О заметках
2016-02-06
Кто-то любит делать заметки в Mindmap. А я не люблю мозгокарты. Мне кажется, что они вполне могут сгодиться как шпаргалка. Но как шпаргалка для конкретных мозгов. Для передачи знаний в другие мозги мозгокарты совсем не годятся. Ибо другие мозги совсем по-другому видят проблему, по-другому классифицируют, по-другому думают. Поэтому передача знаний посредством мозгокарт выглядит как длинная скучная лекция, где лектор пользуется своими мозгокартами-шпаргалками, а слушатели нифига не понимают, пока не переключат свои мозги на волну докладчика.
Да и вообще, любую мозгокарту можно представить вложенным ненумерованным списком. Получится даже компактнее. Но у любого подобного списка остаётся его врождённый недостаток. Это — древовидная иерархия. Однозначная классификация утверждений. А в жизни всё не так. У каждого мозга свои правила классификации. И однозначных иерархий не бывает.
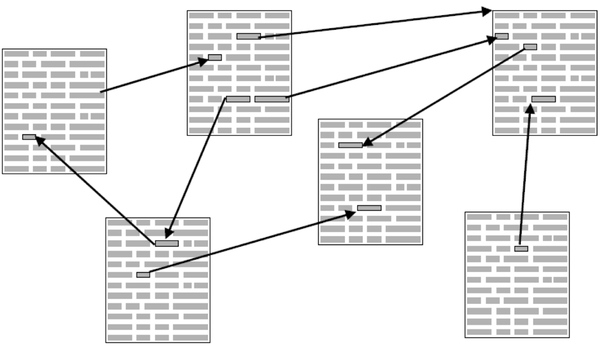
Имхо, идеальный способ представления знаний, заметок и прочего уже давно придумали. Это — гипертекст. Совокупность документов. Каждый документ может содержать всё, что ему угодно. В XXI веке прилично будет иметь в документе форматированный текст, с заголовками и абзацами, с вставленными картинками и, почему бы нет, формулами. Но также документ может содержать ссылки на другие документы. И пользователь должен иметь возможность одним кликом перейти к любому этому другому документу.
Ну вы знаете, World Wide Web — Повсеместно Протянутая Паутина — это и есть реализация идеи гипертекста поверх Интернета, с использованием протокола HTTP, языка разметки HTML и кучи сопутствующих технологий.
У этой реализации есть две слабости. Во-первых, HTML оказался не таким уж и удобным языком, чтобы человеческие существа жаждали писать прямо на нём тексты. Во-вторых, ссылка в Web, которая URL, является односторонней. Автор документа ссылается на другой документ/ресурс/и т. п., но не имеет никакой гарантии, что этот ресурс будет продолжать своё существование в течение всего времени существования ссылающегося документа. С другой стороны, и автор ресурса, на который ссылаются, тоже не имеет надёжного механизма узнать, кто на него ссылается и зачем. Полная распределённость, анархия и разброд.
Предпринимаются попытки как-то улучшить положение. Тот же семантический веб, например. Но бог с ними, с глобальными проблемами. Нам бы разобраться со знаниями в одной конкретной голове или на одном конкретном проекте.
Чтобы быстро-быстро писать гипертекстовые документы придумали вики. Это когда вы пишите не этими ужасными тегами HTML, а на языке сильно попроще. Получается без свистелок и перделок, но вполне строго, красиво и функционально. Или вообще используете WYSIWYG редактор, с кучей кнопочек форматирования.
Кстати, мой любимый Markdown не является языком вики-разметки. Его создавали для других целей: чтобы делать документы, которые были бы одинаково читаемы и в виде простого текста, и в виде «богатого» текста.
А ещё движки вики берут на себя контроль за ссылками. Внутренними ссылками, между страницами одной вики. Можно увидеть, что страница, на которую мы ссылаемся, не существует. Можно взять список всех подобных ссылаемых, но отсутствующих, страниц, и дополнить документацию. Можно увидеть, какие именно другие страницы ссылаются на эту страницу. И даже можно обнаружить страницы, на которые не ссылается никто.
Лучшим вики-движком я считаю Confluence от Atlassian. Если Jira от них же — это неповоротливое монструозное говно, то Confluence — великолепная штука. Даже JetBrains, которые сделали и свой CI (TeamCity), и свой issue tracker — великолепный YouTrack, не стали делать свою вики, и используют Confluence для публичной документации. Да и вообще, море документации в интернетах, если присмотреться, живёт на Конфлюэнсе.
И я просто в восторге от того, как в крайних версиях Confluence подошли к созданию документа. Они скрестили подход с использованием вики-разметки и WYSIWYG. Можно писать вики-теги, а можно тыкать кнопочки форматирования, всё одновременно на одном экране. Просто теги сразу же превращаются в форматированный текст, и на лету получается WYSIWYG. Звучит гораздо страшнее, чем выглядит на самом деле. У них получилось соблюсти баланс между скоростью, удобством и информативностью. Молодцы.

Но остаётся всё та же проблема: иерархия. По идее, в гипертексте документы должны быть связаны друг с другом только ссылками. Соответственно, должны быть какие-то документы-оглавления (ага, index page). Но составлять оглавления вручную — скучно. Для облегчения и автоматизации этой задачи в большинстве вики-движков используют иерархию вики-страниц. У каждой страницы есть страница-родитель, и могут быть свои детишки. Список детишек можно легко вставить в саму страницу — вот и оглавление. А всё развесистое дерево иерархии страниц можно вывести где-то отдельно. В Confluence под это дерево отвели аж целую боковую панель.
Но, как в случае с мозгокартами и списками, возникают вопросы правильности однозначной иерархии. Как нам группировать описание методов API? По задействуемым сущностям? По задействованным подсистемам? По подобластям предметной области? По протоколу доступа? По тому, изменяют ли методы состояние системы? На самом деле, и по тому, и по другому, и по третьему. Хочется всё и сразу.
Один из способов создания неоднозначной классификации — теги, они же метки. Тег — это одно слово, или фраза, которое характеризует содержимое страницы. Мы навешиваем это слово на все страницы, к которым применима данная характеристика. И затем можем увидеть все страницы по этому тегу, или даже страницы по совокупности тегов. Вроде у нас появляется граф страниц. Но связаны эти страницы оказываются лишь со словами-тегами. Как-то сильно плоско. К тому же я еще не видел, чтобы кто-то в здравом уме и трезвой памяти добровольно навешивал бы релевантные теги на все страницы вики. Хлопотное это дело.
Есть ещё поиск. В каком-то смысле его можно рассматривать как автоматический поиск ключевых слов в тексте документов и классификация документов по их содержимому. В результате из нескольких ключевых слов в запросе мы получаем список документов, отсортированный по релевантности. Поиск — это круто. Без поиска жизнь не мила, даже в Confluence. Некоторые системы, вроде StackOverflow, даже сделали поиск (в данном случае от Google) основной точкой входа.

Но мы всё же питаем слабость к иерархиям. Подавай нам дерево-классификатор и всё тут. А можно ли создать несколько альтернативных классификаций по одному и тому же набору документов?
Можно. Для этого нужно вспомнить основы файловой системы Unix. В Unix файл — это вовсе не именованная область на диске, как учат нас школьные учебники информатики. Это действительно область на диске определённого размера. Но у неё нет имени. Есть только номер в некоей таблице ограниченного размера. Так называемый inode. Имя у файла появляется, когда он, под этим самым именем, включается как элемент содержимого некоего каталога. Один и тот же inode может быть включён (в том числе и под разными именами) в разные каталоги. Это называется жёсткой ссылкой.
Количество ссылок на inode учитывается, и когда оно становится равным нулю, и если при этом файл не используется ни одним процессом, файл удаляется. Да, есть такая забавная особенность Unix, даже после удаления файла из каталога он может остаться на диске, если какой-то процесс в него, например, пишет. Даже можно создать новый файл (с другим inode) с абсолютно тем же именем, но старый файл никуда не денется, пока он кому-то нужен.
Ну и давайте концепцию жёстких ссылок применим к документам в вики, заметкам, чему угодно. Пусть документы живут сами по себе, а иерархия их взаимоотношения (каталоги) — сами по себе. Пусть можно включать любой документ в любое место иерархии.
Получится граф документов. Но обращаться с ним можно как с деревом. Так же, как это делается в файловой системе. Хотите просмотреть вызовы API по задействуемым сущностям — пожалуйста. По задействованным подсистемам — пожалуйста. По уровню доступа — пожалуйста.

Эту идею, со множественностью классификаций, я реализовал в маленьком андроидном приложении для заметок. Меня бесило, что разные реализации той же GTD предлагают разные варианты классификации задач, причём с разной степенью обязательности указания разных классификаторов. Где-то обязателен контекст, где-то обязательно нужно указать приоритет... Я решил, ну их к чёрту, все правила. Пусть пользователь решает сам, и придумывает свою собственную классификацию.
Я даже собираюсь пойти дальше и убрать различие между заметкой и каталогом. В конце концов всё это узлы одного графа. Так же как каталоги в файловой системе — это тоже inode, только специального формата.
С мобильными заметками я как-нибудь разберусь. А кто хочет запилить эту идею для вики?