О DynamoDB
2018-05-20
А продолжим о DynamoDB.
Краткое содержание предыдущей серии. DynamoDB — одна из старейших облачных NoSQL БД. Живёт в облаке Амазона (aka AWS).
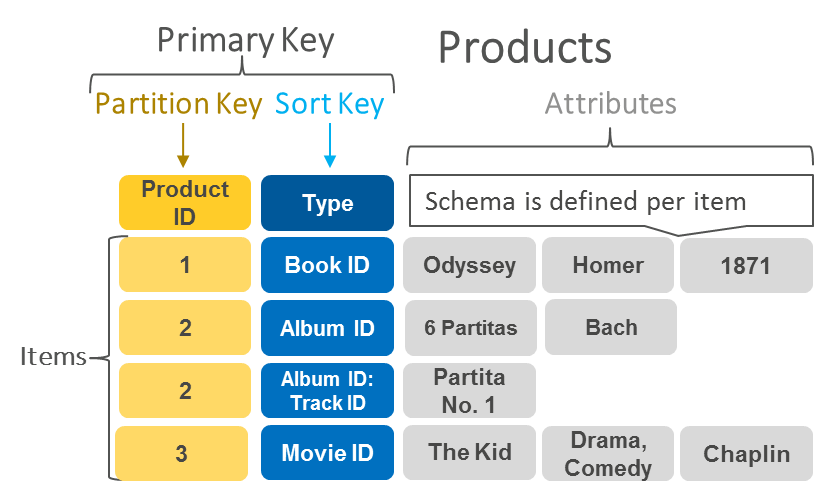
Модель данных у DynamoDB очень напоминает таковую у кассандрового CQL. Есть таблицы. В таблицах хранятся itemы. В таблице определён первичный ключ, по которому ищутся itemы. Первичный ключ состоит из обязательного partition key (он же hash key) и необязательного sort key (он же range key).
Partition key определяет партицию, куда будут помещены данные. Поиск возможен только по полному совпадению значения этого ключа. Получается, что любая операция в БД работает только с единственной партицией.
Sort key отсортирован. Возможен поиск по диапазону значений этого ключа.
Кроме ключей в itemах можно хранить атрибуты. Каждый атрибут имеет имя и значение. Значения бывают разных типов: строки, числа, множества (set), списки (list) и карты (map). Элементами множеств, списков и карт могут быть другие типы. Таким образом можно хранить любые структурированные данные, а ля JSON.
Посмотрим подробнее,
как можно строить запросы.
В Spring, как всегда,
есть свои обёртки над всякоразными API разных БД.
А в стандартном амазоновом SDK
вся пляска идёт вокруг объекта
Table
(если мы не используем мапинг в Java объекты).
Для запросов этот объект реализует
интерфейс QueryApi.
Самый мощный его метод выглядит так:
ItemCollection<QueryOutcome> query(QuerySpec spec)
Соответственно,
всё, что может QuerySpec,
может и DynamoDB.
А ItemCollection результата можно просто
засунуть в for-each цикл
и вытащить все itemы.
В каждом запросе должны или могут присутствовать:
- Точное значение partition key.
- Условие выборки по sort key. Больше, меньше, между, начинается с подстроки.
- Направление сортировки по sort key. Можно в обе стороны.
- Список атрибутов, которые нужно извлечь. Проекция.
- Фильтры для дальнейшего уточнения выборки. По любым атрибутам можно проверить кучу условий. Больше, меньше, между, существует ли, содержит ли подстроку. Важно, что лишь первичный ключ ограничивает набор просматриваемых itemов в хранилище. Фильтры лишь отсеивают itemы, которые нужно вернуть. Поэтому нужно хорошо думать о первичных ключах, чтобы они ограничивали выборку, а фильтры использовать лишь как вспомогательный инструмент.
- Условие объединения фильтров, если их больше одного. «И» или «ИЛИ».
- Флаг строгой целостности. Да, DynamoDB пытается предоставить какие-то гарантии, чтобы чтение после записи могло прочитать только что записанные данные.
- Ограничения на количество просматриваемых записей, размер и количество страниц. Под капотом DynamoDB работает через HTTP, и размер страницы ограничивает размер одного HTTP ответа. Каждая страница возвращается отдельным HTTP ответом. Все эти тонкости хорошо запрятаны в SDK и на уровне итерации по результатам запроса почти незаметны.
У нас есть два взаимно исключающих способа работы с DynamoDB. Это касается условия выборки по ключу, проекций и фильтров.
Первый способ — более старый. Раньше появился в API. Здесь вы указываете точные значения ключей, имена атрибутов, конкретные операции и значения для сравнения.
Такой запрос на Kotlin выглядит примерно так:
val filters = sensors.map { QueryFilter(it).exists() }
val querySpec = QuerySpec()
.withHashKey("u", location)
.withRangeKeyCondition(RangeKeyCondition("t").between(
Instant.parse("2018-04-20T00:00:00Z").epochSecond,
Instant.parse("2018-04-21T00:00:00Z").epochSecond))
.withScanIndexForward(false)
.withAttributesToGet(*sensors.toTypedArray())
.withConditionalOperator(ConditionalOperator.OR)
.withQueryFilters(*filters.toTypedArray())
.withMaxResultSize(1000)
val items = table.query(querySpec)
for (item in items) {
// ...
}
Второй способ — более новый.
Здесь появляется понятие выражений,
expressions.
Для ключей, проекций и фильтров.
Текстовые читабельные выражения.
Примерно такие же,
что стоят после WHERE в SQL.
И в эти выражения можно подставлять параметры.
Почему-то выделяют два вида параметров. Параметры для имён используются для подстановки имён атрибутов, и выглядят они в выражениях как «#name». Параметры для значений используются для подстановки значений, с которыми будут сравниваться ключи или атрибуты, и выглядят они как «:value». Задаются имена и значения обычными мапами.
Запрос с выражениями на Kotlin выглядит примерно так:
val querySpec = QuerySpec()
.withKeyConditionExpression(
"u = :location AND t BETWEEN :start AND :end")
.withScanIndexForward(false)
.withProjectionExpression(sensors.mapIndexed { index, _ -> "#attr$index" }
.joinToString(", "))
.withFilterExpression(sensors.mapIndexed { index, _ -> "attribute_exists(#attr$index)" }
.joinToString(" OR "))
.withMaxResultSize(1000)
.withNameMap(sensors.mapIndexed { index, name -> "#attr$index" to name }.toMap())
.withValueMap(mapOf(
":location" to location,
":start" to Instant.parse("2018-04-20T00:00:00Z").epochSecond,
":end" to Instant.parse("2018-04-21T00:00:00Z").epochSecond
))
val items = table.query(querySpec)
for (item in items) {
// ...
}
Я тут замутил, запрашиваю произвольный набор атрибутов и выискиваю itemы, где эти атрибуты присутствуют.
Казалось бы, зачем эта морока с составлением строковых выражений (где ещё и некоторые слова зарезервированы). Объектами ведь проще. Для запросов оно, наверное, и так. Но для апдейтов выражения дают некоторые уникальные возможности.

Апдейты делаются через
интерфейс UpdateItemApi,
который,
конечно же,
реализуется нашим Table.
Дело в том, что я считаю метрики. И интенсивно использую возможность атомарного инкремента числовых значений. Ну и атомарного добавления элементов во множества тоже.
Оно работает так. Я говорю, что хочу добавить в item с данным первичным ключом, к атрибуту с конкретным именем, такое-то число. Если атрибута или даже всего itemа не существует, он создаётся автоматически. Начальным значением считается нуль, и он атомарно инкрементируется на указанное число. Если атрибут уже существует (и содержит число), его значение просто инкрементируется. Можно даже одним запросом обновить так несколько атрибутов одного itemа. Очень удобно.
Выглядит это примерно так:
val key = PrimaryKey("u_period", hashKey, "t", rangeKey)
val updateOps = listOf(
AttributeUpdate("${sensor}_count").addNumeric(aggregate.count),
AttributeUpdate("${sensor}_sum").addNumeric(aggregate.sum)
)
table.updateItem(key, *updateOps.toTypedArray())
AttributeUpdate задаёт операции над конкретным атрибутом.
А затем список операций выполняется над конкретным itemом.
И теперь добавляем две магии. Их присутствие сильно подняло крутизну DynamoDB в моих глазах.
Магия первая.
Перед апдейтом можно проверить
выполнение некоторого условия на любых атрибутах itemа.
Если условие выполняется,
апдейт происходит.
Если условие не выполняется,
но наш код получит ConditionalCheckFailedException
и может что-то с этим сделать.
Условие можно добавить,
передав в updateItem помимо AttributeUpdate
ещё и коллекцию объектов Expected.
Магия вторая. Оказывается, выражения позволяют обращаться к вложенным атрибутам с указанием пути (path). Если у вас есть атрибут с именем «map», содержащий мапу, а в этой мапе есть поле с именем «field», то можно использовать путь «map.field», чтобы обратиться с значению в мапе. Если где-то там есть список, то можно использовать числовой индекс элемента в списке в квадратных скобках: «list[0]». Как в JSONPath. Появление специальных символов типа точки вносит некоторую неоднозначность, поэтому настоятельно рекомендуется такие символы не использовать в именах атрибутов. Эти вложенные пути работают только в выражениях, и это хороший повод перейти на выражения.
На самом деле, любой апдейт должен или может содержать:
- Точное значение partition key.
- Точное значение sort key, если он есть. Как видите, нельзя проапдейтить несколько itemов одной операцией.
- Набор операций обновления данного itemа или update expression.
- Набор условий для проверки возможности обновления данного itemа или condition expression.
Итак. А что, если у нас много счётчиков. И они образуют развесистую иерархию. Например, мы хотим подсчитать, сколько раз какой-то сенсор принимал определённые значения. При этом мы знаем название сенсора, и это может быть именем атрибута. Но мы не хотим вдаваться в детали, какие именно значения принимал каждый сенсор. Мы просто засовываем в атрибут мапу, где имена полей будут значениями, а хранить мы будем счётчики, сколько раз это значение встречалось.
И теперь мы хотим атомарно инкрементировать числа, вложенные в мапы. Как мы делали это с числами, которые непосредственно хранились в атрибутах. С вложенными путями в выражениях это возможно. Нужно задать update expression вида «SET map.nested = map.nested + 1». Это будет работать.
Но беда в другом. Сама мапа, если её не существует, нет такого атрибута, не будет создана автоматически. И то же касается всех вложенных полей мапы. Нельзя прибавить число к тому, чего нет.
Проблему можно решить таким алгоритмом. Добавляем condition expression, который проверяет наличие вложенного поля для инкремента. Если условие не срабатывает, ловим исключение и делаем уже другой апдейт: создаём нужное поле мапы, сразу с начальным значением. И ставим здесь другое условие: на существование самой мапы. Если условие не срабатывает, ловим исключение и уже создаём мапу.
Как-то так:
try {
table.updateItem(key,
"SET #sensor.#state.#name = #sensor.#state.#name + :inc",
"attribute_exists(#sensor.#state.#name)",
mapOf("#sensor" to sensor, "#state" to state, "#name" to name),
mapOf(":inc" to 1))
} catch (e: ConditionalCheckFailedException) {
try {
table.updateItem(key,
"SET #sensor.#state.#name = :newName",
"attribute_exists(#sensor.#state)",
mapOf("#sensor" to sensor, "#state" to state, "#name" to name),
mapOf(":newName" to 1))
} catch (e: ConditionalCheckFailedException) {
// ...
}
}
Тут получается рекурсивный отлов исключений, в зависимости от глубины вложенности нашей мапы. В худшем случае, когда это совершенно свежий item, придётся сделать соответствующее число неудачных попыток, прежде чем создать сразу вложенную мапу нужной глубины. Зато последующий инкремент того же поля сразу сделает нужный атомарный апдейт.
Не вполне ясно, как тут будет с гонками, сериализуются ли апдейты в одной партиции. Пока вроде работает, но одиночные ошибки, когда разные клиенты будут одновременно пытаться создать мапу, поди ещё отлови.
Обратите внимание, что вложенные пути, которые с точками, должны присутствовать именно в выражении. Если передать строку с точками в качестве параметра, это не будет работать как вложенный путь.
Красивый рекурсивный функциональный вариант выглядит так:
fun UpdateItemApi.tryToIncrement(key: PrimaryKey, path: List<String>, increment: Int) {
val pathExpression = path.toPathExpression()
val attributesMap = path.toNameMap()
try {
updateItem(
key,
"SET $pathExpression = $pathExpression + :inc",
"attribute_exists($pathExpression)",
attributesMap,
mapOf(":inc" to increment)
)
} catch (e: ConditionalCheckFailedException) {
tryToCreateMap(key, path, increment)
}
}
private fun UpdateItemApi.tryToCreateMap(key: PrimaryKey, path: List<String>, value: Any) {
val pathExpression = path.toPathExpression()
val attributesMap = path.toNameMap()
val upperPath = path.dropLast(1)
val upperPathExpression = upperPath.toPathExpression()
if (upperPath.isNotEmpty()) {
try {
updateItem(
key,
"SET $pathExpression = :new",
"attribute_exists($upperPathExpression)",
attributesMap,
mapOf(":new" to value)
)
} catch (e: ConditionalCheckFailedException) {
val lastName = path.last()
tryToCreateMap(key, upperPath, mapOf(lastName to value))
}
} else {
updateItem(
key,
"SET $pathExpression = :new",
attributesMap,
mapOf(":new" to value)
)
}
}
С такими мощными условными атомарными обновлениями вложенных полей DynamoDB изрядно приближается по удобству к той же MongoDB. При этом все соглашения по поводу стоимости и производительности остаются в силе. DynamoDB вполне можно использовать для счётчиков realtime подсчёта агрегатов (да, я сам не понял, что сказал :).