О Кассандре
2013-11-10
На HighLoad++ я проиллюстрировал Кассандру портретом Зекоры.

С тех пор мое отношение к ним не изменилось :) И теперь есть пони про NoSQL ;)
Да. Мы используем Кассандру. Которая Apache Cassandra.
Каждый знает, что модель данных в Кассандре, это BigTable, или ColumnFamily или еще как-то. Нужно только помнить, что здесь таблица, это не совсем та, и даже совсем не та таблица, что в SQL. Здесь у каждой строки есть обязательный, уникальный и единственный ключ. В каком-то смысле это аналог первичного ключа в SQL. Только обязательный и уникальный. И не может быть составным. И не имеет явного имени. Ключ используется для шардинга. Строка — единица хранения, и именно строки распределяются между узлами кластера и реплицируются. Ключ используется для записи. Для любой операции записи нужен ключ строки и обязательно он (ну и имена и значения колонок, конечно).
Колонок в таблице может быть сколько угодно (реально, миллиарды). Схемы нет. Проблемы c null значениями в "лишних" колонках тоже нет. При желании, каждая строка может иметь абсолютно свой набор колонок. Для правильного использования Кассандры важно знать, что колонки у нее упорядочены по имени. В отличие от строк, которые упорядочены так, как при начальной конфигурации кластера было положено (а положено в 99% случаев в порядке хэшей значений ключа строки).
Собственно, тройка: ключ строки — имя колонки — значение, приводит нас к мартинфаулерскому определению BigTable как мапа мапов (ну или словаря словарей). Только в Кассандре были (и есть) еще супер-колонки, что приводит нас к мапу мапа мапов. А с появлением составных колонок появляется возможность изобразить мапы сколько угодной вложенности. И даже замапить произвольные объекты и даже документы. С нетерпением жду библиотеки, позволяющей сохранять JSON документы в Кассандру как это делает Монга...
Ко всем этим прелестям в виде семейств колонок, колонок, супер-колонок и вторичных индексов доступ осуществляется через бинарный RPC протокол Thrift. Обращаться можно к любому узлу кластера, он займется контролем ваших операций и будет пересылать данные с/на другие узлы кластера. Однако это может быть неэффективным, и даже может быть неприятным (если узел, к которому вы подключились, упадет). Поэтому настоятельно рекомендуется пользоваться Гектором (который брат Кассандры). Это такой умный клиент, который понимает, как располагаются данные в кластере Кассандры, а также мониторит доступность узлов кластера. В результате он передает запрос на правильные узлы, чтобы максимально быстро получить ответ.
Кроме Трифта есть еще CQL (я имею ввиду CQL 3.х). Внешне это язык запросов, обманчиво похожий на SQL. Только помните, что это не SQL. В условиях WHERE вы не можете использовать колонки, на которых нет индексов. Несколько условий в WHERE вы можете объединять только операцией AND, но не OR. UPDATE возможен только по первичному ключу (безо всяких WHERE)... Внутри же CQL коварным образом скрывает и преобразует структуру нашей BigTable, делая её чуть более похожей на реляционную модель. Однако лишая вас веселой возможности манипулировать миллионами колонок.

В общем, Кассандру надо
уметь готовить.
Например,
нам понадобилось обновлять некую группу значений
(закодированных в JSON, черт, антипаттерн)
из разных источников так,
чтобы победил сильнейший последний,
кто внес изменения.
Если бы время изменений определялось временем прихода их в Кассандру,
не было бы проблемы.
Просто перезаписываем значение и все,
а Кассандра уже сама внутри кластера разберется,
какое значение последнее.
Но наши источники любят менять данные самостоятельно,
по различным печальным причинам сообщая об этом Кассандре позднее.
Т.е. разрешать конфликты нужно по таймстампу изменения,
присланному вместе с данными.
В SQL можно было бы воспользоваться транзакциями
и сделать read-modify-write:
прочитать таймстамп из базы,
убедиться, что пришедшие данные новее
и записать их.
Но в Кассандре нет транзакций
(по крайней мере до версии 2.0)
и пока вы будете читать да думать,
кто-то другой уже перезапишет ваши данные.
В SQL можно было бы сделать и еще проще,
что-то вроде условного апдейта:
UPDATE table
SET data = new_data, timestamp = new_timestamp
WHERE id = id_data AND new_timestamp > timestamp
Но в Кассандре нельзя делать WHERE на UPDATE. В Монге можно было бы воспользоваться операцией findAndModify (которая во многом аналогична приведенному выше апдейту). Но в Кассандре нет findAndModify.
Что можно делать в Кассандре?
Создавать столбцы и хранить все изменения.
Собственно, упорядоченные столбцы,
это очень даже естественный (для Кассандры)
способ хранить time-series data.
Ну т.е. берем и на каждый апдейт создаем новый столбец,
чье имя содержит значение таймстампа.
Получаем кучу столбцов вида: data:timestamp1, data:timestamp2...
При чтении выбираем наибольший столбец и вуаля.
Однако тут возникает еще одна
неприятная особенность Кассандры.
Если мы хотим выбрать только определенные столбцы,
то мы либо должны явно перечислить их имена
(единственный способ, доступный в SQL),
либо задать начальное имя столбца
и количество столбцов в выборке
(или же конечное значение имени столбца).
Но вот нельзя выбрать и по именам, и по диапазону.
В наших же данных,
кроме чудесного столбца data с таймстампом,
было еще и несколько обычных столбцов.
Примерно так:
columnA, columnB, data:timestamp1, data:timestamp2
Конечно,
можно выбирать все колонки
и выбирать данные с последним таймстампом на клиенте.
Но очень не хотелось гонять лишние данные по сети.
Поэтому мы применили грязный хак военную хитрость.
Помните, что колонки отсортированы?
А количество "обычных" колонок — известно.
А из таймстампов нужен наибольший.
Так давайте назовем колонки так,
чтобы они выстроились в нужном порядке:
_data:timestamp1, _data:timestamp2, columnA, columnB
А теперь выбираем нужное количество колонок (в данном примере — три), в обратном порядке (т.е. начиная с конца). И получаем только те данные, что нужно.
Столько мучений. Зачем же использовать Кассандру?
Ну вот, например, зачем. У нас все выглядит примерно так:
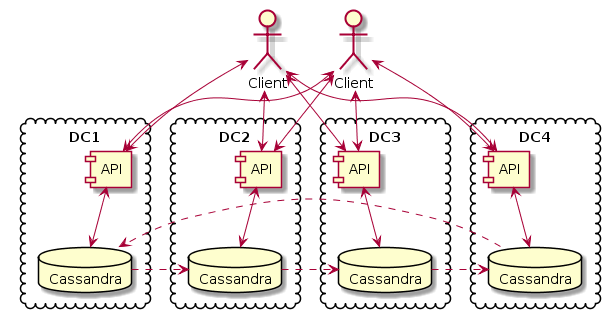
Кассандра размазана между четырьмя датацентрами. Данные реплицированы тоже четыре раза, т.е. в каждом датацентре есть своя копия. В каждом датацентре есть API, причем API без состояния, все запросы отражаются в Кассандре. А вот клиенты выбирают API для запросов в случайном порядке. Нет привязки клиентов или датацентров по каким-либо признакам вроде географического расположения. И получается совершенно честный мультимастер. Реликация и контроль целостности полностью обеспечиваются Кассандрой. Я не знаю, как такое сделать с каким-либо SQL или даже с Монгой (где имеются выделенные мастеры, принимающие все запросы записи).
Кассандра легко разворачивается, довольно быстра, надежна и практична. Пользуйтесь.