Об HA-JDBC
2013-12-22
Есть такая, довольно молодая и еще малоизвестная, библиотека HA-JDBC. HA — это High Availability. JDBC — это, очевидно, Java DataBase Connectivity.
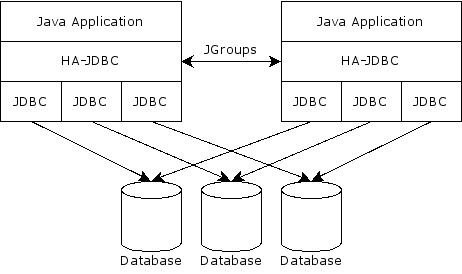
Как и следует из названия, библиотека предназначена для осуществления доступа к вашему высокодоступному кластеру БД посредством JDBC. Это прокси и балансировщик SQL соединений и запросов.
Обычно балансировка SQL запросов осуществляется отдельными демонами. Например, Pgpool для PostgreSQL или MySQL Proxy. HA-JDBC же позволяет добавить "интеллекта" прямо в ваше ява-приложение, добавив возможность подключения одновременно к нескольким СУБД.
Вообще-то что постгресовый, что мускульный JDBC драйверы сами умеют подключаться к нескольким хостам. И, собственно, каким-то образом балансировать нагрузку. Но HA-JDBC позволяет более тонко настраивать как балансировщик, так и другие плюшки.
HA-JDBC также может взять на себя репликацию и восстановление после сбоев. Вы можете взять две (или более) независимых БД, а HA-JDBC будет распараллеливать все запросы записи, чтобы данные во всех базах были одинаковыми. При этом он даже может позаботиться, чтобы всяческие последовательности и автоинкременты в базах совпадали. В случае, если какая-то из БД кластера уходила, а потом вернулась, HA-JDBC может синхронизировать данные на ней, вплоть до снятия дампа с рабочей базы и накатывания его на восстановленную. А чтобы несколько инстансов HA-JDBC (несколько экземпляров вашего приложения) не подрались друг с другом за то, кто будет восстанавливать, HA-JDBC сами объединяются в свой кластер посредством JGroups.
Впрочем, пока я предпочитаю полагаться на встроенные механизмы репликации, а HA-JDBC оставить лишь балансировку нагрузки и отработку падений узлов БД. Собственно, мы имеем два PostgreSQL 9.3 с потоковой репликацией между ними, несколько клиентов с HA-JDBC на борту и балансировку запросов чтения. Характер данных таков, что чтения значительно больше чем записи. Поэтому мы спокойно (и без всяких балансировщиков) пишем в единственный мастер. Полагаемся на потоковую репликацию. И интенсивно читаем с балансировкой и отказоустойчивостью.
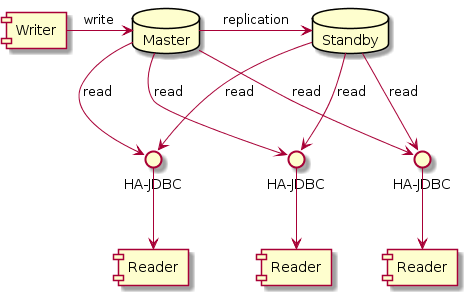
HA-JDBC весьма универсальная штука.
Она может проксировать как старые добрые JDBC драйвера
(где адрес и свойства подключения задаются
в URL вида jdbc:blablabla,
так и DataSource
и даже ConnectionPoolDataSource.
Впрочем,
библиотека не умеет преобразовывать
одни виды подключения в другие.
Если вы запрашиваете HA-JDBC подключение у DriverManager,
библиотека ожидает,
что проксируемые подключения
тоже определены через URL драйвера.
Если же вы запрашиваете DataSource,
то и проксируемые подключения
должны быть определены как DataSource.
Тут главное — не запутаться.
Видимо,
в сложных случаях стоит использовать либо URL драйверов
(где каждое подключение хорошо идентифицируется именно URL),
либо DataSource,
помещенные в JNDI
(тогда у каждого подключения будет свое JNDI имя).
Вариантов синхронизации БД (после сбоев) — множество.
Но так как у меня репликация осуществляется средствами БД,
я поставил просто passive,
т.е. ничего не делать.
Хранить состояние кластера (какие узлы живые и т.п.)
можно в памяти,
можно в SQLite под боком,
а можно в любой SQL базе.
В моем случае simple в памяти выглядел достаточным.
HA-JDBC поддерживает кучу БД (диалектов), включая DB2, Oracle и Sybase. PostgreSQL, понятно, поддерживается.
Я пробовал пару балансеров: round-robin и random.
Почему-то random показал более интересные результаты,
запросы более равномерно распределялись между двумя Постгресами.
У HA-JDBC есть еще различные политики работы с транзакциями (повторять ли транзакцию целиком на втором узле, если она сломалась на одном), идентификаторами, последовательностями и т.п. Так как у меня через библиотеку проходят запросы только на чтение, я все эти возможности просто поодключал.
В общем,
HA-JDBC тупо проксирует подключения к БД.
Например,
если приложение запросило два подключения
(дважды вызвало getConnection() у DriverManager или DataSource),
то HA-JDBC открывает по два подключения к каждой БД.
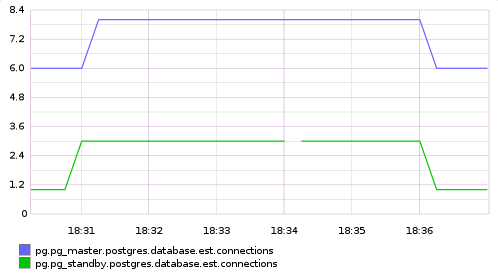
При этом запросы
(именно запросы, Statement, а не подключения)
вполне успешно балансируются между базами.
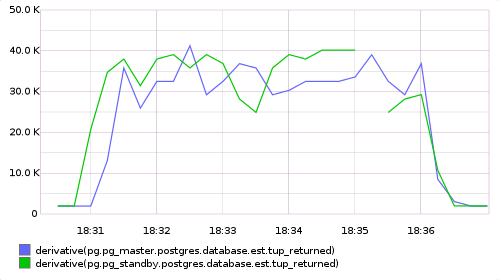
HA-JDBC сразу искаропки успешно отрабатывает проблемы с БД. Я, с помощью фаейрвола, блокировал подключение к одной из БД. Это приводило к исключению при выполнении одного из запросов. Это исключение перехватывалось HA-JDBC, она помечала базу как недоступную. Запрос повторялся на живой базе. И все последующие запросы шли только к живой базе. Примечательно, что исключение даже не доходило до приложения.
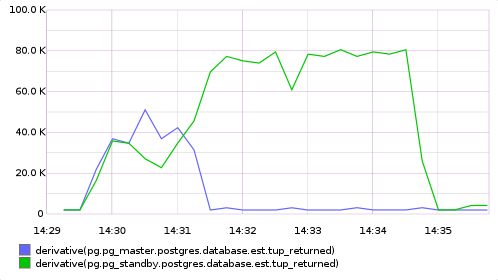
С настройками по умолчанию
HA-JDBC никогда не вернет отключенную базу обратно в кластер.
Можно, конечно,
перезапустить HA-JDBC (т.е. ваше приложение),
тогда
(если вы не использовали персистентное хранилище состояние кластера)
снова будут открыты подключения ко всем сконфигурированным БД.
В рантайме же можно дать понять HA-JDBC о том,
что мы хотим вернуть БД в кластер, через JMX,
есть соответствующий бин.
Ну или можно просто задать расписание
(в Cron-синтаксисе)
проверки доступности отключенных узлов.
Например, так: auto-activate-schedule="\*/15 \* \* ? \* \*".
В моем тесте возникли сложности с активацией
вернувшейся в строй БД.
Приложение открывает подключения к БД
в самом начале эксперимента.
И понятия не имеет,
что там какие-то узлы отключались и подключились обратно.
HA-JDBC все тонкости успешно скрывает.
Т.е. приложение имеет свои два экземпляра java.sql.Connection
и продолжает использовать их.
Однако,
драйвер PostgreSQL тоже не дурак,
он знает,
что запрос на одной коннекции свалился из-за проблем с сетью,
и помечает эту коннекцию как закрытую.
Это не Connection, видимое приложению,
это одно из Connection, проксируемых HA-JDBC.
HA-JDBC, по указанному расписанию,
соображает,
что проблема со связью ушла,
и начинает передавать запросы через закрытое соединение.
Что приводит к новой ошибке, о том,
что соединение уже закрыто.
И HA-JDBC вновь помечает БД как неработоспособную.
В результате БД никогда не возвращается в работоспособное состояние,
а все запросы продолжают падать на БД,
над которой не издевались.
Т.е. HA-JDBC не пересоздает подключения, если с ними возникли проблемы. У MySQL драйвера есть параметр autoReconnect, который, теоретически, как раз и решает подобную проблему. Но у PostgreSQL нет такого параметра.
Казалось бы,
задачей проверки валидности подключений
должны заниматься пулы коннекций.
Я помучал C3P0
и DBCP.
Первый вообще не удалось завести под HA-JDBC,
по всей видимости потому,
что в Яве 1.6 умудрились модифицировать java.sql.Connection,
добавив метод isValid(),
а в сгенерированных прокси C3P0 этого метода еще нет.
Однако выяснилось,
что оба пула проверяют коннекции только в трех случаях:
при получении коннекции из пула,
при возврате коннекции в пул
и в фоне для неиспользуемых коннекций пула.
Коннекции, используемые в приложении,
никем не проверяются.
Ну а если тупо для каждого запроса получать новую коннекцию и закрывать её потом, то получается все хорошо. При возвращении БД в строй запросы снова начинают честно балансироваться.
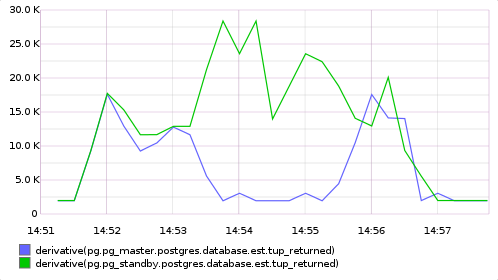
Конечно, открывать коннекцию на каждый запрос — неэффективно. Но, выходит, держать в приложении одну и ту же коннекцию часами — тоже неудобно. Нужно периодически запрашивать новые коннекции, иначе ни HA-JDBC, ни пулы коннекций правильно работать не будут.
Понятно, что нужно использовать пул коннекций, чтобы пул успешно переиспользовал и проверял коннекции. Однако тут возникает вопрос, что правильнее: пул HA-JDBC коннекций или HA-JDBC поверх нескольких пулов. Мне почему-то кажется, что второй вариант правильнее. Осталось только запилить его.
P.S. Код экспериментов и конфигурацию HA-JDBC можно подглядеть на Bitbucket.
P.P.S. Графики рисовались Graphite, по данным, собираемым Diamond.