шарды из реплик. Знакомо.
Шардинг в Redis, очевидно, распределяет ключи между шардами. Отсюда возникает ограничение: если команда оперирует несколькими ключами (встроенных таких единицы, но Lua скрипт запросто может быть таким), все ключи должны находиться на одном шарде. Иногда такое ограничение может быть неприятным.
А нам понадобилось нечто другое. Географически распределённый мультимастер.
Redis очень хорош и быстр, если он живёт в той же локальной сети (VPC), что и ваши сервисы. Если за Redis нужно ходить через океан, он, очевидно, начинает работать не быстрее обычной СУБД. Против физики и скорости света не попрёшь.
А те же бюджеты или количество запросов нужно считать в разных географических локациях. В идеале нужно иметь в каждом датацентре свой локальный Redis. Вот только эти Редисы должны содержать одинаковые данные и как-то синхронизироваться друг с другом. Просто потому что рекламные кампании никак не ограничены географически, так же как и источники запросов.
Можно, чтобы сервисы в каждой географической локации общались только со своим локальным Redis. И как-то нагородить систему синхронизации между Редисами.
В простейшем случае эта система «синхронизации» может быть такой. Пусть сервисы в каждой географической локации пишут и читают (или дожидаются результатов записи) только в свой локальный Redis. Но так же пусть они поддерживают подключение ко всем другим Редисам в других географических локациях. И пусть они транслируют все операции записи на удалённые Редисы. Причём асинхронно, не дожидаясь результатов, это не должно замедлять их собственную работу.
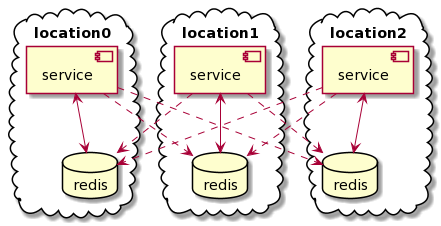
Получается почти честный мультимастер. Мы будем иметь идентичные копии данных в каждой локации. За вычетом погрешностей из-за задержки операций. И из-за изменения порядка самих операций, слава богу, инкременты можно применять в любом порядке.
Да, при разрыве связи между локациями данные могут разойтись. И ваши Redis клиенты, кстати, должны уметь автоматически переподключаться. Но, если вам не нужны точные значения, а лишь срабатывание при достижении порога счётчиков, это сгодится.
У нас работает :)