Об асинхронном
2014-06-29
Тамтэк снова тестирует NoSQL. А я тут что-то вспомнил замечания, высказанные после Highload++ Михаилом Епихиным. Про тестирование асинхронными клиентами...

Давным давно, когда Apache httpd был еще версии 1, веб-сервера создавали по новому процессу на каждое новое соединение. Ну и классический CGI так же работает. Ну и inetd (если кто помнит и включал его), позволяет для входящего соединения запускать произвольный процесс (да хоть скрипт) для его обслуживания. Теперь от запуска процессов отказались. Процесс запускается долго. Процесс ест много ресурсов. Некошерно.
Теперешний Apache httpd создает по новому потоку на каждое новое соединение. Потоки легче процессов. Потоки можно насоздавать заранее (тот самый пул). Уже лучше. Но потоки тоже требуют заметных ресурсов, в основном на переключение контекстов (процессору нужно сохранить все регистры в стек, переставить указатель команд, очистить свой кэш и прочее и прочее). Отсюда возникает пресловутая 10k problem. Ну нельзя таким способом обслужить десятки тысяч одновременных запросов. Никакие многоядерные процы (разумной стоимости) не потянут десятки тысяч потоков.
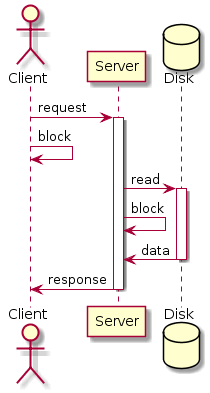
Ну а теперь у нас есть всякие Nginx (почти 10 лет уж) и Lighthttpd. Они работают в одном потоке (ну, точнее, в паре-тройке, чтобы все ядра ЦПУ загрузить). И побеждают десятитысячную проблему. Как?
Весь секрет в системных вызовах вроде epoll. Обычные системные вызовы (по работе с сетью или с диском) — блокирующие. Поток выполнения блокируется (перестает планироваться на ЦПУ), пока нет новых данных (из сети или диска). Epoll — неблокирующий. Один серверный поток мониторит (собственно, делает poll) сразу много дискрипторов (сокетов и файлов). Тупо опрашивает в бесконечном цикле: а есть ли какие-то данные? (Когда данных нет ни в одном дискрипторе, поток может быть так же заблокирован, так что этот цикл не жрет ЦПУ). И если эти данные есть, маленькая порция, они передаются в другой дискриптор (от диска в сеть, например).
Собственно, тут нет ничего особо нового. Все ГУИ с самого начала строятся подобным образом. Есть бесконечный цикл обработки событий. Пока событий (движений или кликов мыши, нажатий клавиш клавиатуры) нет, мы ничего не делаем. Когда события есть, мы быстро их обрабатываем (в обработчиках) и снова уходим в цикл. Просто теперь этот же принцип применили и к обработке сетевых событий.
У этого подхода есть ограничения. Собственно, все руководства по ГУИ про них пишут. Поток один и от скорости его выполнения зависит скорость обслуживания всех событий. Если обработчик события о чем-то задумается (или, о ужас, будет выполнять блокирующие операции), мы потеряем в скорости (ГУИ зависнет). Поэтому делать серьезных вычислений или обращаться к другим ресурсам в обработчиках нельзя. В ГУИ для этого рекомендуют заводить отдельные потоки и уже оттуда передавать результаты длительных операций в основной поток (чтобы обновить УИ). В случае веб-серверов вроде Nginx мы ограничиваем работу сервера только обслуживанием статики (т.е. с одной стороны — сокеты, с другой — файлы). А динамику проксируем на другой, классический сервер (т.е. передаем другому процессу).

Что нам мешает обслуживать динамику на том же сервере? То, что классические языки (веб) программирования поддерживают многопоточную модель (с разделяемыми данными, семафорами и прочим), но не умеют асинхронную обработку. Но все меняется прямо на глазах.
Подход номер раз (по популярности). Обрабатываем асинхронные события обработчиками-колбэками. То бишь на каждое событие по функции (а то и по две — вторая для ошибок). Таков старый добрый питоновый Twisted. Таков нынче популярный Node.js. Все просто, эффективно и функционально. Но описание колбэков колбэков на колбэки чисто визуально выглядит ужасно. И отлаживать это дело жутко, ибо стектрейс начинается где-то с того самого главного цикла и вовсе непонятно, какое событие вызвало ошибку (впрочем, я не знаю, возможно такая проблема с любым асинхроном).
Можно замаскировать колбэки в футуры (они же деферы и промисы). Маскируем асинхронные вызовы под синхронные. Делаем вызов, получаем не настоящий результат, а футуру. Продолжаем выполнение нашего потока, а где-то в фоне происходит что-то, что мы запросили. Позднее, когда нам таки понадобится актуальное значение, мы возьмем его готовенькое из футуры. Очень неявная асинхронность. Плохо, что если мы попросим значение слишком рано, мы таки заблокируемся в его ожидании (впрочем, можно явно cпросить футуру о готовности данных, неблокирующим вызовом). Получается не совсем честно. Хотя выглядит сильно привычнее обычным программистам.
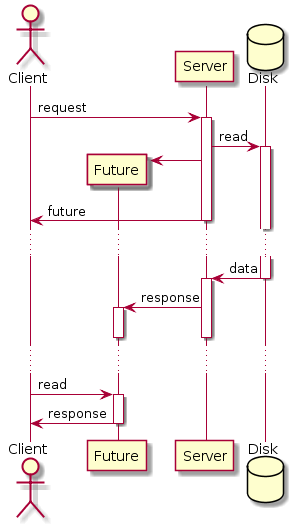
Подход номер три. Акторы (они же легковесные процессы). Это наши любимые Erlang и Go. Это одноименная библиотека в Scala, которая стала частью языка. Это другие подобные библиотеки для других языков. Полностью меняем парадигму параллельного программирования. Не потоки, а акторы. Не вызовы функций или методов, а посылка сообщений. Не разделяемая память, а иммутабельные данные и посылка сообщений. В результате у среды исполнения (или библиотеки) появляется свобода распоряжаться аппаратными потоками выполнения, планировать выполнение акторов, поллить системные события, запускать акторы по приходу сообщений и многое другое. Все совсем по-другому, но наиболее эффективно.

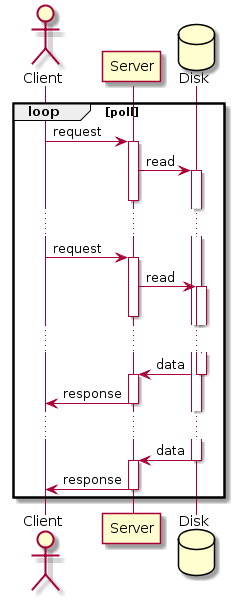
Но асинхронным может быть не только сервер, но и клиент. Один клиентский поток флудит запросы с максимально возможной скоростью, не дожидаясь ответов. Когда таки приходят ответы, он их обрабатывает асинхронно. В случае теста СУБД, нам вообще нужно лишь узнать успешность выполнения и записать время, прошедшее от отправки запроса. Можно отправить громадное количество запросов. Ух.
Если сервер у нас классический, то в рамках одного соединения запросы и ответы следуют строго последовательно. Асинхронному клиенту придется открывать новое соединение для каждого своего асинхронного запроса. Легко можем создать десятки тысяч соединений. Нужно будет ограничить количество одновременных соединений, а то сервер просто захлебнется.
Если сервер у нас асинхронный, то в рамках одного соединения мы можем слать несколько запросов и асинхронно получать ответы (протокол взаимодействия тоже должен быть асинхронным). Чем мы тут ограничены, кроме CPU на клиенте и сервере? Пожалуй, размером очереди запросов (на сервере как минимум), она, к сожалению, не может быть бесконечной. А значит, начиная с какого-то момента запросы будут возвращаться с ошибкой.
В таком клиенте нужно как-то совсем по-другому ограничивать скорость и ресурсы. По-другому генерировать и распределять запросы. По-другому, чем в YCSB. Но и результаты будут более эпичными. Можно ведь положить на лопатки любой сервер.

А какие сервера у нас асинхронные? Как внутри, так и на уровне протокола?
MongoDB — совсем нет. И по потоку на каждое клиентское соединение создается. И блокировки на совместный доступ к данным. И десятитысячная проблема встает во всей красе.
RethinkDB — это такая передуманная Монга. С асинхронными внутренностями и MVCC для хранилища. Но API манипулирует классическими курсорами, а операции всегда возвращают результат или ошибку. Синхронный протокол?
FoundationDB — совсем новое key-value хранилище с упорядоченными ключами и транзакциями. Внутренности асинхронные. Операции возвращают футуры! Оно?
Требуется дальнейшее исследование...
