О DynamoDB
2018-04-22
Мы — в облаках. Где в облаке взять базу данных?
Можно запустить самую обычную виртуалку, и водрузить на неё какой-нибудь PostgreSQL. Вполне рабочий вариант. Особенно, если это не банальный PostgreSQL, а какая-нибудь редкая БД, которая ещё нигде толком не поддерживается. Свой собственный кластер чего-то экзотичного придётся подымать именно так.
Можно взять тот же PostgreSQL в виде managed ресурса. То, что в амазоновом облаке называется RDS (Relational Database Service). Технически, это будет такая же виртуалка, но чуть дороже. Только установкой СУБД, обновлениями, бэкапами, мониторингом будете заниматься не вы, а облако. Специально обученные киберминьоны, управляемые из облачной консольки. Это очень соблазнительное предложение. Это действительно удобно. Таким образом можно запустить многие популярные реляционные СУБД: MySQL, PosgtreSQL, Oracle, MS SQL Server. И даже парочку популярных кэшей: Memcached и Redis.

А ещё у нас есть сугубо облачные БД. Они живут где-то на мощностях облака. Они — multitenancy, общие мощности облака делятся между множеством клиентов. Поэтому нельзя сказать, что СУБД запущена на какой-то виртуальной машине. Она запущена там, в облаке.
Так как такие СУБД — масштабные распределённые системы, они, как правило, — нереляционные. То есть, NoSQL. Но встречаются и исключения, СУБД, которые выглядят как SQL, но, на самом деле, являются не совсем SQL.
У Амазона есть Redshift. Штука для аналитики. То, что называется Data Warehouse. Вы туда загружаете данные, а потом делаете SQL запросы по данным. Долго. Дорого.
А недавно у Амазона появилась Aurora. Штуковина с сетевым протоколом MySQL или PostgreSQL на выбор. Но полностью облачная. Я не пробовал, но сам Амазон настойчиво склоняет на её использование вместо обычных инстансов RDS.
Вернёмся к NoSQL. В Azure есть удивительнейшая Cosmos DB. Внизу там некий супер-дупер крутой распределённый транзакционный слой. А поверх можно натянуть несколько разных моделей данных, и разных сетевых протоколов. Можно просто key-value, с интерфейсом, совместимым с другой лазурной облачной NoSQL под названием Table. Можно нечто под названием SQL API, а на самом деле хранилище для JSON документов, просто там запросы на чём-то SQL-подобном делаются. Можно сэмулировать протокол MongoDB, тоже документное хранилище получается. Можно сэмулировать протокол Cassandra, получается колоночная БД. А можно хранить графы, причём со стопочкой стандартных графовых API.
Вся эта многослойная мультимодельная концепция Cosmos DB очень сильно напоминает FoundationDB. Там была такая же крутотень, но её можно было запустить у себя. Три года назад FoundationDB с потрохами купила Apple. А буквально на днях её снова выбросили в опенсорц. Надо потыкать, что после Apple там осталось.

Пока же я погрузился в пучины облачной DynamoDB. Кажется, это один из самых древнейших представителей облачных NoSQL. Кажется, DynamoDB была в AWS всегда :) Сначала это было просто key-value хранилище, но постепенно оно обрасло фичами.
Модель данных в DynamoDB подозрительно напоминает Cassandra. Ту Кассандру, что доступна через CQL.
Есть таблицы — уникальные именованные сущности в пределах AWS аккаунта. Таблица — это единица доступа и ограничения скорости.
Запись в таблице называется Item. Каждый Item идентифицируется первичным ключом. Первичный ключ может состоять из двух частей.
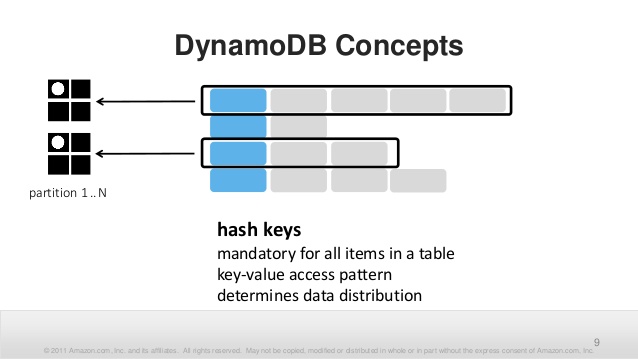
Первая часть, обязательная, — это hash key. Это — некоторое примитивное значение (строка, число, blob), от которого будет считаться хэш. Это — partition key. Хэш определяет партицию, куда будут помещены данные. Партиция — вполне физическая сущность с конкретно ограниченными физическими возможностями. Поэтому partition key нужно подбирать так, чтобы имелось достаточное количество различных значений. Ибо это определяет максимально достижимую физическую производительность операций над таблицей.
Hash key, его конкретное значение, никаких диапазонов или больше-меньше, нужно указывать и в операциях записи, и в операциях чтения. Это накладывает определённые ограничения. Значения ключей или алгоритм их формирования нужно где-то знать. Нет эффективного способа узнать набор уже существующих ключей. В худшем случае нужно выдумать какие-то псевдоключи только чтобы сформировать нужное число партиций.
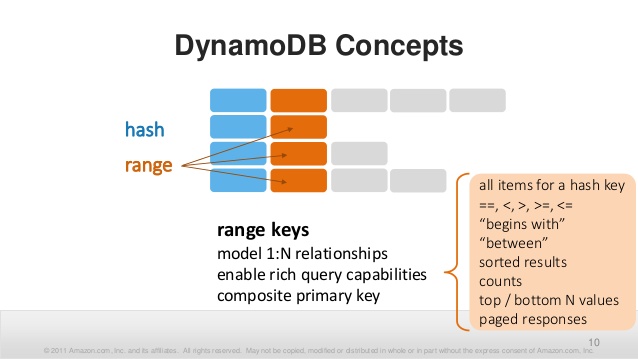
Вторая часть первичного ключа, необязательная, — это sort key. Тоже примитивное значение. Тут возможны уже хитрые запросы по больше, меньше и between. По этому полю, и только по этому полю, можно сортировать. Хорошо, что сортировать можно в обе стороны.
С ключами всё. Выбирать Itemы можно только по этим ключам. Причём partition key — обязателен. Впрочем, есть ещё вторичные индексы, где можно указать другие partition и sort keys по тем же данным. Но по сути, это просто автоматически заполняемая копия данных, проиндексированная по другим полям.
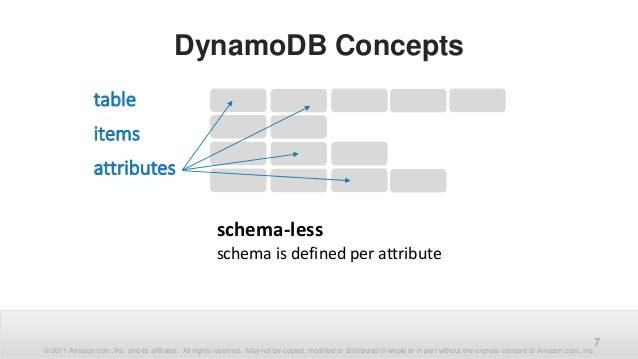
Помимо ключей в Itemах хранятся атрибуты. У атрибутов есть имя — строка. (У ключей, у каждой части, тоже должно быть своё имя). И у атрибутов есть значение. Вот тут интересно.
Можно хранить примитивные типы. Строки, до 400 килобайт. Числа, как в JavaScript подразумевается, что все числа — вещественные. Над числами есть атомарная операция инкремента (на значение, определённое в апдейте), легко делать счётчики. Binary, просто бинарные данные, до 400 килобайт.
Можно хранить множества, set, примитивных значений. Можно добавлять и удалять элементы из множества. Можно хранить списки и мапы. Таким образом можно хранить полноценные JSON документы, только уровень вложенности ограничен 32.
Общий размер Item ограничен теми самыми 400 килобайтами. Всё-таки это не Кассандра. И даже не Монга. Но в рамках этих 400 килобайт можно засунуть сколько угодно атрибутов.
Каждый Item в таблице может иметь свой собственный набор атрибутов, никак не связанный с другими Itemами.
При записи нужно указать первичный ключ и значения атрибутов. Будет сделан upsert, если записей нет, они добавятся, если атрибуты были, они обновятся. Есть операции для модификации чисел, множеств, списков и мапов. Так что можно делать частичные апдейты.
Для чтения есть две операции: Scan и Query.
Scan — это просто последовательный просмотр всей таблицы, с применением фильтров. Scan совершенно никак не оптимизирован и не использует индексы. Поэтому он настоятельно не рекомендуется к использованию. Но он есть.
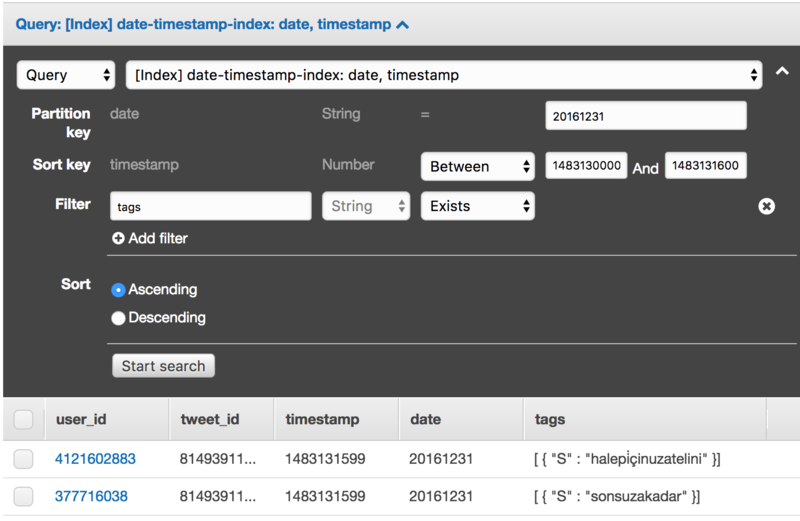
Query — это уже полноценный запрос. Точное значение partition key. Диапазон sort key. Это ограничит набор просматриваемых данных. Направление сортировки. Проекция, можно выбрать лишь часть атрибутов Itemов. Фильтры, можно ещё ограничить содержимое выборки уже по значениям атрибутов. Равно, не равно, больше, меньше, существует, не существует, содержит подстроку, начинается с подстроки. Много проверок можно сделать. Но фильтры не улучшают производительность запроса, ибо поиск делается только по ключам. Но могут сэкономить немного трафика.
Работать с DynamoDB проще всего через сооветствующее SDK. Под Java там вполне приличное ООП, позволяющее конструировать запросы из объектов. Явовые коллекции совершенно прозрачно кладутся во множества, списки и мапы. Но на низком уровне там API через HTTP. Так что в простеньких случаях можно взять обычный HTTP клиент.
С этой моделью данных можно натворить почти всё, что угодно. Нужно только быть аккуратнее с partition key. Там не должно быть одного-двух значений, тогда будет слишком мало партиций. Туда не стоит помещать время или что-то монотонно возрастающее. Во-первых, при запросе придётся перебирать каждую секунду (или какая у вас там гранулярность). Во-вторых, будет эффект «горячей» партиции, когда вся запись идёт в «сегодня».
Самое интересное: производительность и деньги. В облачных БД одно с другим неразрывно связано.
Платить надо. За «единицы ресурса записи», сколько операций записи в секунду будет разрешено. За «единицы ресурса чтения», сколько операций чтения в секунду будет разрешено. При этом под «операцией» понимается запись чего-то не более 1 килобайта, или чтение чего-то не более 4 килобайт. Чтение значительно (раз в десять, или даже в сорок, если объёмы сравнивать) дешевле записи. За объем хранимых данных, погигабайтно. За передаваемые данные, тоже погигабайтно в месяц. Входящие (то есть запись) — бесплатно. Исходящие (то есть чтение) — нет.
Дабы не мучиться с подсчётом нужных «единиц ресурса» можно настроить автомасштабирование этих параметров. Но, похоже, это может привести к попаданию на бабки при внезапном всплеске активности.
Кстати, помните, что скорость ограничивается для каждой таблицы отдельно, и равномерно пилится между партициями. Опять partition key важен. И хоть производительность — штука платная, она тоже имеет ограничение. Впрочем, текущих десятков тысяч попугаев вроде должно хватить всем.
Также отдельно надо платить за репликацию (в том числе и между датацентрами), за бэкапы, за дополнительные инстансы кэша (ухты, есть и такое), за DynamoDB Streams и за триггеры.
Streams — это возможность проиграть все операции записи в БД куда-то ещё. Например, скормить их в Lambda и сделать там что-нибудь полезное.
Триггеры в DynamoDB — это такие же Lambda, которые могут влиять на результат записи. При их использовании придётся платить за Lambda.
Сама DynamoDB неплохо интегрируется с инфраструктурой AWS. Данные из DynamoDB можно скормить в тот же Redshift. Или натравить на таблицы DynamoDB целый Hadoop и делать агрегирующие запросы на HiveQL. (В самой DynamoDB никаких group by нет).
Получается нормальный такой облачный NoSQL. Если уж вы оказались в AWS, и вам нужно довольно быстро или очень много данных, попробуйте начать с DynamoDB. Возможно, её вполне хватит. А если не хватит, данные можно перегрузить во что-нибудь более мощное.
UPD
Триггеры на Lambda — это, всё-таки, не совсем триггеры в обычном понимании.
Это действительно информация об изменениях в каждом item в БД,
с указанием предыдущего и нового значения itemа.
Но это, через Stream, просто скармливается Lambda
(и надо ещё попотеть, чтобы разобрать этот JSON).
А вот что с этим будет делать Lambda — её личное дело.
Без проблем можно писать в другую таблицу DynamoDB.
Можно писать и в ту же таблицу, но тогда появится цикл, который нужно разомкнуть:
запись от Lambda тоже попадёт в Stream и снова окажется на входе Lambda,
и она должна её проигнорировать.