Об Ansible
2018-01-07
Начнём новый год с буквы «A». Ansible.
Кстати, Анзи́бль — это такая фантастическая фиговина для мгновенной связи на межгалактических расстояниях.
А Ansible — это программка для удалённого запуска команд и совершения прочих нужных действий на куче серверов. Мы её используем для настройки серверов и деплоя наших сервисов уже на нескольких проектах.
Ансибл — чертовски гибкая штука. Настолько гибкая, что без определённых соглашений все эти таски и плейбуки легко превращаются в нечитабельную немодифицируемую глючную лапшу. Чего только стоит, что переменные в Ансибле можно определять индивидуально для каждого хоста, для группы хостов, умолчательные значения для роли, просто переменные для роли, переопределять в плейбуке, из командной строки, конкретно для данной задачи. А ещё переменные могут создаваться в результате выполнения задач, и использоваться в последующих задачах. А ещё есть факты, то есть переменные, автоматически собранные при инспектировании хостов, типа объема памяти, размера дисков и набора сетевых интерфейсов. Ужос.
Эмпирическим путём у нас сложились правила использования Ансибла. В основном вдохновлённые и следующие статье Миши Бланка «Laying out roles, inventories and playbooks».

Все ансибловые файлы у нас валяются в подкаталоге ansible самого проекта.
Вообще, идеология Ансибла подразумевает,
что должны быть универсальные переиспользуемые роли,
выкладываемые в Ansible Galaxy,
единый конфиг в /etc,
единый набор Inventory на все окружения,
с которым работает данный юзер,
и лишь плейбуки,
специфичные для данного проекта.
Но на практике с универсальностью ролей всё плохо. Во-первых, страшно запускать фиг знает кем написанную роль от рута на десятках серверов. Во-вторых, написать действительно универсальную роль весьма сложно, поэтому роли из Galaxy всё равно приходится подпиливать по свои нужды. Проще написать неуниверсальную роль для данного проекта. В-третьих, роли очень быстро устаревают, ибо версии софта, который они устанавливают, стремительно меняются. А мейнтейнить проще простые специфичные роли.
Вот поэтому у нас не сложился общий репозиторий ролей. Некоторые роли просто копируются из другого проекта. А остальные 90% пишутся под этот проект. Всё лежит под системой контроля версий проекта, и всё хорошо.
Начинается всё с файла ansible/ansible.cfg:
[defaults]
inventory = inventories/development
inventory_ignore_extensions = ~, .retry, .pyc, .pyo, files, templates
roles_path = roles
pipelining = True
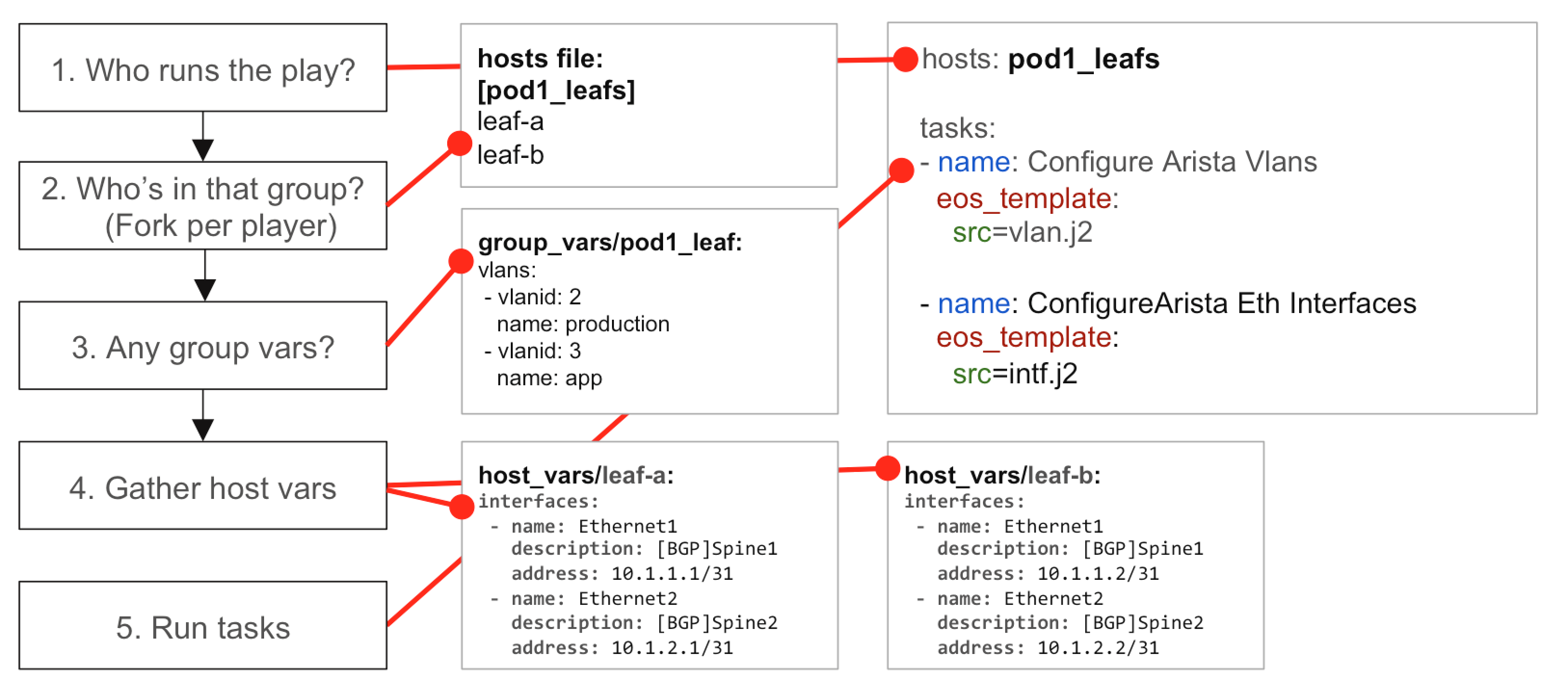
Далее Inventory. Инвентарь. Это ваши хосты. По группам. Инвентарей будет много. Потому что окружений будет много: ну это всё тестовое, продакшен и т.п. На каждое окружение — свой Inventory.
В hostfile стоит прописать значащие имена хостов.
Лучше доменные имена,
но если доменных имён нет,
стоит что-нибудь внятное вместо них придумать,
а правильный IP указать как ansible_host.
Ну и юзера, и ssh порт,
и прочие параметры подключения
для каждого хоста указать.
[etl-server]
etl1 ansible_host=172.18.40.37 ansible_user=ubuntu ansible_become=yes
В группу должны входить абсолютно одинаковые хосты.
Ну которые нужно одинаково настроить.
Потому что переменные удобнее и правильнее назначать на группы,
и в плейбуках правильнее вызвать роли на всю группу.
Разве что первый (нулевой) хост в группе
может быть особенным (для хостов из других групп),
на него можно ссылаться как {{ groups['etl-server'][0] }}.
Кроме перечисления собственно хостов и групп в Inventory можно поместить шаблоны и файлы. Вообще-то, это не Ansible-way. В Ансибле подразумевается, что шаблон должен быть один, где-нибудь в роли. А все нюансы и хитрости под конкретное окружение должны задаваться переменными, а также условиями и циклами в шаблоне. Это ж Jinja2, там всё можно.
Вот только сопровождать сложный универсальный шаблон,
как правило,
сложно.
Ну и юзерам ещё и шаблонизацию Ансибла объяснять?
Ты тут только-только устаканил набор всех возможных переменных
в application.yml,
более-менее описал их все в Вики.
А теперь ещё и шаблон родить,
и переменные Ансибла придумать,
и снова это всё задокументировать?
В общем, имеет смысл файлы и шаблоны складывать в Inventory тоже. Если это действительно сложные файлы, радикально отличающиеся для разных окружений.
ansible
├── ansible.cfg
├── inventories
│ ├── production
│ │ ├── group_vars
│ │ │ └── all
│ │ ├── hosts
│ │ └── templates
│ │ └── etl-server
│ │ └── application.yml
│ └── infrastructure
│ ├── group_vars
│ │ └── teamcity-server
│ └── hosts
...
Чтобы так делать,
нужно использовать каталог (а не файл, который hostfile) Inventory,
и определять inventory_ignore_extensions в ansible.cfg.
Использовать такой шаблон,
заданный в Inventory,
можно так:
template:
src: '{{ inventory_dir }}/templates/etl-server/application.yml'
dest: '{{ etl_basedir }}/config/application.yml'
owner: '{{ etl_user }}'
backup: yes
Нужно быть осторожным, если Inventory содержит ключи да пароли. Ведь оно лежит в репозитории. Для публичных проектов нужно будет использовать Ansible Vault.
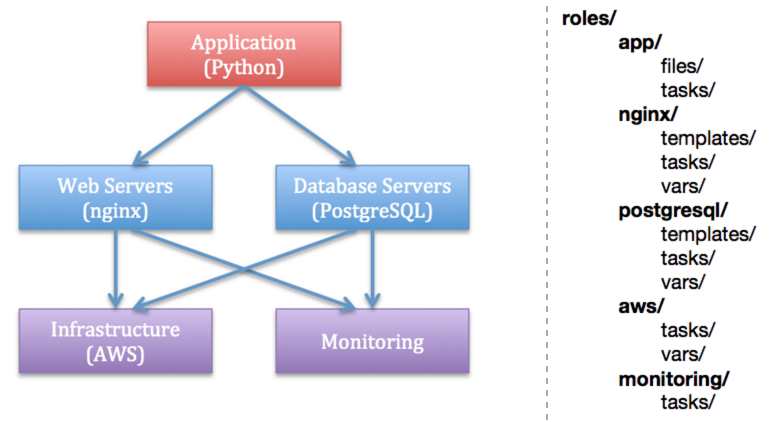
Roles. Роли. Тут самое мясо. Тут команды, которые, собственно, что-то делают.
Начинается всё с подкаталога roles,
а дальше идут каталоги, чьи имена соответствуют названиям ролей.
ansible
...
├── roles
│ ├── common
│ │ ├── defaults
│ │ │ └── main.yml
│ │ ├── handlers
│ │ │ └── main.yml
│ │ └── tasks
│ │ ├── common-firewall-disable.yml
│ │ ├── common-firewall.yml
│ │ ├── common-locales.yml
│ │ ├── common-ntp.yml
│ │ └── main.yml
│ ├── etl-deploy
│ │ ├── defaults
│ │ │ └── main.yml
│ │ ├── handlers
│ │ │ └── main.yml
│ │ ├── tasks
│ │ │ ├── etl-deploy-config.yml
│ │ │ ├── etl-deploy-jar.yml
│ │ │ └── main.yml
│ │ └── templates
│ │ └── application.yml.jinja2
│ ├── etl-provision
│ │ ├── defaults
│ │ │ └── main.yml
│ │ ├── handlers
│ │ │ └── main.yml
│ │ ├── tasks
│ │ │ ├── etl-provision.yml
│ │ │ └── main.yml
│ │ └── templates
│ │ └── service.jinja2
│ ├── java
│ │ ├── defaults
│ │ │ └── main.yml
│ │ └── tasks
│ │ ├── java-install.yml
│ │ └── main.yml
│ ├── mongodb-install
│ │ ├── defaults
│ │ │ └── main.yml
│ │ ├── files
│ │ │ ├── logrotate.config
│ │ │ └── mongod.service
│ │ ├── handlers
│ │ │ └── main.yml
│ │ ├── tasks
│ │ │ ├── main.yml
│ │ │ ├── mongodb-configure.yml
│ │ │ ├── mongodb-install.yml
│ │ │ └── mongodb-logrotate.yml
│ │ └── templates
│ │ └── mongod.conf
│ ├── nginx
│ │ └── tasks
│ │ ├── main.yml
│ │ ├── nginx-configure.yml
│ │ └── nginx-install.yml
│ ├── spark
│ │ ├── defaults
│ │ │ └── main.yml
│ │ └── tasks
│ │ ├── main.yml
│ │ └── spark-install.yml
│ ├── teamcity-install
│ │ ├── defaults
│ │ │ └── main.yml
│ │ ├── handlers
│ │ │ └── main.yml
│ │ ├── tasks
│ │ │ ├── main.yml
│ │ │ ├── teamcity-dir.yml
│ │ │ ├── teamcity-download.yml
│ │ │ ├── teamcity-jdbc.yml
│ │ │ ├── teamcity-service.yml
│ │ │ ├── teamcity-tools.yml
│ │ │ └── teamcity-user.yml
│ │ └── templates
│ │ └── service
│ ├── teamcity-nginx
│ │ ├── defaults
│ │ │ └── main.yml
│ │ ├── handlers
│ │ │ └── main.yml
│ │ ├── tasks
│ │ │ ├── main.yml
│ │ │ └── teamcity-nginx.yml
│ │ └── templates
│ │ ├── config
│ │ └── websocket.conf
...
В роли мы объединяем таски,
которые выполняют какой-то связанный набор настроек,
на определённой группе хостов,
в определённый момент жизненного цикла продукта,
который можно переиспользовать для разных групп хостов.
Получается какая-то роль common для настройки локалей,
NTP,
включения файервола.
По роли на установку и настройку нужного софта:
Java, Spark, MongoDB, всё, что душе угодно.
В простейшем случае эти роли просто ставят нужные пакеты.
В более сложных случаях нужна ещё хитрая подгонка по месту.
И роли на установку наших сервисов. Тут важен момент, когда роль нужна. Поэтому на каждый сервис получается, как правило, две роли. Одна делает provision: создаёт юзеров, каталоги, юнит systemd. Её для данного хоста достаточно запустить один раз, более ничего из этого на данном хосте меняться не будет. Другая роль делает deploy: копирует jarник/бинарник сервиса, настраивает конфиг по шаблону, перезапускает сервис. Её нужно запускать при каждом деплое, когда код сервиса у нас изменился. Раз делать разные вещи нужно в разное время и с разной периодичностью, это должны быть разные роли.
Внутри роли у нас есть
дефолтные значения переменных,
в defaults/main.yml.
Это можно рассматривать как документацию к роли.
Тут перечислены все переменные,
которые роль использует.
Ну и заданы дефолтные значения,
чтобы роль работала.
Более правильные конкретные значения
следует переопределять в Inventory.
Так как переменные задаются в Yaml, есть соблазн развешать иерархию имён в виде вложенных объектов с именованными свойствами. Но в Ансибле так не принято. Потому что в Ансибл не завезли нормального наследования/переопределения объектов. Поведение по умолчанию: объявление объекта уровнем выше полностью затирает все вложенные определения, и все многочисленные свойства нужно определять заново. Можно сделать, чтобы наоборот, все свойства всех объектов всегда мержились. Но тогда нельзя убрать свойство, определённое где-то ранее. В общем, лучше с этим не связываться, и задавать переменные как независимые примитивные значения, в худшем случае — списки. А для разделения пространств имён использовать префиксы через подчёркивание.
Далее в роли есть шаблоны,
в templates,
и файлы,
в files.
Разница в том,
что файлы пересылаются на удалённый хост как есть,
например,
таском copy,
а шаблоны сначала прогоняются через Jinja2,
таском template.
Соответственно,
эти таски и ищут по умолчанию файлы и шаблоны своей роли
в этих самых каталогах.
В tasks/main.yml у нас определяются таски.
Но товарищ Бланка рекомендует в main.yml
сами таски не писать,
а инклудить другие файлы с тасками,
проставляя при этом теги.
---
- include: 'mongodb-install.yml'
tags:
- mongodb
- mongodb:install
- include: 'mongodb-configure.yml'
tags:
- mongodb
- mongodb:configure
- include: 'mongodb-logrotate.yml'
tags:
- mongodb
- mongodb:logrotate
Правда, в Ansible 2.4
простой как пробка include задепрекейтили в пользу
статических и динамических инклудов.
Похоже,
теперь нужно использовать import_tasks.
Теги нужны, чтобы выполнить роль частично. Это бывает нужно. Это позволяет здорово сэкономить время. В идеале, конечно, нужно бы, для набора задач, которые запускаются отдельно, выделить отдельную роль, и отдельный плейбук. Но отдельную роль нельзя запустить из командной строки.
Допустим, известно, что нужно поправить конфиг грешной Монги. Но точно неизвестно, как именно. Приходится пользоваться методом научного тыка, и совершать несколько итераций, экспериментируя на одном хосте. Можно делать всё руками, а потом не забыть перенести изменения в Ансибл. Можно делать всё в Ансибле, но тогда, чтобы пропустить этапы установки MongoDB, а выполнить только замену конфига на конкретном хосте, можно задать теги и хост:
$ ansible-playbook -i inventories/production mongo-install.yml -t mongodb:configure -l mongo1
Ещё в ролях есть handlers.
Это такие таски,
которые запускаются только один раз
после успешного выполнения других тасков,
если эти таски что-то изменили.
Жизненно необходимая вещь
для перезапуска сервисов,
если менялись бинарники или конфиги.
И неперезапуска,
если не менялись.
Полезно, кстати, последним таском в роли добавить команду валидации этих самых конфигов. Например, для nginx это может выглядеть так:
---
- name: copy nginx configuration
template:
src: 'config'
dest: '/etc/nginx/sites-available/{{ teamcity_nginx_site_config }}'
notify: restart nginx
- name: disable default nginx configuration
file:
path: '/etc/nginx/sites-enabled/default'
state: absent
notify: restart nginx
- name: enable nginx configuration
file:
src: '/etc/nginx/sites-available/{{ teamcity_nginx_site_config }}'
dest: '/etc/nginx/sites-enabled/{{ teamcity_nginx_site_config }}'
state: link
notify: restart nginx
- name: validate nginx configuration
command: '/usr/sbin/nginx -t'
changed_when: false
Тогда этот хэндлер перезапустит nginx, только если конфигурация изменилась, и она правильная:
---
- name: restart nginx
service:
name: nginx
state: restarted
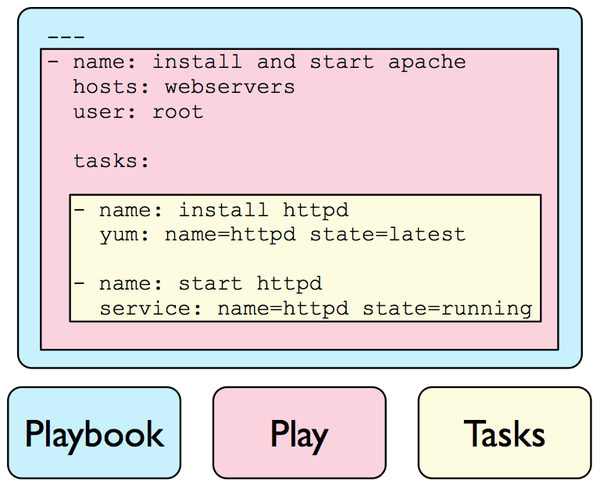
Playbooks. Плейбуки. Игровые книжки. Это Yaml файл, который объединяет Inventory, точнее группы хостов, где это должно играться, с ролями, то есть тем, что должно играться.
Получается, на каждый независимый шаг развёртывания всей системы создаётся свой плейбук. Их получается довольно много, но меньше, чем ролей. На каждую группу серверов, которую можно (или нужно) настраивать отдельно — свой плейбук. На каждый наш сервис: пара плейбуков — для provision и deploy. Собственно, разработчикам нужны только deploy плейбуки, чтобы запускать их, когда меняется код. А остальное запускается лишь один раз, либо когда появляется новый сервер.
Сам плейбук прост: это просто связь групп и ролей. Если у вас одно единственное Inventory, можно даже сделать файл исполняемым и снабдить shebangом.
#!/usr/bin/env ansible-playbook
---
- name: Provision MongoDB server
hosts: mongodb-server
roles:
- common
- mongodb-install
Можно поместить плейбуки в подкаталог playbooks,
но нам пока хватало их россыпи прямо в каталоге ansible.
Чтобы не запутаться мы делаем Makefile
с самыми частыми вариантами запуска ansible-playbook.
Если плейбук завалился с ошибкой,
Ансибл создаёт .retry файл рядом с файлом плейбука,
куда записывает те хосты,
где выполнение завершилось с ошибкой.
Чтобы можно было сделать
ansible-playbook playbook.yml --limit @playbook.retry.
Не забудьте добавить *.retry в .gitignore.
Вот так и живём с Ansible. Успешно.
Пользы от Ansible много. Это документация того, как должна развёртываться система. Грамотно написанные роли легко читаются, и из них вполне можно расшифровать конкретные команды, если, не дай бог, придётся настраивать вручную. Это работающие скрипты, которые с весьма высокой вероятностью приведут нужный набор хостов в нужное состояние. В случае stateless сервисов можно позволить себе роскошь безвозвратно потерять парочку серверов, ибо поднять новые точно такие же с помощью Ansible — дело пары минут.
Сейчас придётся делать микросервисы, запускаемые в облаке. Чувствую, что придётся изрядно переосмыслить роль Ansible во всём этом. Возможно, понадобится универсальная роль для деплоя любого сервиса. Возможно, эту роль нужно будет запускать не на каком-то удалённом хосте, а локально, чтобы управлять облаками через их API. Есть у Ансибла модули и для этого.

P.S. Не факт, что следующая статья будет про букву «B».