Об SSD
2019-05-19
В моём ноутбуке два SSD. Один, родной, подключен через M.2. Второй я воткнул через SATA, был в ноуте пустующий двухсполовинойдюймовый отсек.
Я думал, что современный Linux (в моём случае KDE neon) умеет самостоятельно определять и настраивать SSD. Оказалось, что нет.
Определять-то он умеет.
$ cat /sys/block/sd[a,b]/queue/rotational
0
0
А вот правильно настраивать, похоже, что нет. Может, оно и настраивается при установке, если не разбивать диски вручную, как это сделал я.
Проблему я обнаружил, когда расчехлил Android Emulator, которым несколько месяцев не пользовался. И этот Android Emulator что-то подозрительно страшно стал тормозить, независимо от образов и уровня аппаратного ускорения.
Оказалось, что 100% CPU тратится на iowait. Просто этот QEMU эмулятор постоянно пишет в файлы дисковых образов. Не то, чтобы сильно много, iotop показывал два мегабайта в секунду. Но постоянно.
Потом я заметил,
что iowait зашкаливает
и при обновлении этих самых образов этого самого эмулятора из IDEA.
И при apt upgrade тоже.
При любой интенсивной записи на этот диск,
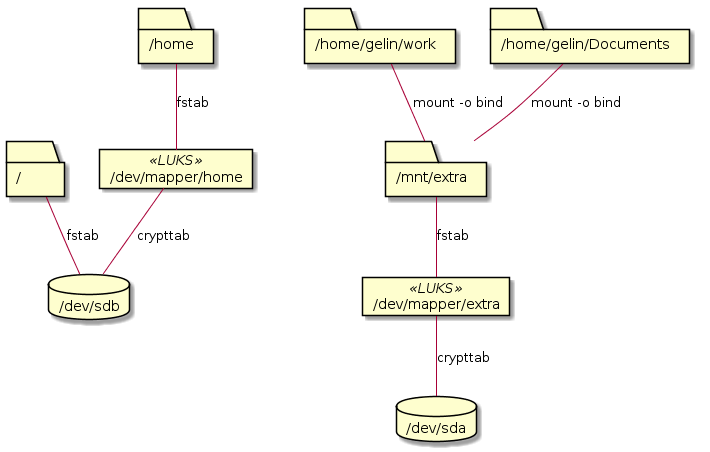
на котором у меня / и /home.
А 100% CPU на iowait — жутко неприятная штука. Даже мышка тормозит. Жить с запущенным эмулятором стало невозможно.
Пошёл смотреть, что пишут знающие люди. Эмулятор вроде тормозит в основном из-за отсутствия аппаратного ускорения. А последние эти эмуляторы вообще не хотят работать без ускорения. Так что проблема не в этом.
Проблема в диске, раз iowait. Потестировал.
$ sudo dd if=/dev/zero of=/test.out bs=8k count=10k conv=fdatasync; sudo rm -f /test.out
83886080 bytes (84 MB, 80 MiB) copied, 0.388245 s, 216 MB/s
$ sudo dd if=/dev/zero of=/test.out bs=8k count=10k conv=fdatasync; sudo rm -f /test.out
83886080 bytes (84 MB, 80 MiB) copied, 0.6167 s, 136 MB/s
$ sudo dd if=/dev/zero of=/test.out bs=8k count=10k conv=fdatasync; sudo rm -f /test.out
83886080 bytes (84 MB, 80 MiB) copied, 4.25416 s, 19.7 MB/s
$ sudo dd if=/dev/zero of=/test.out bs=8k count=10k conv=fdatasync; sudo rm -f /test.out
83886080 bytes (84 MB, 80 MiB) copied, 4.5336 s, 18.5 MB/s
$ sudo dd if=/dev/zero of=/test.out bs=8k count=10k conv=fdatasync; sudo rm -f /test.out
83886080 bytes (84 MB, 80 MiB) copied, 0.347519 s, 241 MB/s
Видно, что при интенсивной записи скорость записи может драматически упасть на порядок, и восстановиться только спустя какое-то время. И это повторяется только на M.2 диске, на всех его разделах, независимо от того, зашифрован раздел или нет. На втором диске (большего объёма), проблема не наблюдается.
Пошёл смотреть, как правильно настраивать SSD. Вспомнил, как мы тестировали NoSQL БД Aerospike.
Во-первых, у SSD стоял неправильный IO scheduler.
$ cat /sys/block/sd[a,b]/queue/scheduler
noop deadline [cfq]
noop deadline [cfq]
Это планировщик ввода-вывода. CFQ — это Completely Fair Queuing. Этот планировщик буферизирует и переупорядочивает операции записи, чтобы писать подряд в соседние блоки. Это очень хорошо для вращающихся дисков, но лишь вносит лишние задержки для твёрдотельных дисков.
Для SSD положено использовать планировщики Deadline или Noop. Они не переупорядочивают операции записи. Deadline заточен обеспечивать максимальную отзывчивость. Noop просто самый простой планировщик.
Можно просто записать нужное значение в /sys/block/sd[a,b]/queue/scheduler.
Это сразу поменяет планировщик,
но изменение не сохранится после ребута.
Чтобы правильный планировщик установился после ребута,
если у вас udev,
можно прописать соответствующие правила
куда-нибудь в /etc/udev/rules.d/80-schedulers.rules.
$ cat /etc/udev/rules.d/80-schedulers.rules
ACTION=="add|change", KERNEL=="sda", ATTR{queue/scheduler}="deadline"
ACTION=="add|change", KERNEL=="sdb", ATTR{queue/scheduler}="deadline"
У меня заработало.
Во-вторых, у меня совершенно не выполнялся TRIM.
У SSD довольно неоптимально производится запись. Нельзя просто так взять и записать блок данных. Сначала нужно стереть целую страницу (допустим, размером в 64 блока), а лишь потом записать блок. Хорошо, если страница не использовалась, тогда достаточно записать один новый блок. Плохо, если страница уже содержала важные данные, тогда нужно заново переписать все 64 блока, хотя менялся только один.
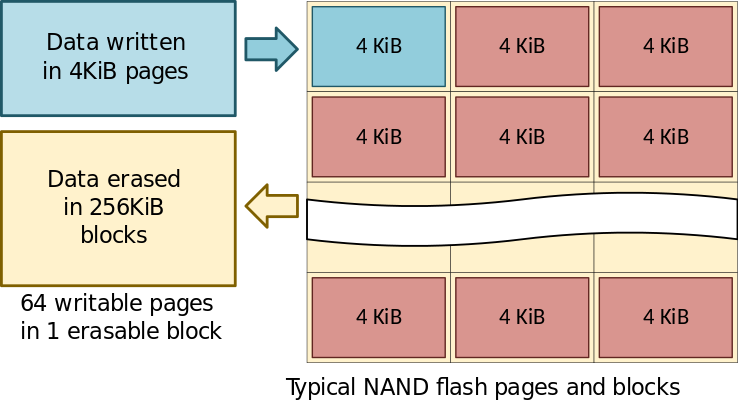
Поэтому контроллер SSD старается иметь в запасе уже заранее подготовленные к записи чистые неиспользуемые страницы. Тогда можно писать новые блоки прям сразу, без предварительного стирания и перезаписывания целой страницы.
Но где взяться пустому месту на диске, которое можно выдать контроллеру для подготовки чистых страниц? На самом деле, на уровне ОС вопрос даже сводится к тому, как сказать контроллеру, что это место пустое?
Самый оптимальный по быстродействию способ — не занимать весь SSD разделами и файловыми системами. Оставить 25-30% объема под полный контроль контроллера. Это называется overprovisioning и является обязательным для быстрой работы той же Aerospike, которая работает с SSD напрямую как с блочным устройством.
Но жалко делать overprovisioning на ноутбуке, где и так диски всегда меньше по объему, чем хочется.
Поэтому нам нужен TRIM.
TRIM — это такая команда ATA интерфейса, которой операционная система сообщает контроллеру диска, что данные блоки не используются. Контроллер SSD использует эту информацию для формирования и затирания страниц, что очень существенно ускоряет запись.
TRIM команды должна посылать ОС. Как она это делает?
Для начала,
есть замечательная стандартная утилитка
fstrim.
$ sudo fstrim /
Она просто тримит неиспользуемые блоки на (почти) любой живой файловой системе.
В моём случае запуск fstrim на проблемном диске выполнялся пару минут.
И помогло.
Но fstrim нужно выполнять регулярно.
Поэтому в Ubuntu уже завезли соответствующий systemd юнит.
$ systemctl status fstrim.timer
● fstrim.timer - Discard unused blocks once a week
Loaded: loaded (/lib/systemd/system/fstrim.timer; enabled; vendor preset: enabled)
Active: active (waiting) since Fri 2019-05-10 16:31:54 +06; 1 weeks 2 days ago
Trigger: Mon 2019-05-20 00:00:00 +06; 7h left
Docs: man:fstrim
Но это же ноутбук. Тут же недельные задания крона почти никогда не выполняются, потому что он вовсе не всегда включен. Поэтому пойдём другим путём.
Многие файловые системы сами умеют делать TRIM,
когда удаляются файлы.
Просто из нужно смонтировать с опцией discard.
cat /etc/fstab | grep discard
UUID=a13bef7f-9778-407a-bb1e-234bbbb7d3e9 / ext4 defaults,noatime,discard,errors=remount-ro 0 1
UUID=7d143722-402a-4007-bbc5-e7e9962d7b8f /boot ext4 defaults,noatime,discard 0 2
/dev/mapper/home /home ext4 defaults,noatime,discard 0 2
/dev/mapper/extra /mnt/extra ext4 defaults,noatime,discard 0 2
Обратите внимание на опцию noatime.
Она отключает запись в ФС времени последнего доступа (access time) к файлу.
Прикиньте, да,
Linux изменяет метаданные файла,
даже если файл просто читается.
Впрочем,
вроде в последних ядрах по умолчанию задействовано relatime,
похожая оптимизация,
но не ломающая работу программ,
которые полагаются на правильные значения access time
(все мануалы вспоминают только mutt).
Пусть будет отключено.
Однако,
discard на уровне файловой системы
по умолчанию не работает для блочных устройств dm-crypt.
Потому что в этом есть небольшое снижение секурности.
А у меня как раз есть LUKS разделы.
Нужно добавить discard и в crypttab.
$ cat /etc/crypttab | grep discard
home UUID=8d35339f-470c-4875-92c5-887221e690e6 none luks,checkargs=ext4,discard
extra UUID=6bd53923-f9fa-4318-b50d-7d976f8ae791 none luks,checkargs=ext4,discard
fstrim/discard, правильный (не CFQ) IO scheduler, noatime,
и будет вам счастье.