О Lambda
2018-03-25
Итак, микросервисы. В амазоновом AWS. Отложим в сторону тот факт, что микросервисы на JVM будут не очень микро. Им нужны сотни мегабайт памяти для нормальной работы. Нас интересует вопрос: как запускать сервисы?
Очевидно, можно запустить виртуалочки EC2, с любимой ОС. Поставить туда любимую среду выполнения. И запускать любимые микросервисы, или макросервисы, или даже громадные монолиты. Не проблема.
Можно взять Докер и разворачивать сервисы в виде контейнеров в Elastic Container Service (ECS). Можно приплести и Kubernetes в виде EKS. Контейнеры по-прежнему подразумевают, что портами, запросами, библиотеками, репозиториями, развёртыванием занимаетесь вы сами, пусть и манипулируя сущностями AWS.
Идём дальше. А дальше у нас — феномен под названием Serverless computing.
Идея такая. Вы ничего не знаете о серверах, ни виртуальных, ни реальных. Вы ничего не знаете о выделенных ресурсах. Порты, инстансы, балансеры — всё у вас отобрали. Сама инфраструктура становится фреймворком, который вызывает ваши обработчики, когда нужно. Вот такие обработчики в AWS называются Lambda. В Azure это называется Functions.

Написать Lambda на Java или Kotlin довольно просто. Вам нужен код обработчика. Это может быть либо типизированный обработчик, принимающий и возвращающий некие объекты, которые, на самом деле, сериализуются и десериализуются в/из JSON.
class Handler: RequestHandler<InputData, ResultData> {
override fun handleRequest(input: InputData, context: Context): ResultData {
context.logger.log("Input: $input")
//...
return ResultData("OK")
}
}
Или же это может быть обработчик, просто принимающий и возвращающий потоки бинарных данных. И уж он-то сам может извратиться с нужной ему сериализацией.
class Handler: RequestStreamHandler {
override fun handleRequest(input: InputStream, output: OutputStream, context: Context) {
val inputReader = input.reader()
val messages = parser.parse(inputReader)
//...
output.writer().apply {
println("OK")
flush()
}
}
}
Можно и без реализации каких-либо интерфейсов, главное, чтобы сигнатура метода была понятна Lambda.
Context
— это специальный объект,
дающий некоторое представление о том,
где выполняется наша лямбда.
Помимо примитивного логгера (println() ничуть не хуже),
там есть метод getRemainingTimeInMillis(),
который,
очевидно,
говорит, сколько времени у вас осталось.
А логи,
будь то stdout, Log4j или даже SLF4J,
всё равно попадут в CloudWatch.
Настраивать лямбды, передавать им параметры, можно только переменными окружения. При создании лямбды можно выставить что-то своё. Но целая туча переменных передаётся автоматически. Включая ключи и секреты доступа к самому Амазону. В результате клиенты из AWS SDK, которые можно использовать в лямбдах, получают доступ к сервисам Амазона автоматически.
Конечно, доступ к сервисам лямбде даётся не просто так. Lambda работает от явно определённой роли AIM. Это такая служба раздачи прав в Амазоне. Какие права в роли пропишете, такие права лямбда и получит. Ни больше, и ни меньше.
Лямбды можно писать на Node.js, Java 8, Python, втором или третьем, .NET Core или Go. Код лямбд загружается zip архивом. В случае Java можно загрузить jar архив. Только это должен быть абсолютно классический super jar. Безо всяких извращений, которые могут туда привнести Shade или Spring Boot. Но все зависимости нужно тащить с собой, там будет голая Java.
Из Ansible лямбда загружается примерно так:
- name: create Lambda
lambda:
region: '{{ aws_region }}'
aws_access_key: '{{ aws_access_key }}'
aws_secret_key: '{{ aws_secret_key }}'
name: '{{ lambda_name }}'
state: present
zip_file: '{{ lambda_file }}'
runtime: 'java8'
role: '{{ lambda_role }}'
handler: '{{ lambda_handler }}'
timeout: '{{ lambda_timeout }}'
memory_size: '{{ lambda_memory_size }}'
# vpc_subnet_ids:
# - subnet-123abcde
# - subnet-edcba321
# vpc_security_group_ids:
# - sg-123abcde
# - sg-edcba321
environment_variables: '{{ lambda_environment }}'
Регион и ключи. Как обычно, для любого обращения к API AWS они нужны.
Имя лямбды. Имя уникально для AWS аккаунта. Это тот самый адрес, под которым лямбда будет доступна из других сервисов.
Zip файл. Тот самый zip или jar, содержащий код лямбды.
runtime указывает,
в какой среде будет запускаться лямбда.
Для JVM есть только «java8».
role — это AIM роль
вида «arn:aws:iam::123456789012:role/YourLambdaRole».
Роль определяет права лямбды в AWS.
handler — это имя метода-обработчика.
Для Java это будет что-то вроде
«your.java.package.Handler::handleRequest».
timeout — допустимое время выполнения обработчика,
в секундах.
Это время жёстко ограничено.
Если время выйдет,
обработчик принудительно завершится.
Можно поставить любое малое значение,
но не более 300 секунд.
Лямбды должны выполняться быстро.
memory_size — лимит по памяти,
в мегабайтах.
Жёсткий лимит.
Больше памяти просто не будет.
Мало памяти — Java будет тормозить
и падать с OutOfMemoryError.
Минимум — 128 мегабайт,
для hello world на Java хватает.
Но для работы DynamoDB SDK
нужно хотя бы 256.
По умолчанию лямбда работает где-то в своих облаках. У неё есть доступ в интернеты и к большинству managed сервисов AWS. Но некоторые сервисы недоступны из интернетов, а живут в вашем приватном VPC, например, так работает ElastiCache. Поэтому лямбду иногда тоже надо запускать в VPC, дав ей соответствующие права.
environment_variables — это ваши переменные окружения,
через которые вы хоть как-то можете
сконфигурировать лямбду.
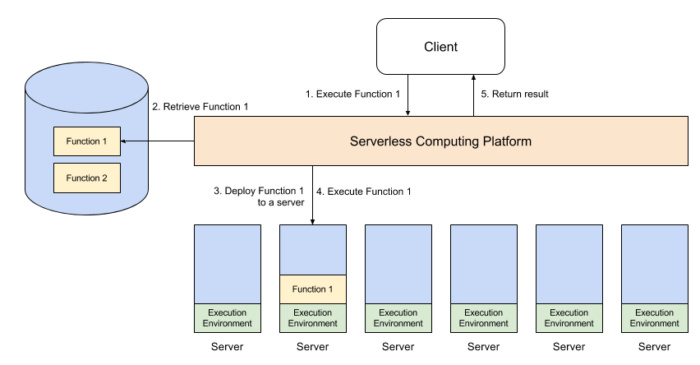
Лямбду задеплоили, теперь её можно вызывать. Как, зачем и откуда? Это самое интересное.
Множество сервисов AWS могут порождать события, которые могут вызвать (trigger) вызов лямбды. При этом само событие придёт на вход обработчику лямбды, и лямбда сможет с этим что-то сделать.
Файлопомойка S3 может вызывать лямбды на события создания, модификации и удаления объектов-файлов.
Нереляционная база данных DynamoDB может вызывать лямбды на операции записи. И это будут самые настоящие (и единственные доступные) триггеры в этой БД.
Сервис уведомлений SNS. Это такой облачный publish-subscribe с поддержкой подписчиков в виде телефонов для СМС, емейлов для почты и даже мобильных пушей. Он может вызвать лямбды. Лямбда фактически подписывается на топик и обрабатывает сообщение.
CloudWatch, сервис мониторинга всея Амазона, может вызывать лямбды при наступлении определённых событий. Например, когда в очереди SQS накопились сообщения. Сама SQS не умеет лямбды, но через CloudWatch можно таки вызвать лямбду, а она уже разгребёт очередь. Ну или просто по расписанию, есть в CloudWatch и такие события.
Amazon Alexa — персональный ассистент от Амазона. Говорящий динамик. Самый верный способ разрабатывать для него — писать свои лямбды-обработчики.
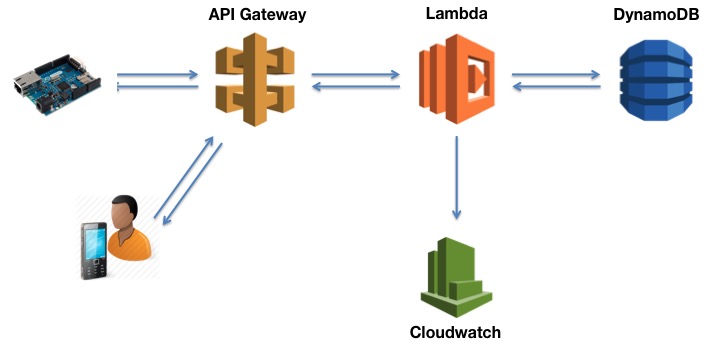
Amazon API Gateway. Serverless веб сервер. Вы определяете правила маршрутизации запросов, а обработку делают ваши лямбды. Микросервиснее и облачнее уже некуда, кажется.
AWS IoT Button. Волшебная кнопка "Сделать всё хорошо". Настоящий физический брелок с кнопкой в реальном мире. Нажатие на кнопку вызывает вашу лямбду в облаке.
Просто AWS IoT. Загадочный сервис интернета вещей. Как минимум, он умеет принимать сообщения по, внезапно, популярному протоколу MQTT, который, как оказалось, широко используется в этом IoT, и скармливать эти сообщения вашей лямбде.
И конечно же, лямбду можно запустить из лямбды. Запуск лямбды — это нормальная часть AWS SDK, которую вполне можно использовать.
Ну вы поняли, да? Лямбды — это автоматизация всего в облаке. Лямбды — это всё. Ну или почти всё.
Но как же и где же это выполняется? Тем более, что Java (да и JavaScript) — далеко не самый лучший язык для написания скриптов. Java долго запрягает, требует много памяти, начинает быстро работать только после основательного «прогрева», т.е. неоднократного выполнения этих наших запросов.
Я не нашёл внятного описания среды выполнения. Известно, что это Amazon Linux (подвид RedHat Linux). Упоминаются контейнеры. Практика показывает, что первый прогон (после деплоя) лямбды на Kotlin, с записью в DynamoDB (используя стандартный Java SDK) выполняется секунд за 30. Долго. Но довольно быстро время снижается до 60 миллисекунд.
Так что хорошая новость в том, что лямбды запускаются один раз, а потом обслуживают множество запросов. Соответственно, прогрев наших любимых JIT вполне себе имеет место. А учитывая, что ограничения по памяти выполняются очень жёстко, это всё действительно запускается в контейнере.
Получается, что код лямбды разворачивается где-то в контейнере. И живёт, и выполняет запросы непрерывно. Более того, одновременно может быть запущено несколько лямбд, максимум до тысячи штук. И, похоже, это масштабирование происходит автоматически. Полагаю, верно и обратное, что в отсутствие запросов последний контейнер будет остановлен, и затем заново случится холодный старт.
Кстати, холодный старт лямбды в VPC будет дольше где-то на минуту. Потому что для лямбды будет выделяться Elastic Network Interface.
Получается, реально всю заботу об инфраструктуре здорово запрятали. Всё бы ничего, но отлаживать это дело тяжеловато. Поди пойми, что там у тебя случилось, нехватка памяти или сетевой таймаут, если лямбда была убита раньше по собственному лимиту времени выполнения.
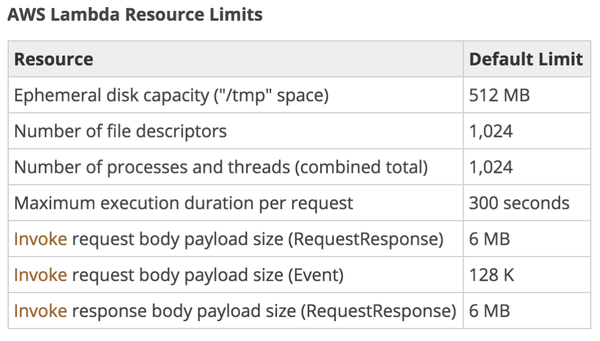
Почему лимиты на время и память? Потому что платить за лямбды нужно, исходя из времени работы обработчика, и указанного лимита памяти. Ну и немного исходя из количества запросов, если их миллионы. Время округляется до 100 миллисекунд.
В кои-то веки снова приходится писать так, чтобы было быстро и ело мало памяти. Прощай, Spring Boot, я буду по тебе скучать :)
Кстати, начинают появляться фреймворки для писания и деплоя именно под Lambda. Serverless для Node.js. Zappa для Python.
И, тссс... Эти самые Dynos от Heroku — это ж и есть эти самые лямбды.