Об ACID в NoSQL
2014-01-05
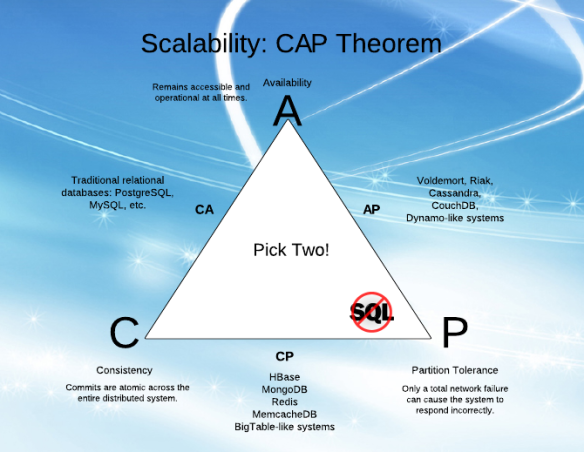
Все знают, что "классические" SQL БД поддерживают свойства ACID. О NoSQL базах говорят, что ACID в них нет, и переводят разговор на CAP теорему и Eventual Consistency. Действительно ли в NoSQL совсем нет ACID?
Что такое ACID?
A — Атомарность. Операция будет либо успешно завершена полностью, либо не завершена вообще.
С — Согласованность. После завершения операции в БД останутся только согласованные (с точки зрения бизнес логики) данные.
I — Изолированность. Другие клиенты (потоки, операции) не видят промежуточных несогласованных данных во время выполнения операции.
D — Надежность. Результаты выполненной операции навсегда останутся таковыми (надежно сохранены на диске).

Вообще-то,
оригинальное определение ACID относится к транзакциям.
Т.е. под "операцией" в определениях выше
следует понимать множество мелких
CRUD операций над данными.
В NoSQL,
как правило,
такие "большие" транзакции не поддерживаются.
Но отдельные операции модификации данных
вполне могут удовлетворять некоторым свойствам ACID.
Отдельным исключением являются NewSQL и графовые БД.
Часто они декларируют поддержку транзакций,
полностью аналогичных таковым в SQL базах,
и это действительно работает.

D — Надежность.
Тут все просто. Оперативную память считаем не надежной. Диск — надежным. Отдельно можно рассматривать дублирование (репликацию) данных, как фактор надежности.
Хуже всего дела обстоят у in-memory баз данных. Для обеспечения надежности им приходится периодически сохранять данные из памяти на диск. Либо синхронно (в рамках вызова операции пользователем) реплицировать данные на другие узлы кластера.
Проще всего тем, кто непосредственно пишет на диск. Как правило, так никто не делает, потому что медленно. Но, например, Aerospike, прекрасно существует, напрямую сохраняя данные на SSD. И при этом быстр.
Раз писать синхронно на диск медленно, будем писать асинхронно. Т.е. будем держать кэш (операций записи) в памяти. Так и поступают большинство БД (и SQL тоже). Чтобы обеспечить надежность в этом случае используется журнал (в PostgreSQL его называют красивой аббревиатурой WAL). В журнал на диске писать быстрее, чем в данные, потому что это строго последовательная запись.
Журнал от рождения есть у Кассандры, там он называется Commit Log. Кассандра считает запись на узел успешной (и возвращает ответ пользователю) немедленно после записи в этот лог.
А вот в Монге журнал
появился
лишь в версии 1.8.
И при неправильном использовании он может
не обеспечить
полную надежность
— запись может считаться успешной и до записи в журнал.
Чтобы дождаться записи в журнал
вы должны указать j: true в
Write Concern.
Если, конечно,
вы готовы пожертвовать производительностью в угоду надежности.

C — Согласованность.
Если говорить о согласованности на уровне одного узла кластера, то тут все неоднозначно. В NoSQL, как правило, нет механизмов контроля целостности данных, нет схемы и нет констрейнтов. В NoSQL, как правило, нет JOINов, и, соответственно, нет внешних ключей. А значит, задача контроля целостности, правильного обновления данных в разных коллекциях и документах ложится на клиента.
Но стоит помнить, что данные можно организовать так, что, даже в отсутствие транзакций, можно обеспечить их согласованное обновление. Такого рода подходы используются, например, в FSFS в Subversion, а также в структуре репозитория Mercurial. Идея состоит в том, что если обновлять данные в правильном порядке, от "листов" к "корню" дерева зависимостей, а читать всегда от "корня", то даже если обновление было прервано, несогласованные данные не будут видны. Ну а если транзакция нужна явно, её можно и сэмулировать.
Если говорить о согласованности данных между узлами кластера, то буква C из ACID становится буквой C из CAP теоремы. Со всем этим грузом выбора между доступностью (и скоростью) и согласованностью. Как правило, нам предоставляется лишь согласованность в конечном счете (eventual). Мы пишем на один узел кластера, и нам обещают, что эти изменения когда-нибудь дойдут до других узлов. Соответственно, клиенты, читающие с других узлов, видят несогласованные данные.
Однако, приличные NoSQL БД
возволяют вам выбрать между C и A.
Здесь действует "классическая" формула
(изложенная у
Фаулера):
W + R > N.
W — это количество узлов,
на которые мы пишем
(дожидаясь надежной записи на каждый из этих узлов).
R — количество узлов,
с которых читаем
(убеждаясь,
что они содержат одинаковые данные и разрешая конфликты,
если это не так).
N — количество одинаковых копий данных в кластере,
т.е. replication factor.
Например,
если у нас в кластере хранится три копии данных,
и мы пишем на два узла,
а читаем также с двух (возможно, других) узлов,
то мы получим вполне согласованные данные
— чтение, произведенное после записи,
гарантированно увидит изменения.
Именно так работает Кассандра. Для каждой операции вы можете указать Consistency Level, как для записи, так и для чтения. Можно указать явное число узлов, которые должны быть задействованы для операции, так и просто "кворум" — больше половины от replication factor.
В Монге все немного по-другому.
Тут узлы в
Replica Set
не равнозначны,
пишем мы всегда в Primary,
а вот читать можем откуда хотим.
Если мы хотим строгой согласованности,
то мы либо можем читать также только из Primary,
что происходит по умолчанию,
но можно и явно указать
Read Preference
(для любой операции чтения)
равным primary или primaryPreferred.
Либо можно дожидаться записи в Secondary,
указав в
Write Concern
(для любой операции записи)
параметр w больше единицы
(это число узлов, в которые должна быть произведена запись).


A — Атомарность. I — Изолированность.
Обычно в NoSQL базовые операции над базовой единицей данных (например, обновление данных по ключу в key-value) являются атомарными и изолированными (в рамках данного узла). Именно тот факт, что хоть что-то тут атомарно, позволяет этими БД пользоваться :)
Однако нужно понимать, что атомарность в кластере NoSQL касается только одного узла. Если операция записи успешно завершилась на одном узле, она может сломаться на другом узле. Узнает об этом клиент или нет, зависит от его настроек (собирался ли он ждать записи на другой узел). В любом случае никто не будет откатывать изменение, произведенное на первом узле. После этого вопрос переходит в область обеспечения целостности данных. Обычно побеждает версия данных, записанная позднее.
Если помните, в SQL существуют уровни изолированности транзакций. NoSQL не может похвастаться таким диапазоном настроек. Тут, если не упоминается изолированность, речь, скорее всего, идет о Read Uncommitted. Если же говорят об атомарности (изредка явно упоминая и об изолированности), то чаще всего подразумевается Read Committed. Более высоких уровней изолированности в NoSQL, как правило, не бывает.
В Монге все просто. Одна операция изменения одного документа является атомарной и изолированной. Примечательно, что в одной операции можно изменять множество полей документа, а также делать операции вроде инкремента числового поля. Однако, одной операцией можно изменить и несколько документов (одной коллекции), в этом случае атомарность распространяется на каждый документ, но не на все множество изменений. Реализована атомарность весьма просто. На весь процесс mongod (а с версии 2.2 — на каждую БД) имеется один единственный lock. Т.е. в рамках одного хоста все операции записи сериализованы (но несколько чтений могут идти параллельно, конкурируя, кстати, с операциями записи).
История атомарности в Кассандре довольно длинна. В версии 1.0 изменения одной строки были атомарны, но не изолированы. Строки в Кассандре довольно длинны (могут содержать что-то около двух миллиардов колонок). Отсутствие изолированности означает, что пока Кассандра меняет колонки в одной строке, другие клиенты могут видеть эти промежуточные изменения. Атомарность же означает, что, если при обновлении какой-нибудь колонки произойдет ошибка, вся строка будет возвращена в первоначальное состояние. В версии 1.1 к атомарности изменения строки добавилась изолированность, используется техника copy-on-write, изменяемые данные дублируются в памяти. В версии 1.2 появились так называемые Atomic Batch — группа операций, которая будет выполнена атомарно (т.е. гарантированно до конца). Батчи существовали и ранее, но при сбоях на сервере их выполнение могло не дойти до конца. Атомные батчи — не изолированы — другие клиенты видят, как меняются строки.
В Кассандре 2.0 появились легковесные транзакции. Разработчики попытались сделать шаг в сторону полностью сериализуемых транзакций, используя модифицированную версию протокола Paxos. Пока что получилось реализовать операции типа read-modify-write — запись обновляется только в том случае, если существующий вариант записи удовлетворяет определенным условиям — что уже весьма неплохо. В Монге, кстати, давно уже есть команда findAndModify с аналогичным функционалом. Но в Монге, как мы помним, всегда есть мастер, владеющий "эталонной" копией данных, тогда как Кассандра — полностью распределенная система с равнозначными узлами.
В общем, транзакций в NoSQL нет. Но многие операции обладают отдельными свойствами ACID, чем нужно и можно пользоваться.
P.S. В Кассандре, кстати, есть счетчики — специальные типы данных для атомарных и согласованных операций инкремента и декремента.
P.P.S. Вот еще пара интересных ссылок:
UPD
Только в поисках картинок к этому посту до меня дошел юмор ребят,
которые предложили аббревиатуру BASE для модели данных NoSQL.
Это ведь не только Basically Available, Soft state, Eventual consistency,
но и основание в химическом смысле.